Introdução
O modelo de regressão linear simples é um dos modelos mais simples de Statistical Learning / Econometria. O modelo assume que a relação entre as variáveis \(Y\) e \(X\) é dada por: \[\begin{equation}\label{RLS} Y = \beta_0 + \beta_1 X + u \end{equation}\] em que \(\beta_0\) e \(\beta_1\) são os parâmetros do modelo e \(u\) é um termo aleatório.
Se conhecermos \(\beta_0\) e \(\beta_1\), basta utilizar o modelo para um determinado valor de \(X\), digamos \(x\), e saberemos o valor esperado de \(Y\) dado \(x\)1.
Infelizmente, nunca conhecemos \(\beta_0\) e \(\beta_1\) e então precisamos estimar esses valores utilizando os dados da nossa amostra.
Existem vários métodos de estimação, mas hoje discutiremos o estimador de mínimos quadrados ordinários (MQO).
A intuição por trás do estimador MQO
Sejam \((y_1, x_1), \ldots, (y_n, x_n)\) os elementos de uma amostra aleaatória (a.a) de tamanho \(n\) extraida de \((Y,X)\). Estamos interessados em estimar os parâmetros \(\beta_0\) e \(\beta_1\) na reta de regressão, mas…qual reta escolher?
A Figura 1 apresenta o gráfico de dispersão de educação (\(x\)) vs. renda (\(y\)). Como podemos ver, existem várias retas (na verdade existem infinitas retas) que podemos tracejar na nossa tentativa de estimar \(\beta_0\) e \(\beta_1\).
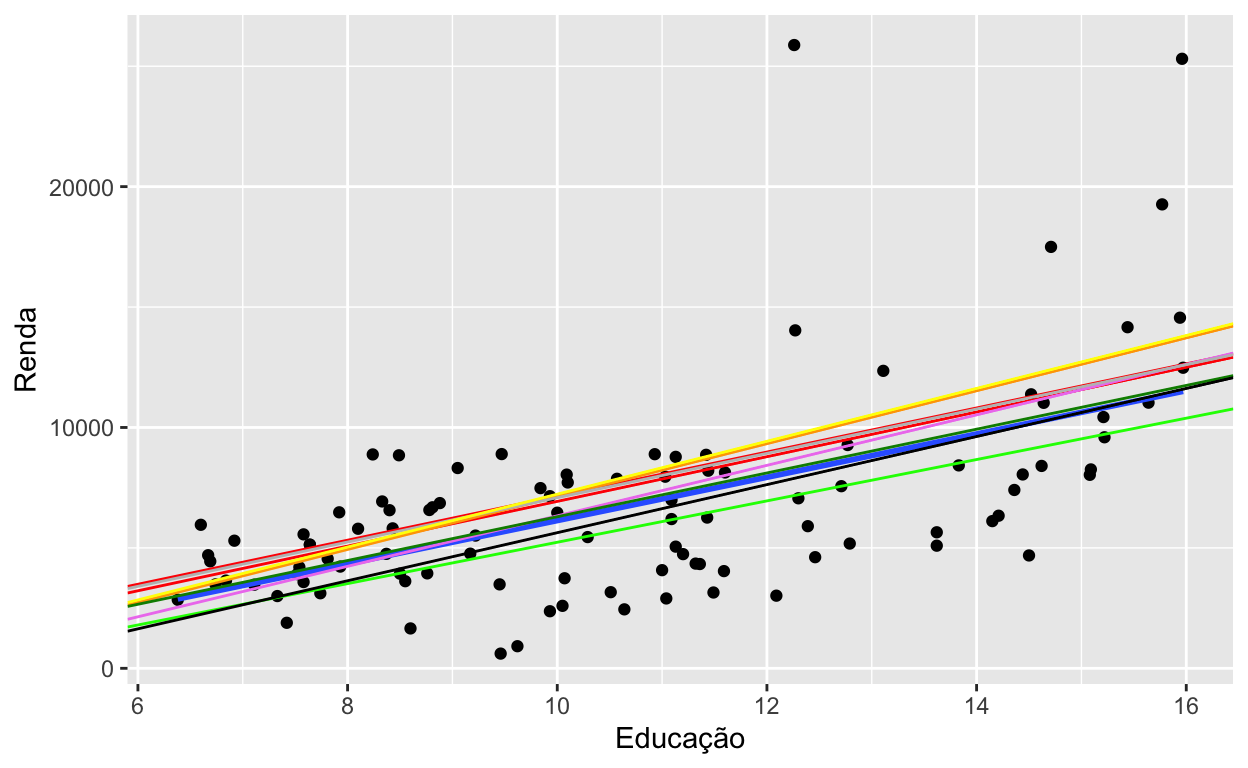
Figure 1: Gráfico de dispersão education vs. income
Entre os vários critérios que poderíamos escolher para escolher a reta, vamos escolher a reta que minimiza a soma de quadrados dos resíduos. Mas… quem são esses resíduos? os resíduos, denotados por \(\hat{u}_i\), são definidos como \(\hat{u}_i = y_i - \hat{y_i}\) com \(\hat{y}_i = b_0 + b_1x_i\). Ou seja, independente dos valores \(b_0\) e \(b_1\) que escolhermos, os resíduos são a diferença entre o valor verdadeiro (\(y_i\)) e o estimado (\(\hat{y}_i\)).
