Inferência Causal
Introdução
Introdução
Introdução
Introdução
Introdução
Introdução


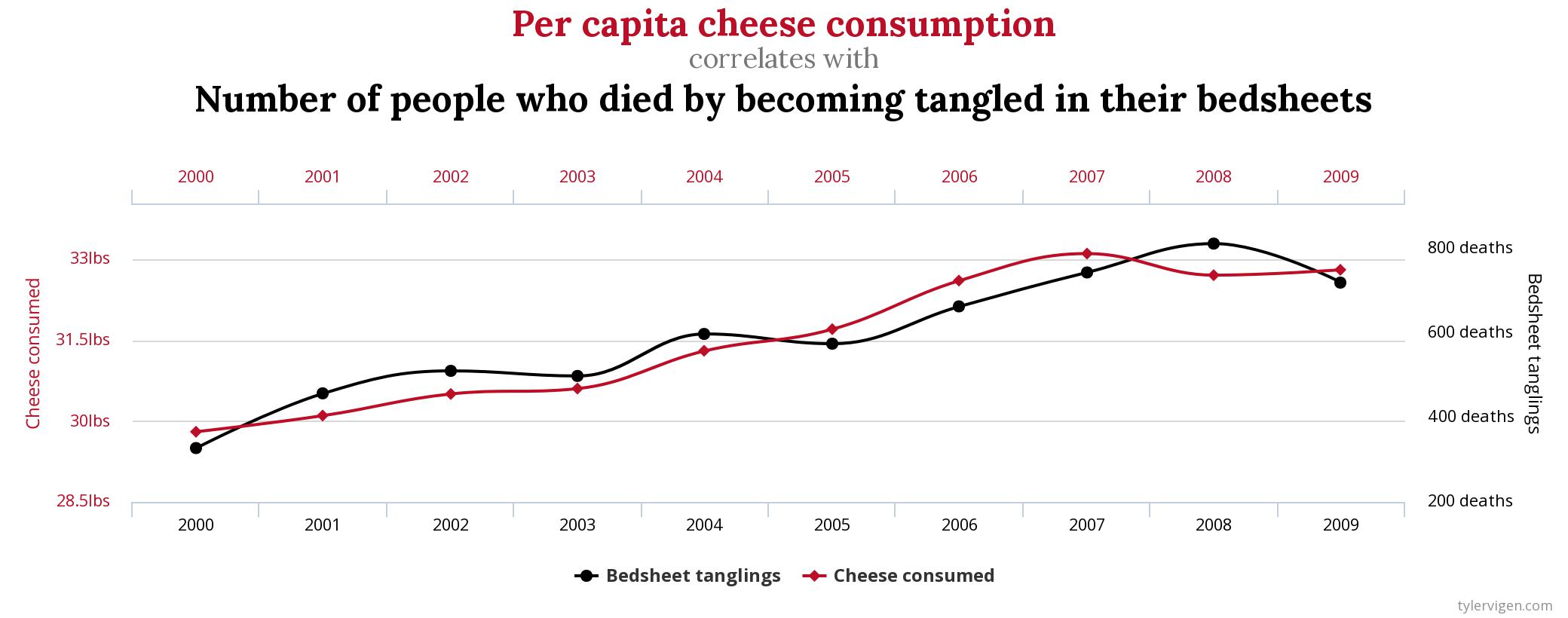
