[1] 1.985523[1] -1.661226[1] 1.661226Modelo de Regressão Linear III
Instituto de Matemática, Estatística e Computação Científica (IMECC),
Universidade Estadual de Campinas (UNICAMP).
Sob HRLM1–HRLM6 e condicional aos valores amostrais de \(X\), \[\dfrac{\hat{\beta}_j - \beta_j}{\sqrt{\mathbb{V}(\hat{\beta}_j | X)}} \sim N(0,1)\]
\[\dfrac{\hat{\beta}_j - \beta_j}{\sqrt{\widehat{\mathbb{V}}(\hat{\beta}_j | X)}} \sim t_{n- k - 1}\]
No modelo \[Y = \beta_0 + \beta_1 X_1 + \ldots + \beta_kX_k +u\]
Geralmente, estamos interessados em testar \[H_0: \beta_j = b \quad vs \quad H_1: \beta_j \neq b\]
\[H_0: \beta_j \leq b \quad vs \quad H_1: \beta_j > b\]
\[H_0: \beta_j \geq b \quad vs \quad H_1: \beta_j < b\]
Para testar hipóteses é preciso uma estatística de teste. A estatística utilizada no Teste T é chamada de estatística t
\[t_{\hat{\beta}_j} = \dfrac{\hat{\beta}_j - b}{\sqrt{\widehat{\mathbb{V}}(\hat{\beta}_j|X)}} \stackrel{H_0}{\sim} t_{n-(k+1)}\]
Quando:
em que \(c\) é um quantil da distribuição \(t_{n-k-1}\) e depende do nível de significância \(\alpha\).
Para um nível de significância\(\alpha\):
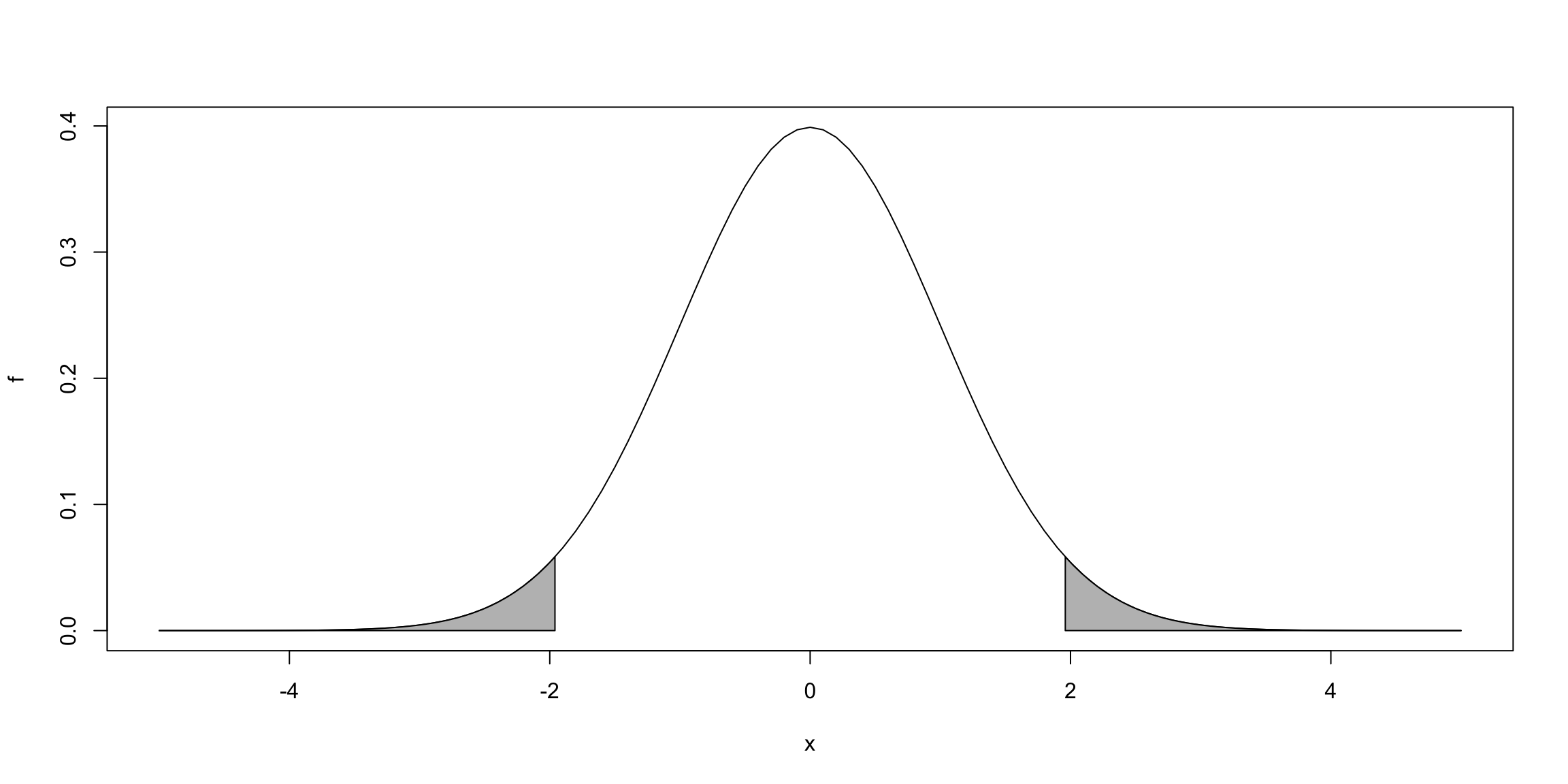
Teste Bilateral: \[H_0: \beta_j = b \quad \text{vs} \quad H_1: \beta_j \neq b,\] rejeitamos \(H_0\) se \(|t_{\hat{\beta}_j}|> c_0 = |t_{\alpha/2,n-(k+1)}| = t_{1-\alpha/2,n-(k+1)}\)
Teste Unilateral:
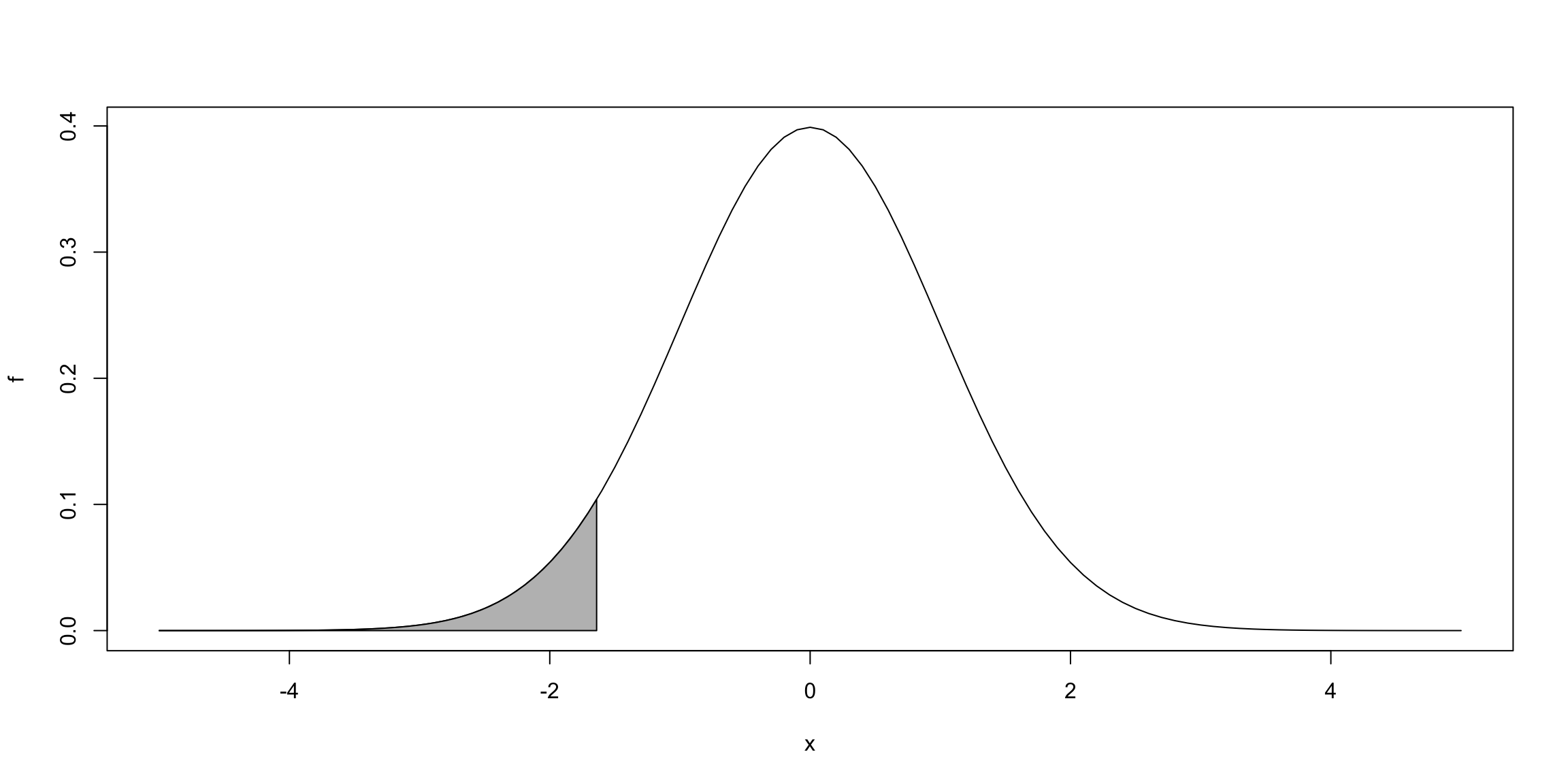
\[H_0: \beta_j \geq b \quad \text{vs} \quad H_1: \beta_j < b,\] rejeitamos \(H_0\) se \(t_{\hat{\beta}_j} < c_1 = t_{\alpha,n-(k+1)}.\)