Os valores \(b_0\) e \(b_1\) que minimizem a SQR vamos denotá-los como \(\hat{\beta}_0\) e \(\hat{\beta}_1\). Em termos matemáticos, queremos \(b_0\) e \(b_1\) tal que \[\hat{\beta}_0, \hat{\beta}_1 = \mathop{\mathrm{argmin}}\limits_{b_0, b_1} SQR\] em que \[SQR := \displaystyle \sum_{i=1}^n \hat{u}_i^2 \equiv \displaystyle \sum_{i=1}^n (y_i - \hat{y}_i)^2 \equiv \displaystyle \sum_{i=1}^n (y_i - b_0 - b_1 x_i)^2\]
Derivando o estimador MQO
Nosso problema de encontrar \(\hat{\beta}_0\) e \(\hat{\beta}_1\) resume-se, então, a um problema de minimização, onde a função a minimizar é \[SQR := \displaystyle \sum_{i=1}^n (\underbrace{y_i - b_0 - b_1 x_i}_{\hat{u}_i})^2\]
Para resolver nosso problema de minimização vamos a lembrar um pouco das aulas de cálculo. Vamos a calcular a primeira derivada, igualar a zero para obter os valores candidatos e finalmente, vamos a calcular a segunda derivada para verificar que efetivamente os valores encontrados são valores que minimizam a função.
Primeira derivada
Derivando SQR em relação a \(b_0\) temos
\[\begin{equation} \dfrac{\partial SQR}{\partial b_0} = -2 \displaystyle \sum_{i=1}^n (y_i - b_0 - b_1 x_i) = -2 n \big( \bar{y} - b_0 - b_1 \bar{x} \big). \end{equation}\]
Derivando SQR em relação a \(b_1\) temos
\[\begin{equation} \dfrac{\partial SQR}{\partial b_1}= -2 \displaystyle \sum_{i=1}^n x_i (y_i - b_0 - b_1 x_i) = -2 \Big( \displaystyle \sum_{i=1}^n x_i y_i - b_0 \displaystyle \sum_{i=1}^n x_i - b_1 \displaystyle \sum_{i=1}^n x_i^2 \Big). \end{equation}\]
Igualando a zero
Fazendo \(\frac{\partial SQR}{\partial b_0} = 0\) e \(\frac{\partial SQR}{\partial b_1} = 0\) temos:
\[\underbrace{\bar{y} = \hat{\beta}_0 + \hat{\beta}_1 \bar{x}}_{A} \quad e \quad \underbrace{\displaystyle \sum_{i=1}^n x_i (y_i - \hat{\beta}_0 - \hat{\beta}_1 x_i) = 0}_{B}\]Vamos então resolver o sistema de equações para obter \(\hat{\beta}_0\) e \(\hat{\beta}_1\).
De \(A\) temos que \(\hat{\beta}_0 = \bar{y} - \hat{\beta}_1 \bar{x}\). Agora vamos substituir \(\hat{\beta}_0\) em \(B\),
\[\displaystyle \sum_{i=1}^n x_i (y_i - \underbrace{(\bar{y} - \hat{\beta}_1 \bar{x})}_{\hat{\beta}_0} - \hat{\beta}_1 x_i) = 0\] \[\displaystyle \sum_{i=1}^n x_i(y_i-\bar{y}) - \hat{\beta}_1 \sum_{i=1}^n x_i (x_i - \bar{x}) = 0\]
\[\displaystyle \sum_{i=1}^n x_i(y_i-\bar{y}) = \hat{\beta}_1 \sum_{i=1}^n x_i (x_i - \bar{x}),\] Então, \[\hat{\beta}_1 = \dfrac{\displaystyle \sum_{i=1}^n x_i(y_i-\bar{y})}{\displaystyle \sum_{i=1}^n x_i (x_i - \bar{x})}.\] Provavelmente, a fórmula não se parece muito com as fórmulas que você está acostumado a ver nos livros. Vamos trabalhar um pouco com as expressões no numerador e denominador para chegarmos a uma fórmula um pouco mais conhecida.