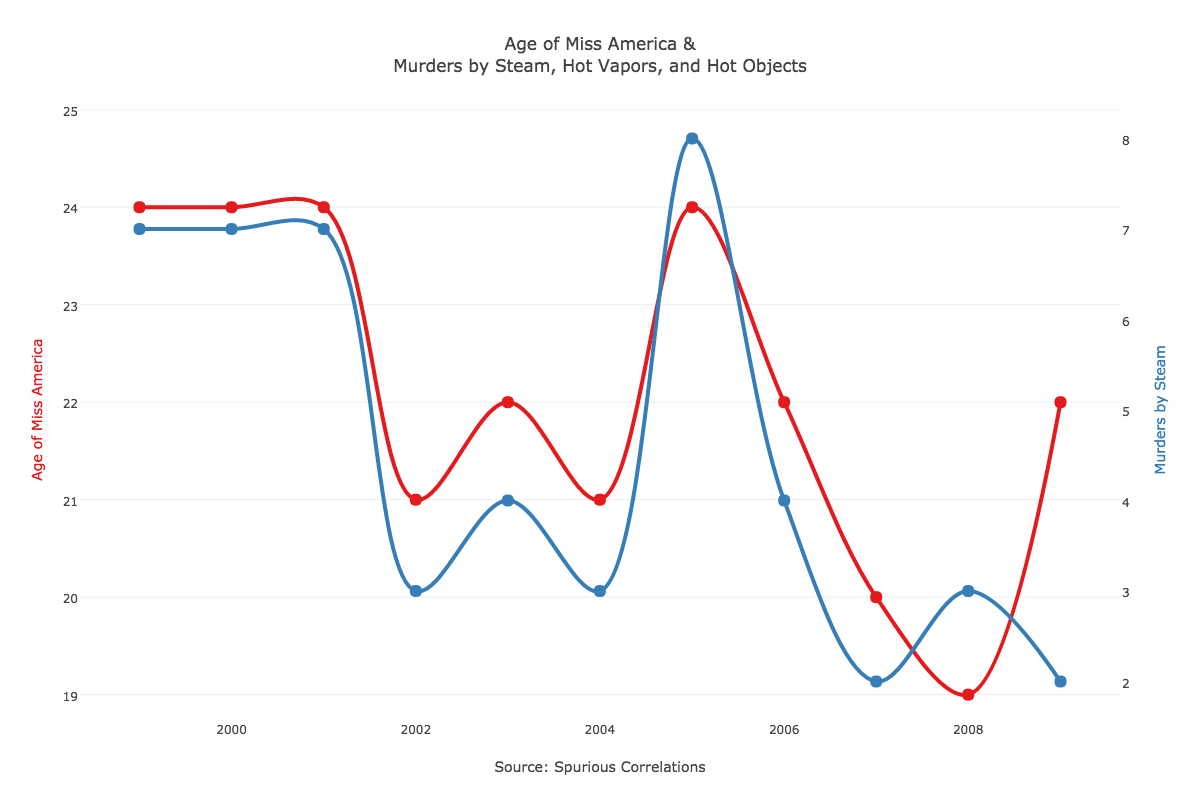
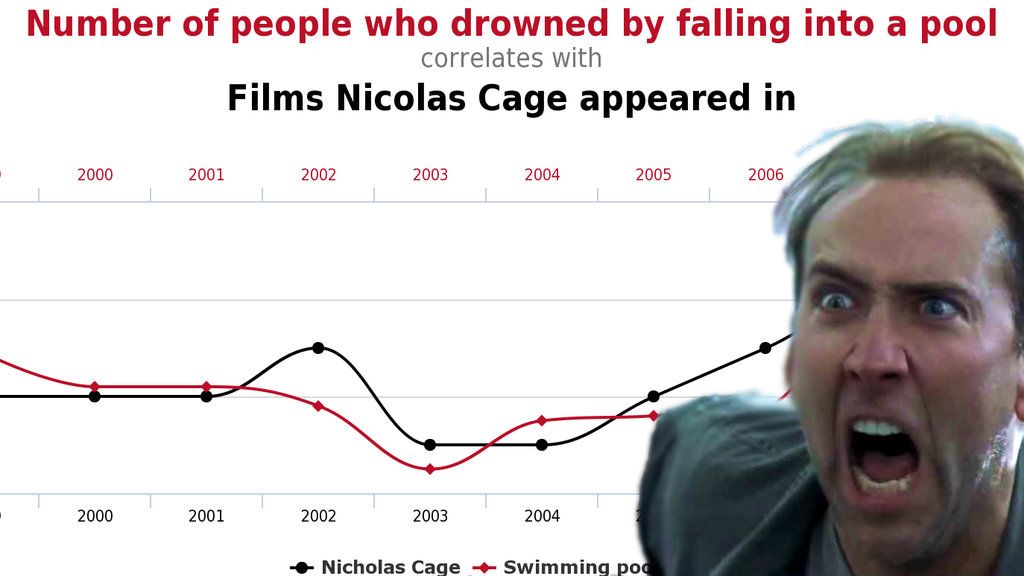
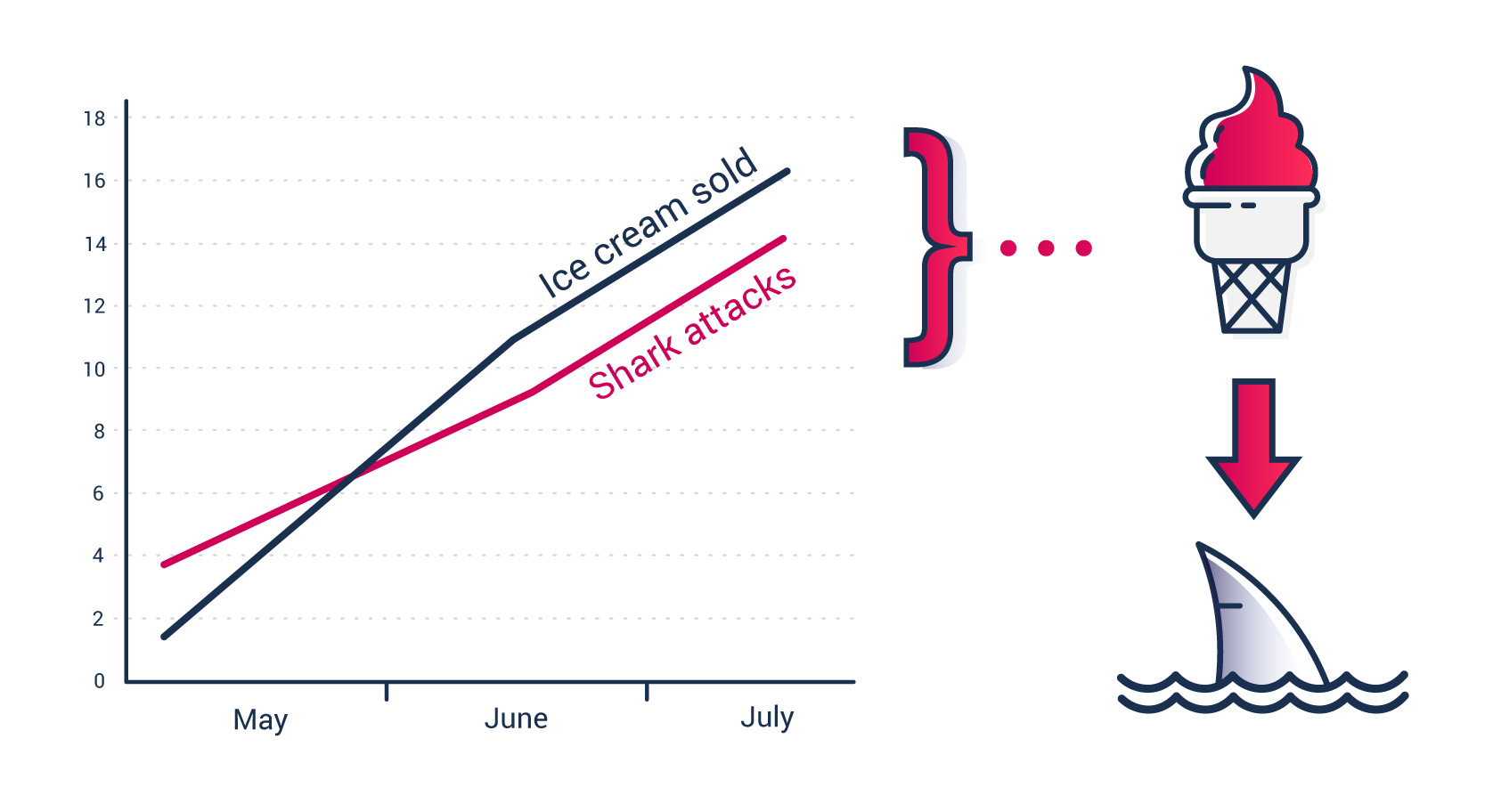
Correlação e causalidade podem co-existir, mas correlação não implica (necesariamente) causalidade.
Introdução
Algumas vezes, correlação pode implicar causalidade, mas outras….
