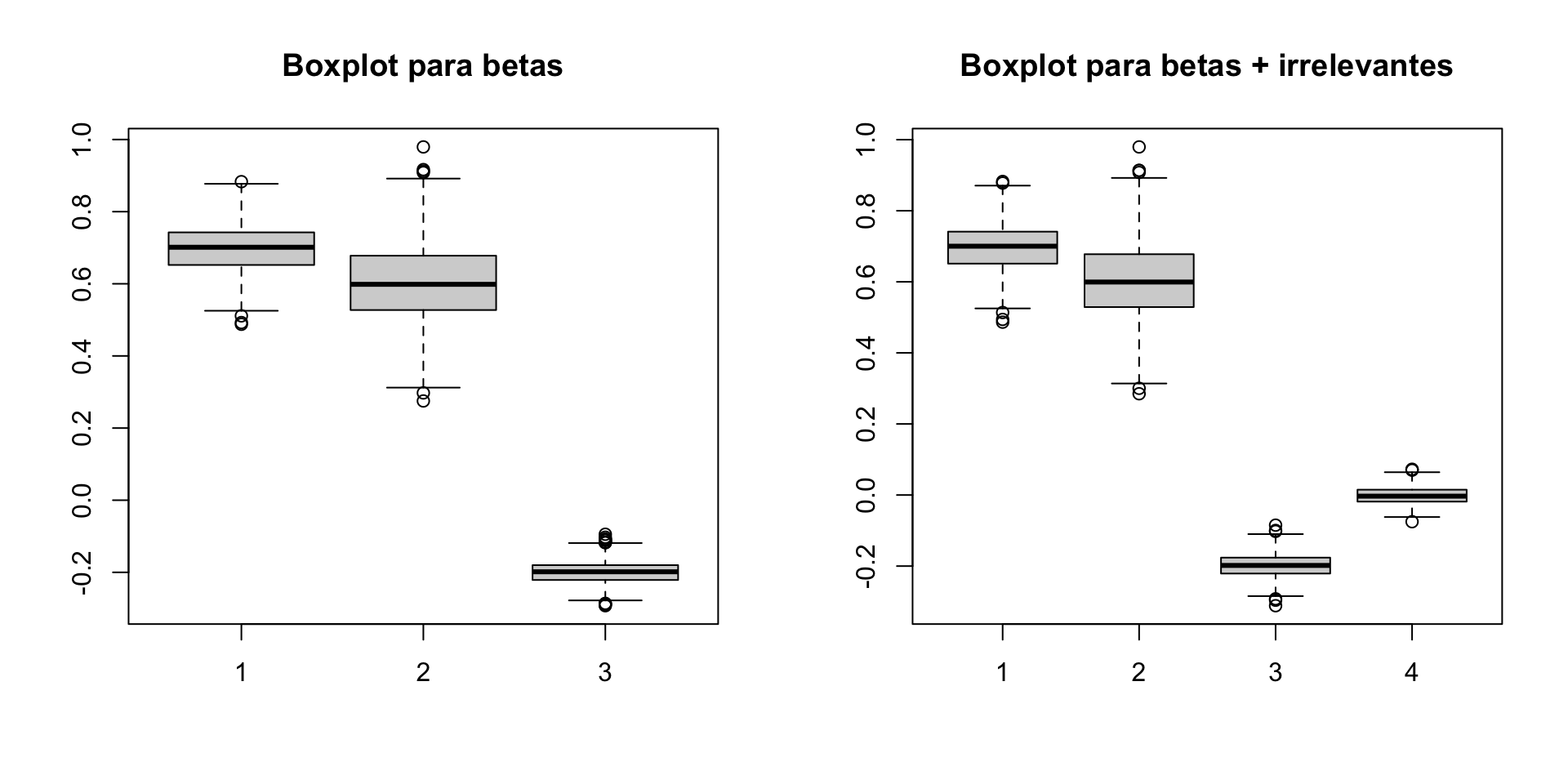
Incluir uma ou mais variáveis irrelevantes no modelo não afeta a inexistência de viés dos EMQO
Isso significa que podemos incluir tantas variáveis quanto quisermos sem nenhuma “punição”?