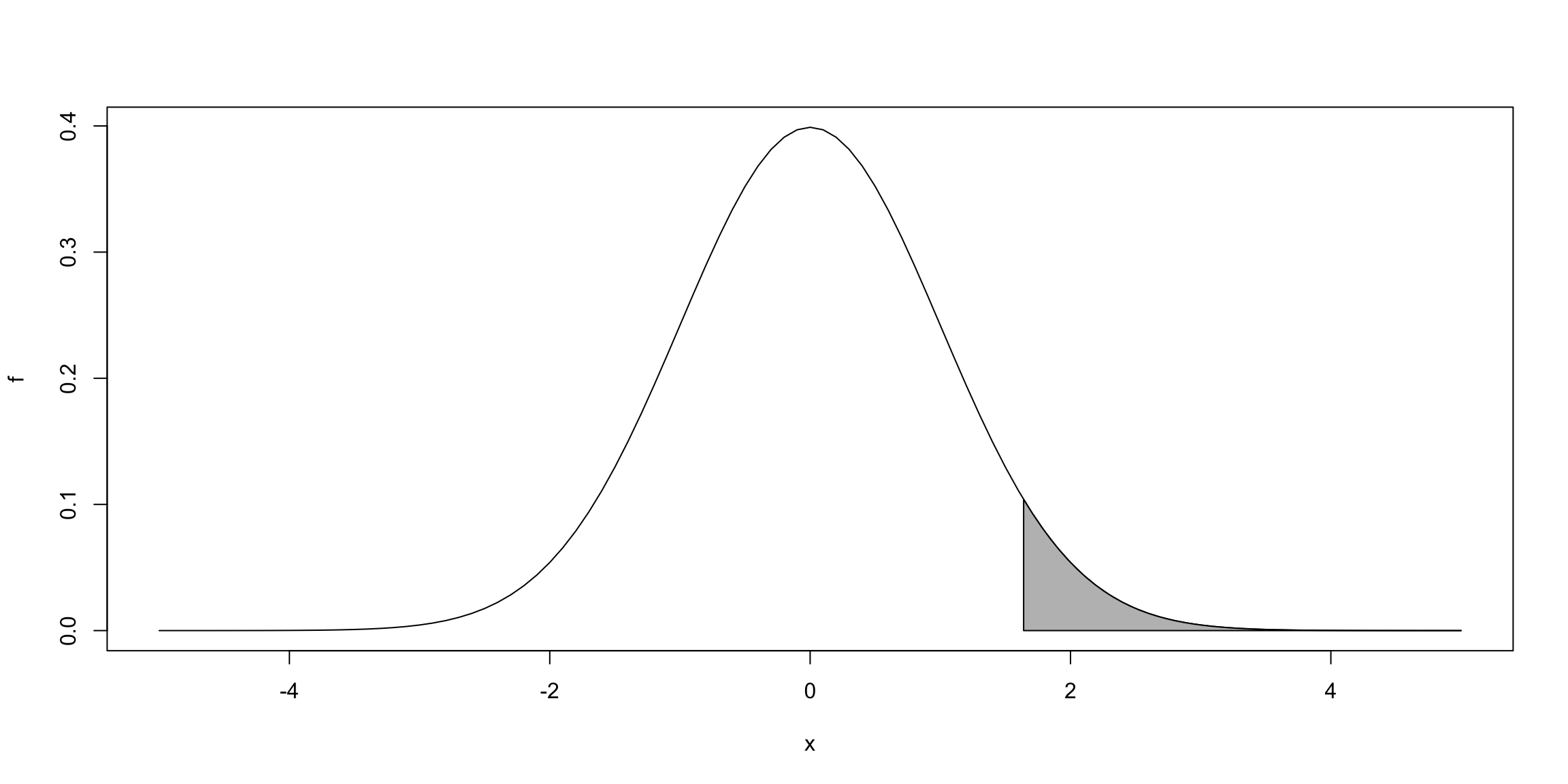
\[H_0: \beta_j \leq b \quad \text{vs} \quad H_1: \beta_j > b,\] rejeitamos \(H_0\) se \(t_{\hat{\beta}_j} > c_2 = t_{1-\alpha,n-(k+1)}.\)
Resumindo, para testar hipóteses precisamos:
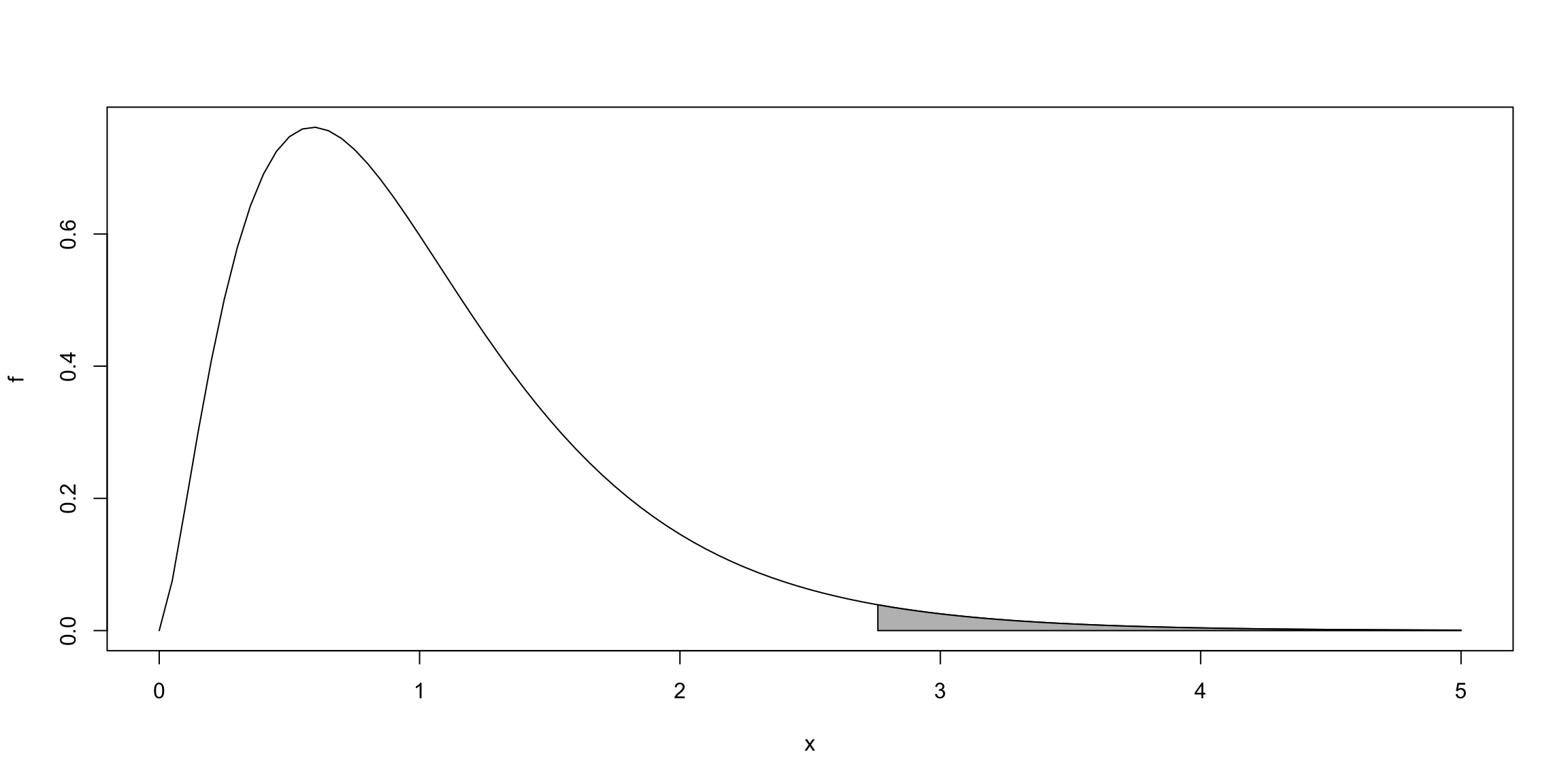
O valor \(c\) é obtido do quantil da distribuição \(t_{n-k-1}\), por exemplo:
Assumindo que todas as suposições do modelo são verificadas, quais variáveis são estatísticamente significativas? (\(\beta_j \neq 0\))
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.2844 0.1042 2.7292 0.0066
educ 0.0920 0.0073 12.5552 0.0000
exper 0.0041 0.0017 2.3914 0.0171
