Condicionado nas covariáveis e no fato de sabermos que em cada par temos um tratamento e um controle, temos um MPE!. Ou seja, podemos analisar match perfeitos em estudos observacionais como se fossem um MPE!
Matching
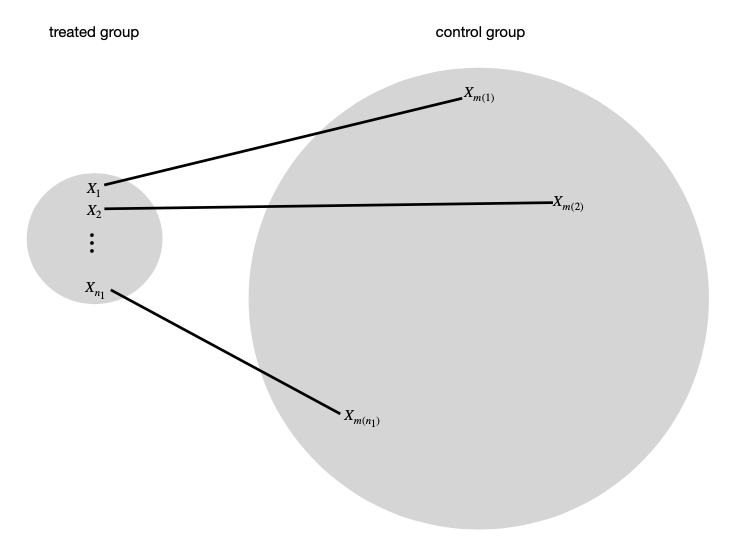
E se encontrarmos \(M_i\) unidades no grupo de controle que fazem match perfeito com a unidade \(i\) no grupo de tratamento?
Quando os \(M_i\)s variam, o procedimento é chamado variable-ratio matching e pode ser analisado utilizando uma modificação do MPE, a qual apresentamos brevemente a seguir.
Matching
EMPE
Suponha que temos \(n\)matches (\(i = 1, \cdots, n\)).
Para cada \(i\) temos \(1 + M_i\) unidades (1 referente ao tratamento e \(M_i\) referente ao controle).
Assim, o número total de unidades experimentais é \(N = n + \displaystyle \sum_{i = 1}^n M_i.\)
Seja o index\(ij\) que representa a unidade \(j\) no conjunto \(i\) (\(i = 1, \cdots, n\), \(j = 1, \cdots, M_i + 1\)) com indicadora de tratamento \(Z_{ij}\) e resultados potenciais \(Y_{ij}(1)\) e \(Y_{ij}(0).\)
Dentro de cada conjunto \(i\), o pesquisador seleciona uma unidade aleatoriamente para atribuir o tratamento.
Infelizmente não sempre temos match perfeito (\(X_i = X_{m(i)}\)), trazendo consequências negativas ao utilizar MPE ou EMPE em estudos observacionais no contexto de FRT (Guo e Rothenhausler (2023)).
\(X_i \approx X_{m(i)}\)
\(X_i \approx X_{m(i)}\)
Mesmo se o grupo de controle for grande, pode ser o caso de não termos match perfeito mas sim \(X_i \approx X_{m(i)}\).
Seja \[m(i) = \arg \min_{k:Z_k = 0} d(X_i, X_k),\] em que \(d(X_i, X_k)\) é uma medida de distância entre \(X_i\) e \(X_k\) (tipicamente distância Euclideana ou de Mahalanobis)
Observação: Daqui em diante, considerarmos matching com reposição. Ou seja, uma mesma unidade pode ser utilizada mais do que uma vez.
Estimação pontual e correção do vies
Para cada \(i\) consideremos \[\hat{Y}_i(1) = Y_i \quad e \quad \hat{Y}_i(0) = M^{-1} \sum_{k \in J_i} Y_k,\] em que \(J_i\) é o conjunto de unidades no grupo de controle que fazen match com a unidade de tratamento \(i\).
Por exemplo, podemos calcular \(d(X_i, X_k)\)\(\forall k\) no grupo de controle e definir \(J_i\) como os índices de \(k\) com os menores \(M\) valores de \(d(X_i, X_k)\).
Estimação pontual e correção do vies
O estimador matching é dado por \[\hat{\tau}^m = n^{-1} \displaystyle \sum_{i = 1}^n (\hat{Y}_i(1) - \hat{Y}_i(0)),\]
Abadei e Imbens mostram que este estimador é viesado e eles propoem o seguinte estimador para o vies
\[\hat{B} = n^{-1} \displaystyle \sum_{i = 1}^n \hat{B}_i,\] em que \(\hat{B}_i = (2Z_i - 1)M^{-1} \displaystyle \sum_{k \in J_i}[\hat{\mu}_{1 -Z_i}(X_i) - \hat{\mu}_{1 -Z_i}(X_k)]\) com \(\hat{\mu_1}(X_i)\) e \(\hat{\mu_0}(X_i)\) sendo os valores ajustados do outcome regression.