Variáveis irrelevantes no modelo de regressão
Incluir uma ou mais variáveis irrelevantes no modelo não afeta a inexistência de viés dos EMQO.Contudo, incluir variáveis irrelevantes tem efeitos indesejáveis sobre as variâncias dos EMQO (ver multicolinearidade).
Variáveis irrelevantes no modelo de regressão
Code
library(MASS)n <-1000betas <-matrix(NA, ncol =3, nrow =1000)betas_i <-matrix(NA, ncol =4, nrow =1000)for (i in1:1000) { u <-rnorm(n) x1 <-runif(n) x <-mvrnorm(n, mu =c(0,0), Sigma =matrix(c(1, 0.5, 0.5, 2), 2, 2)) x2 <- x[,1] x3 <- x[,2] y <-0.7+0.6*x1 -0.2*x2 + u betas[i, ] <-coef(lm(y ~ x1 + x2)) betas_i[i, ] <-coef(lm(y ~ x1 + x2 + x3))}par(mfrow =c(1, 2))boxplot(betas)title("Boxplot para betas")boxplot(betas_i)title("Boxplot para betas + irrelevantes")
Variáveis irrelevantes no modelo de regressão
Teorema FWL (Frisch-Waugh-Lovell)
Sejam os modelos \[Y = \textbf{X}_1\beta_1 + \textbf{X}_2 \beta_2 + u \quad e \quad M_1Y = M_1 \textbf{X}_2 \beta_2 + \nu,\] em que \(M_1 = \textbf{I}- X_1(X_1'X_1)^{-1}X_1'\)
\(\hat{\beta_2}\) em ambas as regressões é numericamente idêntico.
\(\hat{u}\) e \(\hat{\nu}\) são numericamente idênticos.
Provar que \(\mathbb{V}(\hat{\delta}|X,Z) \geq \mathbb{V}(\hat{\beta}|X)\) é equivalente a provar que \(\mathbb{V}(\hat{\beta}|X)^{-1} \geq \mathbb{V}(\hat{\delta}|X,Z)^{-1}\)
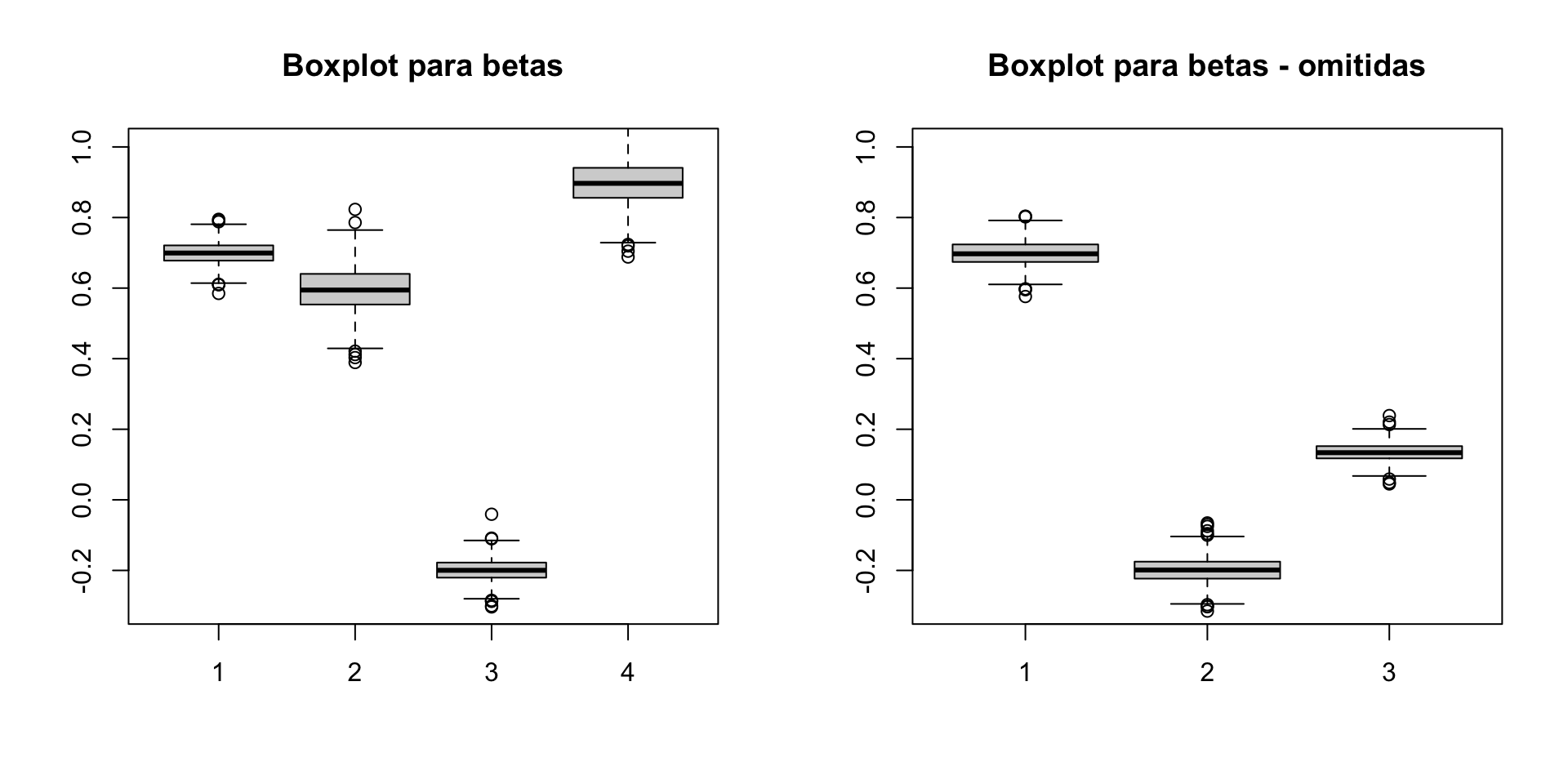
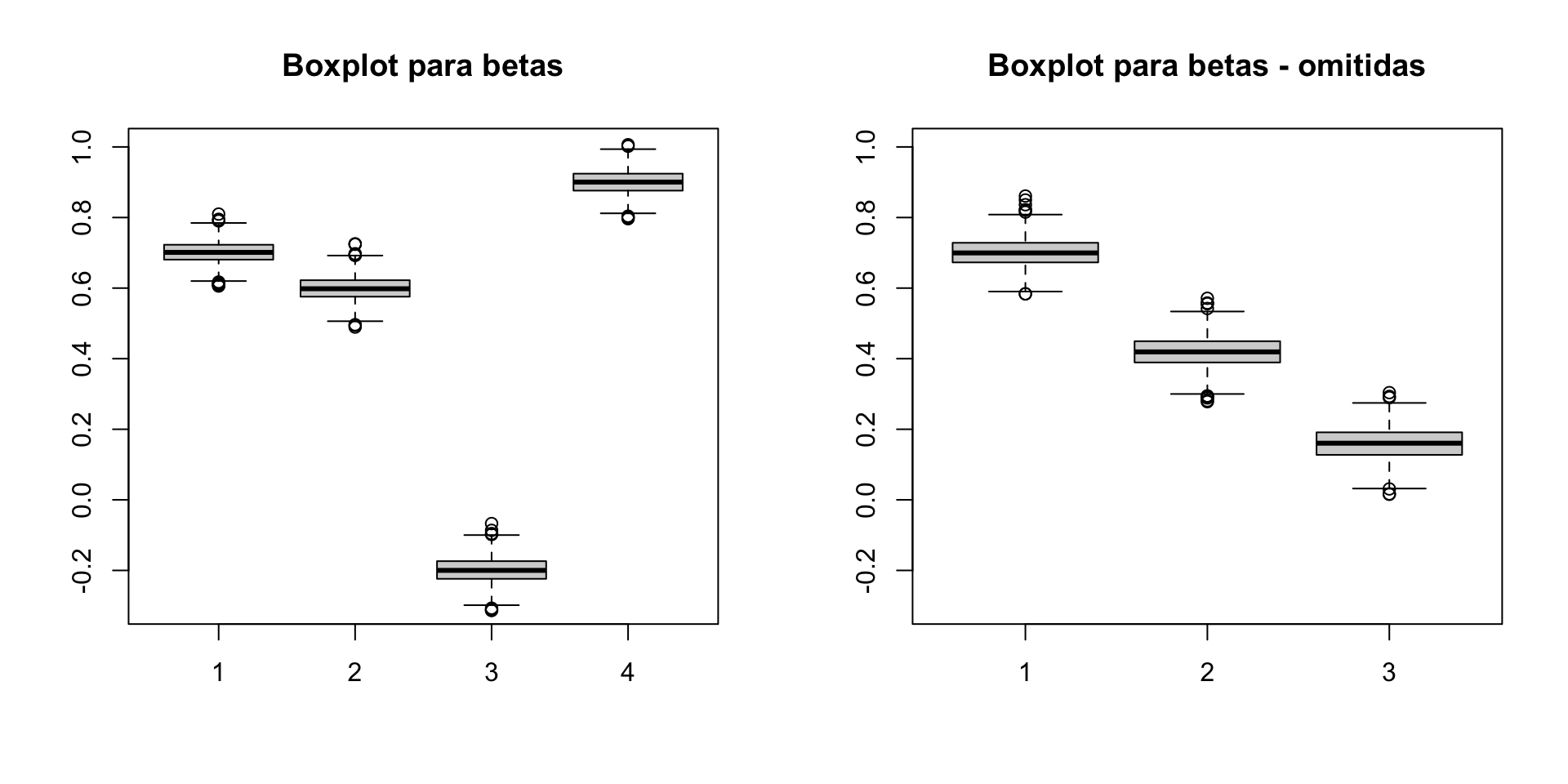
Suponha que \(X_2\) e \(X_3\) sejam não correlacionados mas que \(X_1\) e \(X_3\) sejam correlacionados.
É tentador pensar que como \(X_3\) não está correlacionada com \(X_2\), \(\tilde{\beta}_2\) será não viesado, mas não é isso que acontece.
O único caso em que isso acontece é se \(X_1\) e \(X_2\) também forem não correlacionados.
Muitas vezes é dificil determinar o sinal do viés, mas o importante aqui é saber que resultados contraintuitivos podem ser fruto de estimadores viesados.
Variáveis omitidas
Sejam \(\textbf{X} = [\textbf{X}_1 \textbf{X}_2]\) e \(\beta = [\beta_1 \beta_2]'\) e seja o modelo populacional
\[Y = \textbf{X} \beta + u\]
Vamos supor que trabalhamos como se o modelo fosse \(Y = X_1 \beta_1 + u\).
Em geral, \(\mathbb{E}(\hat{\beta}_1) \neq \beta_1\)
\(\mathbb{E}(\hat{\beta}_1) = \beta_1\) se \(\beta_2 = 0\) ou \(X_1'X_2 = 0\) (ortogonal). Se \(X_1\) e \(X_2\) forem centradas, é equivalente a dizer que a correlação deve ser 0.