tenure 0.0221 0.0031 7.1331 0.0000| Dep. Variable: | np.log(wage) | R-squared: | 0.316 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.312 |
| Method: | Least Squares | F-statistic: | 80.39 |
| Date: | Wed, 16 Aug 2023 | Prob (F-statistic): | 9.13e-43 |
| Time: | 16:06:17 | Log-Likelihood: | -313.55 |
| No. Observations: | 526 | AIC: | 635.1 |
| Df Residuals: | 522 | BIC: | 652.2 |
| Df Model: | 3 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 0.2844 | 0.104 | 2.729 | 0.007 | 0.080 | 0.489 |
| educ | 0.0920 | 0.007 | 12.555 | 0.000 | 0.078 | 0.106 |
| exper | 0.0041 | 0.002 | 2.391 | 0.017 | 0.001 | 0.008 |
| tenure | 0.0221 | 0.003 | 7.133 | 0.000 | 0.016 | 0.028 |
| Omnibus: | 11.534 | Durbin-Watson: | 1.769 |
|---|---|---|---|
| Prob(Omnibus): | 0.003 | Jarque-Bera (JB): | 20.941 |
| Skew: | 0.021 | Prob(JB): | 2.84e-05 |
| Kurtosis: | 3.977 | Cond. No. | 135. |
─────────────────────────────────────────────────────────────────────────────
Coef. Std. Error t Pr(>|t|) Lower 95% Upper 95%
─────────────────────────────────────────────────────────────────────────────
(Intercept) 0.28436 0.10419 2.73 0.0066 0.0796756 0.489044
educ 0.092029 0.00732992 12.56 <1e-31 0.0776292 0.106429
exper 0.00412111 0.00172328 2.39 0.0171 0.000735698 0.00750652
tenure 0.0220672 0.00309365 7.13 <1e-11 0.0159897 0.0281447
─────────────────────────────────────────────────────────────────────────────E se quisermos testar \(H_0: \beta_{educ} \geq 0 \quad \text{vs} \quad \beta_{educ} < 0\)?