No denominador:
\[\displaystyle \sum_{i=1}^n x_i (x_i-\bar{x}) = \sum_{i=1}^n (x_i - \bar{x} + \bar{x})(x_i-\bar{x}) = \underbrace{\sum_{i=1}^n (x_i - \bar{x})(x_i-\bar{x})}_{\displaystyle \sum_{i=1}^n (x_i - \bar{x})^2} + \underbrace{\sum_{i=1}^n \bar{x}(x_i-\bar{x})}_{\bar{x} \displaystyle \sum_{i=1}^n (x_i-\bar{x})},\] e como \(\displaystyle \sum_{i=1}^n (x_i - \bar{x}) = \underbrace{\sum_{i=1}^n x_i}_{n\bar{x}} - n \bar{x} = 0,\) temos que \[\displaystyle \sum_{i=1}^n x_i (x_i-\bar{x}) = \displaystyle \sum_{i=1}^n (x_i-\bar{x})^2.\] No numerador:
\[\displaystyle \sum_{i=1}^n x_i(y_i-\bar{y}) = \displaystyle \sum_{i=1}^n (x_i - \bar{x} + \bar{x})(y_i-\bar{y}) = \displaystyle \sum_{i=1}^n (x_i - \bar{x})(y_i-\bar{y}) + \underbrace{\displaystyle \sum_{i=1}^n \bar{x}(y_i-\bar{y})}_{\bar{x} \underbrace{\displaystyle \sum_{i=1}^n (y_i-\bar{y})}_{0}}\] Então temos que, \[\hat{\beta}_1 = \dfrac{\displaystyle \sum_{i=1}^n (x_i - \bar{x})(y_i-\bar{y})}{\displaystyle \sum_{i=1}^n (x_i-\bar{x})^2} \quad e \quad \hat{\beta}_0 = \bar{y} - \hat{\beta}_1 \bar{x}.\]
Verificando que é ponto de mínimo
Para verificar que a solução obtida é ponto de mínimo, precisamos que a matriz Hessiana \[\begin{bmatrix} \dfrac{\partial^2 SQR}{\partial b_0^2} & \dfrac{\partial^2 SQR}{\partial b_0 \partial b_1} \\ \dfrac{\partial^2 SQR}{\partial b_1 \partial b_0} & \dfrac{\partial^2 SQR}{\partial b_1^2} \\ \end{bmatrix}\] seja definida positiva.
- \(\dfrac{\partial^2 SQR}{\partial b_0^2} = \dfrac{\partial}{\partial b_0}\dfrac{\partial SQR}{\partial b_0} = 2n\)
- \(\dfrac{\partial^2 SQR}{\partial b_0 \partial b_1} = \dfrac{\partial}{\partial b_0}\dfrac{\partial SQR}{\partial b_1} = 2n \bar{x}\)
- \(\dfrac{\partial^2 SQR}{\partial b_1 \partial b_0} = \dfrac{\partial}{\partial b_1}\dfrac{\partial SQR}{\partial b_0} = 2n \bar{x}\)
- \(\dfrac{\partial^2 SQR}{\partial b_1^2} = \dfrac{\partial}{\partial b_1}\dfrac{\partial SQR}{\partial b_1} = 2 \displaystyle \sum_{i=1}^n x_i^2\)
Logo, a matriz Hessiana \[\begin{bmatrix} 2n & 2n \bar{x} \\ 2n \bar{x} & 2 \displaystyle \sum_{i=1}^n x_i^2 \\ \end{bmatrix},\] é definida positiva pois os elementos da diagonal são positivos e o determinante \(4n\displaystyle \sum_{i=1}^n x_i^2 - 4n^2\bar{x}^2 = 4n \Big( \sum_{i=1}^n x_i^2 - n\bar{x}^2\Big) = 4n \displaystyle \sum_{i=1}^n(x_i - \bar{x})^2\) é também positivo.
Estimador MQO
Assim, temos mostrado que os estimadores MQO para \(\beta_0\) e \(\beta_1\) no modelo de regressão linear simples são \[\hat{\beta}_1 = \dfrac{\displaystyle \sum_{i=1}^n (x_i - \bar{x})(y_i-\bar{y})}{\displaystyle \sum_{i=1}^n (x_i-\bar{x})^2} \quad e \quad \hat{\beta}_0 = \bar{y} - \hat{\beta}_1 \bar{x}.\]
Conclusões
- O estimador MQO consiste em encontrar \(\hat{\beta}_0\) e \(\hat{\beta}_1\) que minimizm a soma de quadrados dos resíduos.
- Utilizando os critérios da primeira e segunda derivada temos obtido os estimadore MQO.
- Sob algumas hipóteses, os estimadores MQO são o melhor estimador linear não viesado ver Teorem de Gauss-Markov
- Se quiser saber como implementar este modelo em R e Python pode ver este post.
Assumindo que \(\mathbb{E}(u|X) = 0\), \(\mathbb{E}(Y|x) = \beta_0 + \beta_1 x\)↩︎