Variáveis omitidas
Code
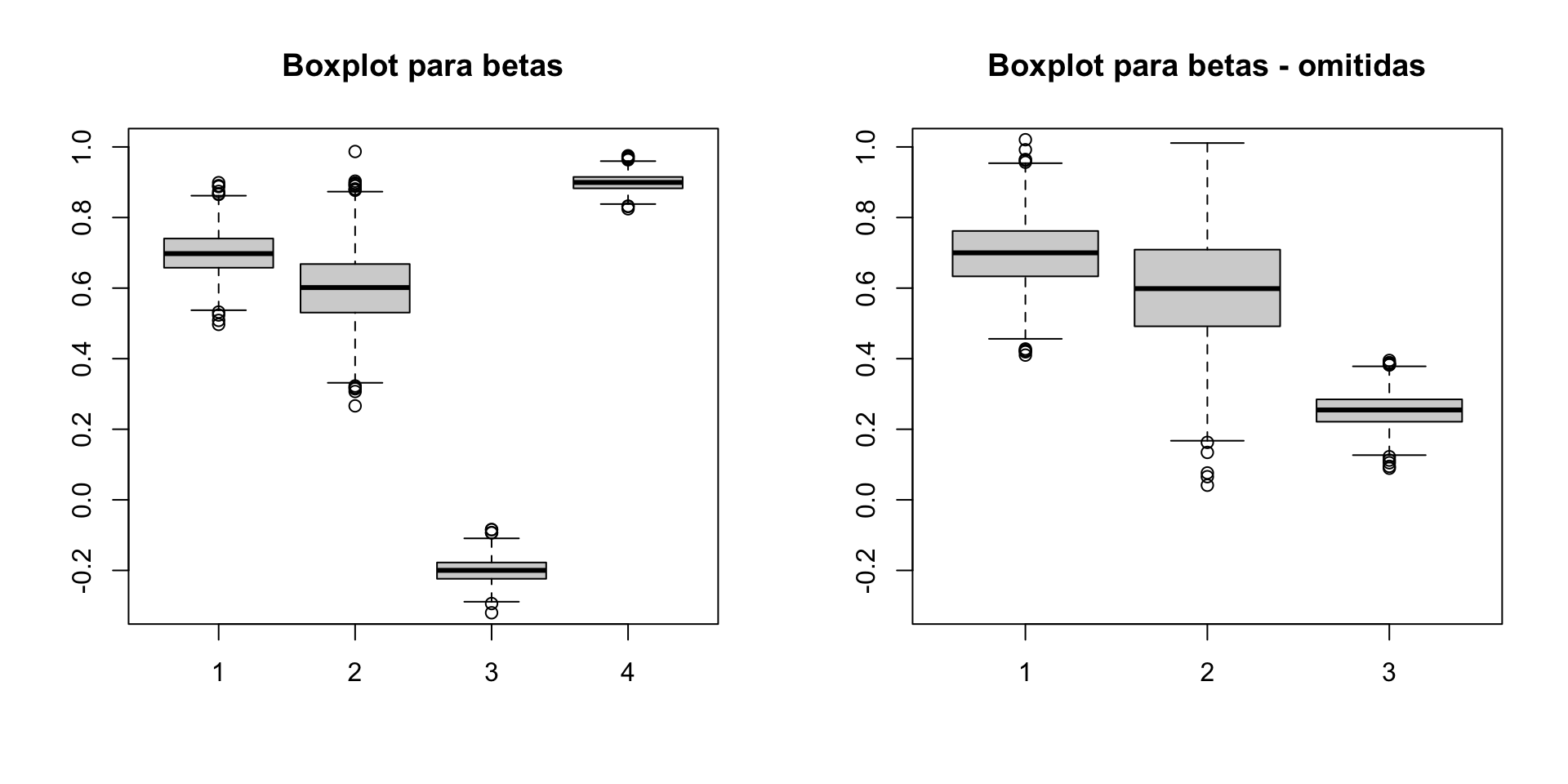
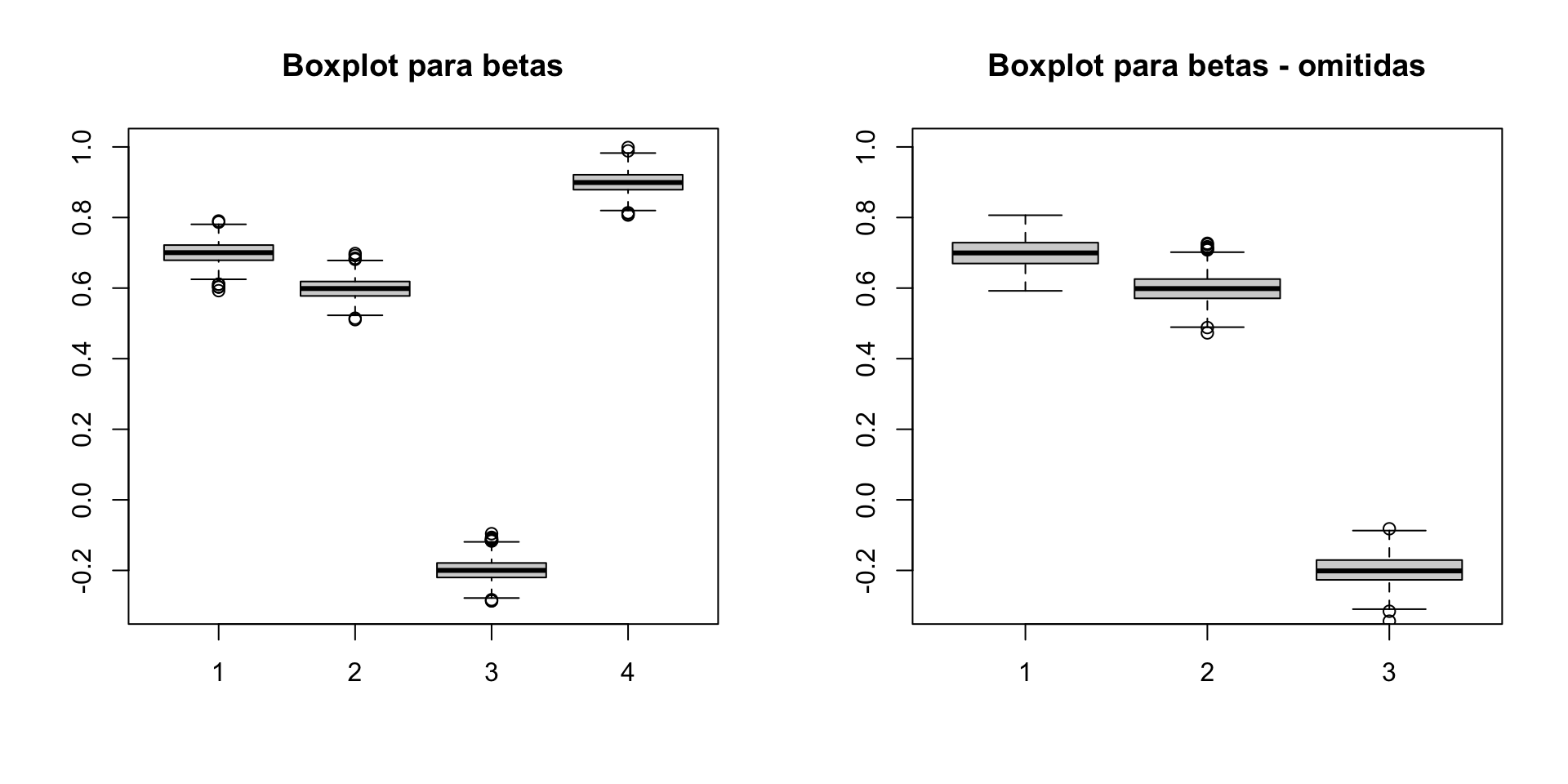
library(MASS)n <-1000betas <-matrix(NA, ncol =4, nrow =1000)betas_o <-matrix(NA, ncol =3, nrow =1000)for (i in1:1000) { u <-rnorm(n) x <-mvrnorm(n, mu =c(0,0,0), Sigma =matrix(c(1, 0, 0, 0, 1, 0, 0, 0, 1), 3, 3)) x1 <- x[,1] x2 <- x[,2] x3 <- x[,3] y <-0.7+0.6*x1 -0.2*x2 +0.9*x3 + u