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.2844 0.1042 2.7292 0.0066
educ 0.0920 0.0073 12.5552 0.0000
exper 0.0041 0.0017 2.3914 0.0171
tenure 0.0221 0.0031 7.1331 0.0000E se quisermos testar \(H_0: \beta_{educ} = 1 \quad \text{vs} \quad \beta_{educ} \neq 1\)?
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.2844 0.1042 2.7292 0.0066
educ 0.0920 0.0073 12.5552 0.0000
exper 0.0041 0.0017 2.3914 0.0171
tenure 0.0221 0.0031 7.1331 0.0000Seja o modelo \[Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \ldots + \beta_k X_k +u\] E seja \(H_0: \beta_1 = 0, \beta_2 = 0, \ldots, \beta_q = 0\). Então, o modelo (sob \(H_0\)) é dado por \[y = \beta_0 + \beta_{q+1} x_{q+1} + \beta_{q+2} x_{q+2} + \ldots + \beta_k x_k +u\]
Sob HRLM1–HRLM6, o é dado por \[F = \dfrac{(SQR_r - SQR_i)/q}{SQR_i /(n-(k+1))} \stackrel{H_0}{\sim} F_{q,n-(k+1)}\]
\[F = \dfrac{(SQR_r - SQR_i)/q}{SQR_i /(n-(k+1))} \stackrel{H_0}{\sim} F_{q,n-(k+1)}\]
No modelo \(\log(wage) = \beta_0 + \beta_1 educ + \beta_2 exper + \beta_3 tenure + u\)
Queremos testar: \(H_0: \beta_1=0, \beta_3 = 0 \quad \text{vs} \quad H_1: H_0 \text{ não é verdadeira}\)
\[F = \dfrac{(SQR_r - SQR_i)/q}{SQR_i /(n-(k+1))} \stackrel{H_0}{\sim} F_{q,n-(k+1)}\]
[1] 115.8532[1] 3.012991Como \(\underbrace{F}_{115.8532} > \underbrace{c}_{3.012991}\), então rejeitamos \(H_0\) com um nível de significância \(\alpha = 0.05\).
Analysis of Variance Table
Model 1: log(wage) ~ exper
Model 2: log(wage) ~ educ + exper + tenure
Res.Df RSS Df Sum of Sq F Pr(>F)
1 524 146.49
2 522 101.46 2 45.034 115.85 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1F-test: 2 models fitted on 526 observations
────────────────────────────────────────────────────────────────────
DOF ΔDOF SSR ΔSSR R² ΔR² F* p(>F)
────────────────────────────────────────────────────────────────────
[1] 3 146.4899 0.0124
[2] 5 2 101.4556 -45.0343 0.3160 0.3036 115.8532 <1e-41
────────────────────────────────────────────────────────────────────Dado um modelo da forma \[Y = \beta_0 + \beta_1 X_1 + \ldots + \beta_k X_k + u,\]
um teste bastante rotineiro nos modelos de regressão é:
\[H_0: \beta_1 = 0, \beta_2 = 0, \ldots, \beta_k=0 \quad \text{vs} \quad H_0: H_1 \text{ não é verdadeiro}\]
Estes testes são geralmente feitos por padrão nos pacotes e quando encontrar “Teste F” estão-se referindo ao teste da significância global do modelo.