Estimação pontual e correção do vies
Assim, o estimador já corrigido pelo vies é dado por
\[\hat{\tau}^{mbc} = \hat{\tau}^m - \hat{B} \equiv n^{-1} \displaystyle \sum_{i = 1}^n\hat{\psi}_i,\] em que \(\hat{\psi}_i = \hat{\mu}_{1}(X_i) - \hat{\mu}_0(X_i) + (2Z_i - 1)(1 + K_i/M)[Y_i - \hat{\mu}_{Z_i}(X_i)]\) com \(K_i\) o número de vezes que a unidade \(i\) é utilizada como match.
Ademais, se fizermos \(\hat{\psi}_{T,i} = Z_i [Y_i - \hat{\mu}_0(X_i)] - (1 - Z_i)K_i/M[Y_i - \hat{\mu}_0(X_i)]\), podemos re-escrever o estimador como \[\hat{\tau}_T^{mbc} = n_1^{-1}\displaystyle \sum_{i = 1}^n \hat{\psi}_{T,i},\] o que motiva o estimador de variância dado por \[\hat{V}_T^{mbc} = \dfrac{1}{n_1^2} \displaystyle \sum_{i = 1}^n (\hat{\psi}_{T,i} - \hat{\tau}_T^{mbc})^2.\]
É possível mostrar que \(\hat{\tau}_T^{mdc} = \hat{\tau}_T^{Reg}-n_1^{-1} \displaystyle \sum_{i = 1}^n \dfrac{K_i}{M}(1 - Z_i)\hat{R}_i.\)
Exemplos
Exemplos
Estudo experimental vs. observacional
Lalonde (1986) está interessado no efeito causal de um programa de treinamento sob o salario. Ele compara os resultados utilizando dados experimentais (dataset lalonde do pacote Matching) vs. dados observacionais (cps1re74.csv).
Est SE
Neyman 1794.343 670.9967
Fisher 1676.343 677.0493
Lin 1621.584 694.7217
Exemplos
Lalonde: dados experimentais
Analisaremos os dados experimentais como se fossem observacionais e para isto, utilizaremos Matching
Code
matching_model <-Match(Y = y, Tr = z, X = x, BiasAdjust =TRUE)summary(matching_model)
Estimate... 2119.7
AI SE...... 876.42
T-stat..... 2.4185
p.val...... 0.015583
Original number of observations.............. 445
Original number of treated obs............... 185
Matched number of observations............... 185
Matched number of observations (unweighted). 268
Ambos, o valor estimado e seu desvio padrão aumentaram. Contudo, qualitativamente as conclusões são as mesmas.
Exemplos
Lalonde: dados observacionais
Code
data <-read.csv("datasets/cps1re74.csv", sep =" ")y <- data$re78z <- data$treatx <-as.matrix(data[, c("age", "educ", "black", "hispan", "married", "nodegree", "re74", "re75")])# Analisamos os dados como se fossem dados experimentaisneyman_ols <-lm(y ~ z)fisher_ols <-lm(y ~ z + x) # ANCOVAx_c <-scale(x)lin_ols <-lm(y ~ z*x_c)out <-c(neyman_ols$coef[2], fisher_ols$coef[2], lin_ols$coef[2],sqrt(hccm(neyman_ols, type ="hc2")[2, 2]),sqrt(hccm(fisher_ols, type ="hc2")[2, 2]),sqrt(hccm(lin_ols, type ="hc2")[2, 2]))out <-matrix(out, nrow =3, ncol =2)colnames(out) <-c("Est", "SE")rownames(out) <-c("Neyman", "Fisher", "Lin")out
Est SE
Neyman -8506.495 583.4426
Fisher 704.697 618.2429
Lin -3689.852 2987.1832
Exemplos
Lalonde: dados observacionais
Agora utilizaremos um método próprio para dados observacionais.
Code
matching_model <-Match(Y = y, Tr = z, X = x, BiasAdjust =TRUE)summary(matching_model)
Estimate... 2182.4
AI SE...... 869.39
T-stat..... 2.5103
p.val...... 0.012064
Original number of observations.............. 16177
Original number of treated obs............... 185
Matched number of observations............... 185
Matched number of observations (unweighted). 227
As conclusões obtidas ao analisarmos os dados observacionais com método apropriados são as mesmas obtidas quando analisamos dados experimentais.
Observação
Quando \(X\) tem dimensão grande, matching sofre com a maldição da dimensionalidade.
Uma alternativa é realizar o matching baseado no propensity score.
desenvolvem toda a teoria que justifica esta alternativa.
Referências
Peng Ding (2023). A First Course in Causal Inference. Capítulo 15.

 desenvolvem toda a teoria que justifica esta alternativa.
desenvolvem toda a teoria que justifica esta alternativa.