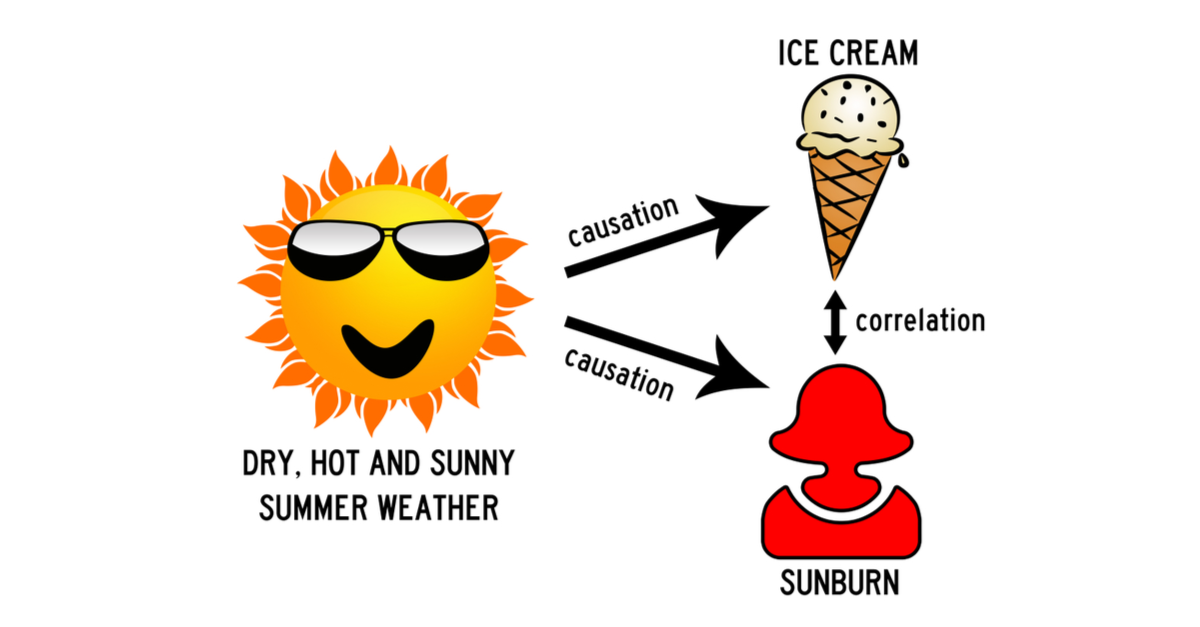
O que é Inferência Causal?

- “Causal inference is the process of learning what would happen to the average outcome of a population if we were to introduce a change in the interventions that people actually receive.” Hernán, M. A., & Robins, J. M. (2020) - “Causal Inference: What If”
- “Causal inference is the process of going beyond the observed data and proposing explanations for events that are suspected to have been caused by active interventions that modify the course of natural events.” Pearl, J. (2009) - “Causality: Models, Reasoning, and Inference”
O que é Inferência Causal?
- “Causal inference is the process of drawing conclusions about the effect of one variable by manipulating another variable, either through experimental or statistical observation.” Morgan, S. L., & Winship, C. (2014) - “Counterfactuals and Causal Inference: Methods and Principles for Social Research”
- “Causal inference is the process of making claims about the causal effects of treatments, interventions, or exposures, based on observational or experimental data.” Rubin, D. B. (2005) - “Causal Inference Using Potential Outcomes: Design, Modeling, Decisions”
O que é Inferência Causal?
- “Causal inference is the process of learning about the effects of interventions, policies, or treatments, using observational or experimental data and appropriate statistical methods.” Imbens, G. W., & Rubin, D. B. (2015) - “Causal Inference for Statistics, Social, and Biomedical Sciences”
- “Causal inference is the attempt to draw conclusions about ‘what would have happened’ if a variable of interest had been different in an experimental group, compared to a control group, while holding other variables constant.” Angrist, J. D., & Pischke, J. S. (2008) - “Mostly Harmless Econometrics: An Empiricist’s Companion”
Paradoxo de Simpson

Paradoxo de Yule-Simpson
Exemplo 2
Considere um estudo que mede a quantidade média de exercícios diário (em minutos) e o nível de colesterol LDL (mg/dL). Baseado no seguinte gráfico de dispersão, quais seriam suas conclusões?