Call:
lm(formula = log(wage) ~ educ + exper + tenure, data = wage1)
Residuals:
Min 1Q Median 3Q Max
-2.05802 -0.29645 -0.03265 0.28788 1.42809
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.284360 0.104190 2.729 0.00656 **
educ 0.092029 0.007330 12.555 < 2e-16 ***
exper 0.004121 0.001723 2.391 0.01714 *
tenure 0.022067 0.003094 7.133 3.29e-12 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.4409 on 522 degrees of freedom
Multiple R-squared: 0.316, Adjusted R-squared: 0.3121
F-statistic: 80.39 on 3 and 522 DF, p-value: < 2.2e-16| Dep. Variable: | np.log(wage) | R-squared: | 0.316 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.312 |
| Method: | Least Squares | F-statistic: | 80.39 |
| Date: | Wed, 16 Aug 2023 | Prob (F-statistic): | 9.13e-43 |
| Time: | 16:07:07 | Log-Likelihood: | -313.55 |
| No. Observations: | 526 | AIC: | 635.1 |
| Df Residuals: | 522 | BIC: | 652.2 |
| Df Model: | 3 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 0.2844 | 0.104 | 2.729 | 0.007 | 0.080 | 0.489 |
| educ | 0.0920 | 0.007 | 12.555 | 0.000 | 0.078 | 0.106 |
| exper | 0.0041 | 0.002 | 2.391 | 0.017 | 0.001 | 0.008 |
| tenure | 0.0221 | 0.003 | 7.133 | 0.000 | 0.016 | 0.028 |
| Omnibus: | 11.534 | Durbin-Watson: | 1.769 |
|---|---|---|---|
| Prob(Omnibus): | 0.003 | Jarque-Bera (JB): | 20.941 |
| Skew: | 0.021 | Prob(JB): | 2.84e-05 |
| Kurtosis: | 3.977 | Cond. No. | 135. |
F-test: 2 models fitted on 526 observations
────────────────────────────────────────────────────────────────────
DOF ΔDOF SSR ΔSSR R² ΔR² F* p(>F)
────────────────────────────────────────────────────────────────────
[1] 2 148.3297 -0.0000
[2] 5 3 101.4556 -46.8742 0.3160 0.3160 80.3909 <1e-42
────────────────────────────────────────────────────────────────────Imagine os seguintes casos:
| Caso: | Hipóteses |
|---|---|
| Caso 1 | \(H_0: \beta_i = 0\) |
| Caso 2 | \(H_0: \beta_i = b_i\) |
| Caso 3 | \(H_0: \beta_i + \beta_j = b\) |
| Caso 4 | \(H_0: \beta_i = \beta_j\) |
| Caso 5 | \(H_0: [\beta_1, \cdots, \beta_k]' = 0\) |
| Caso 6 | \(H_0: \boldsymbol{\beta}_2 = 0\) |
Em que \(\boldsymbol{\beta} = [\boldsymbol{\beta}_1, \boldsymbol{\beta}_2]\) com \(\boldsymbol{\beta}_1\) de dimensão \(k_1\) e \(\boldsymbol{\beta}_2\) de dimensão \(k_2\)
Todos os casos anteriores estão dentro do seguinte escopo: \[H_0: R \boldsymbol{\beta} = r \quad ou \quad \equiv \quad H_0: R \boldsymbol{\beta} - r = 0\]
em que
| Hipóteses | \(R, r \text{ e } q\) |
|---|---|
| \(H_0: \beta_i = 0\) | \(R = [0, \cdots, 0, \underbrace{1}_{i-th}, 0, \cdots, 0]\), r = 0, q = 1 |
| \(H_0: \beta_i = b_i\) | \(R = [0, \cdots, 0, \underbrace{1}_{i-th}, 0, \cdots, 0]\), r = \(b_i\), q = 1 |