betas[i, ] <-coef(lm(y ~ x1 + x2 + x3)) betas_o[i, ] <-coef(lm(y ~ x1 + x2))}par(mfrow =c(1, 2))boxplot(betas, ylim =c(-0.3, 1))title("Boxplot para betas")boxplot(betas_o, ylim =c(-0.3, 1))title("Boxplot para betas - omitidas")
Variáveis omitidas
Seja o verdadeiro modelo: \[Y = \textbf{X}_1 \beta_1 + \textbf{X}_2 \beta_2 + u.\]
Se omitirmos as variáveis \(\textbf{X}_2\), então:
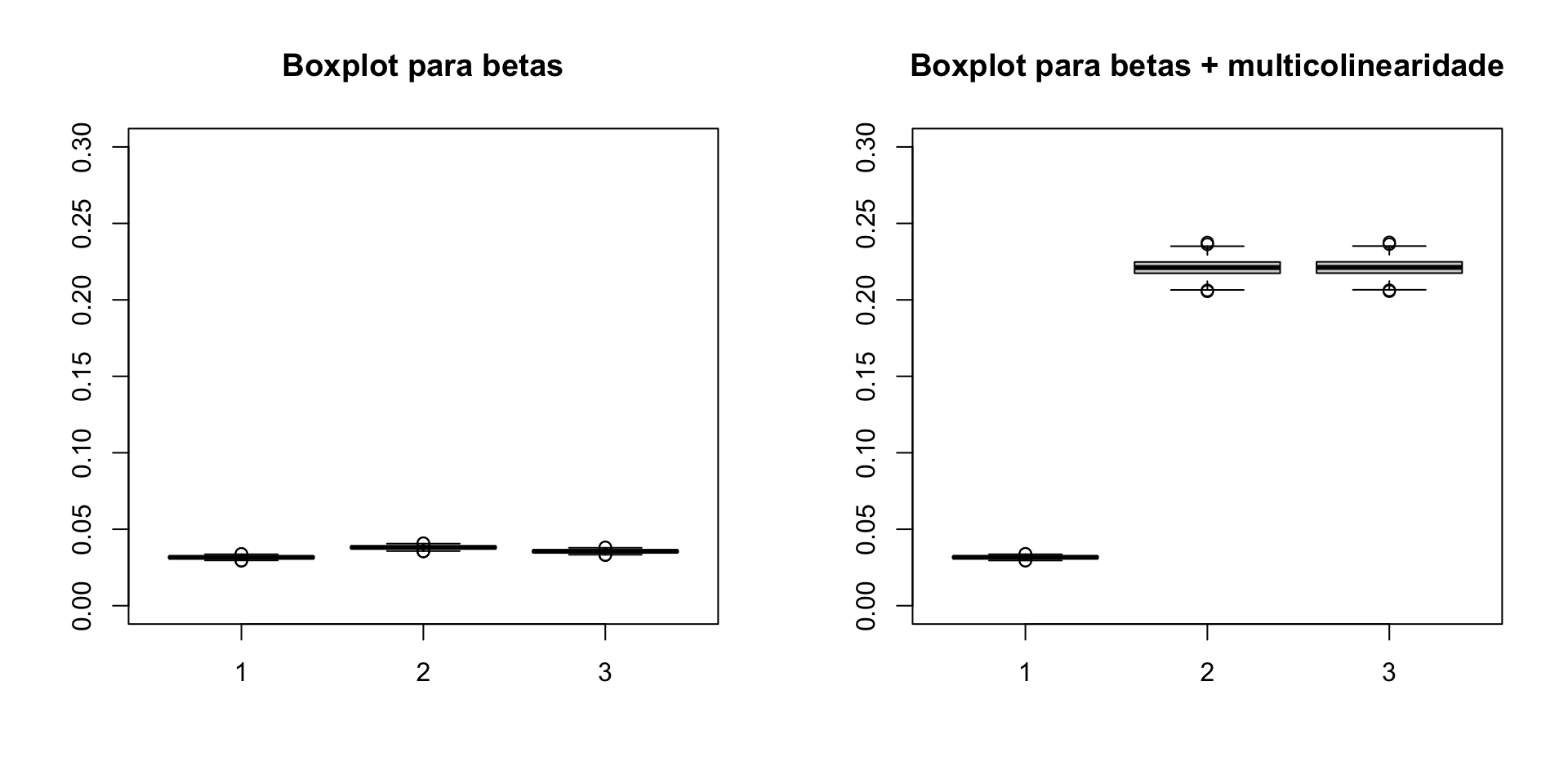
Multicolinearidade tem um efeito na variância dos estimadores, fazendo com que sejam grandes demais.
Lidar com o problema não é trivial.
Uma forma de detetar multicolnearidade é através do fator de inflação da variância (FIV), \[FIV_j = \dfrac{1}{1-R_j^2},\] em que \(R_j^2\) é o coeficiente de determinação da regressão de \(X_j\) sobre todas as outras variáveis independentes.