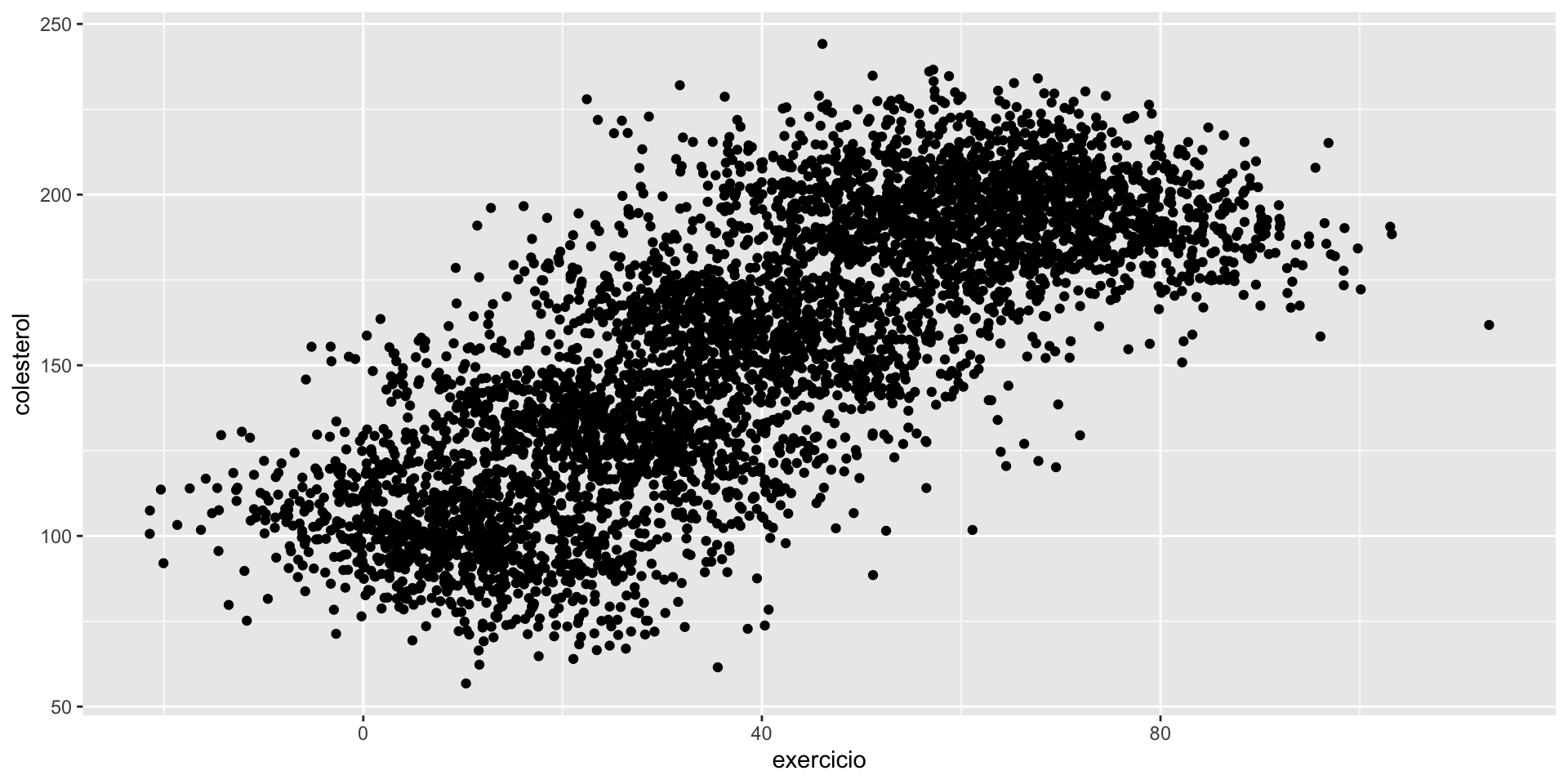
Paradoxo de Yule-Simpson
Exemplo 2
Você, incomodado com o resultado contraintuitivo, revolve incluir a variável grupo, obtendo o seguinte resultado
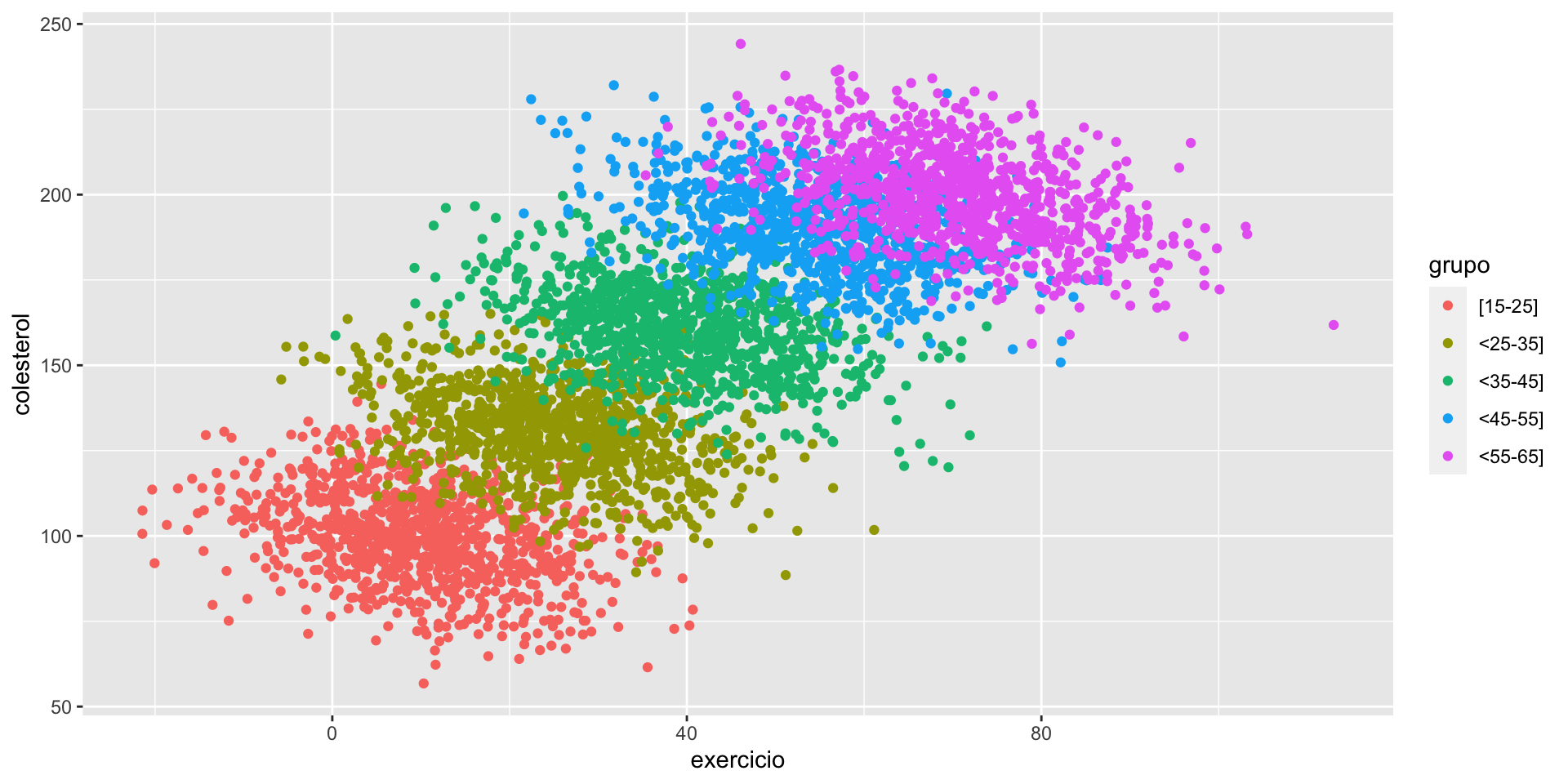
Suas conclusões permaneceriam as mesmas?
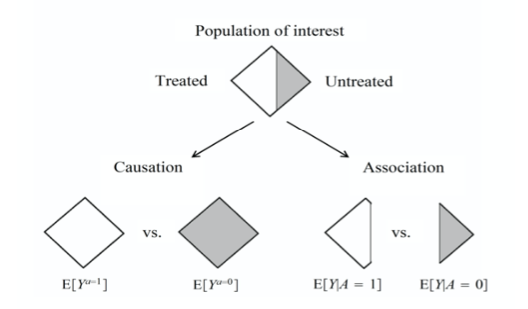
Causalidade ou associação
Referências
- Peng Ding (2023). A First Course in Causal Inference. Capítulo 1.
- Peng Ding (2023). A First Course in Causal Inference. Capítulo 2.
- Hernán, Miguel A. e Robins, James, M. (2023). Causal Inference: What if?. Captítulo 1.
- Rubin, D. B. (2005). Causal inference using potential outcomes: Design, modeling, decisions. Journal of the American Statistical Association, 100(469), 322-331. [Leitura recomendada]