| \(H_0: \beta_i + \beta_j = b\) | \(R = [0, \cdots, \underbrace{1}_{i-th}, 0, \cdots, \underbrace{1}_{j-th}, \cdots 0]\), r = \(b\), q = 1 |
| \(H_0: \beta_i = \beta_j\) | \(R = [0, \cdots, \underbrace{1}_{i-th}, 0, \cdots, \underbrace{-1}_{j-th}, \cdots 0]\), r = 0, q = 1 |
| \(H_0: [\beta_1, \cdots, \beta_k]' = 0\) | \(R = [0, \textbf{I}_{k}]\), r = 0, q = k |
| \(H_0: \boldsymbol{\beta}_2 = 0\) | \(R = [0_{k_2 \times k_1 }, \textbf{I}_{k_2}]\), r = 0, q = \(k_2\) |
Sob as hipóteses do modelo linear clássico e condicional em \(\textbf{X}\), \[\hat{\beta} \sim N(\beta, \sigma^2 (X'X)^{-1}),\]
\[R\hat{\beta} \sim N(R\beta, \sigma^2 R(X'X)^{-1}R'),\]
\[R\hat{\beta} - R\beta \sim N(0, \sigma^2 R(X'X)^{-1}R'),\]
Sob \(H_0\)
\[R\hat{\beta} - r \sim N(0, \sigma^2 R(X'X)^{-1}R'),\]
\[(R\hat{\beta} - r)' [\sigma^2 R(X'X)^{-1}R']^{-1}(R\hat{\beta} - r) \sim \chi^2_q,\]
Por outro lado, sabemos que \[(n - k - 1)s^2/\sigma^2 = \dfrac{\hat{u}'\hat{u}}{\sigma^2} \sim \chi^2_{n-k-1}\]
Então, \[\dfrac{(R\hat{\beta} - r)' [R(X'X)^{-1}R']^{-1}(R\hat{\beta} - r)/q}{\hat{u}'\hat{u}/(n-k-1)}\sim F(q, n-k-1)\] ou, equivalentemente,
\[(R\hat{\beta} - r)' [s^2(X'X)^{-1}]^{-1}(R\hat{\beta} - r)/q\sim F(q, n-k-1)\]
Observação \(t^2_n = F(1, n)\)
\[H_0: R\beta = b\]
\[H_0: R\beta = 0\]
Tip
\(A = \left[ {\begin{array}{cc} A_{11} & A_{12} \\ A_{21} & A_{22} \\ \end{array} } \right] \rightarrow A^{-1} = \left[ {\begin{array}{cc} A_{11}^{-1} + A_{11}^{-1}A_{12}B_{22}A_{21}A_{11}^{-1} & -A_{11}^{-1}A_{12}B_{22} \\ -B_{22}A_{21}A_{11}^{-1} & B_{22} \\ \end{array} } \right],\) em que \(B_{22} = (A_{22} - A_{21}A_{11}^{-1}A_{12})^{-1}\)
Note que: \[B_{22} = (A_{22} - A_{21}A_{11}^{-1}A_{12})^{-1} =\] \[(\underbrace{X_2'X_2 - X_2'X_1(X_1'X_1)^{-1}X_1'X_2}_{\underbrace{X_2'(I - X_1(X_1'X_1)^{-1}X_1') X_2}_{X_2'M_1 X_2}})^{-1}\]
Então, \((R\hat{\beta} - r)' [s^2R(X'X)^{-1}R']^{-1}(R\hat{\beta} - r)/q \rightarrow (\hat{\boldsymbol{\beta}}_2)'(s^{-2} X_2'M_1X_2) (\hat{\boldsymbol{\beta}}_2)/k_2 \sim F_{k_2, n - k - 1}\)
Por outro lado,
\[Y = [X_1, X_1][\boldsymbol{\hat{\beta}}_1,\boldsymbol{\hat{\beta}}_2]'+ \hat{u}\]
\[M_1 Y = \underbrace{M_1X_1 \boldsymbol{\hat{\beta}}_1}_{0} + M_1X_2 \boldsymbol{\hat{\beta}}_2 + \underbrace{M_1 \hat{u}}_{\hat{u}}\]
\[\underbrace{Y'M_1'M_1Y}_{Y'M_1Y} = \boldsymbol{\hat{\beta}}_2'X_2' M_1X_2 \boldsymbol{\hat{\beta}}_2 + \hat{u}'\hat{u}\]
\[\dfrac{(Y'M_1Y - \hat{u}'\hat{u})/k_2}{\hat{u}'\hat{u}/(n - k -1)} = \dfrac{(SQRr - SQRi)/k_2}{SQRi/(n - k - 1)} \sim F_{k_2, n - k -1}\]

Carlos Trucíos (IMECC/UNICAMP) | ME715 - Econometria | ctruciosm.github.io