Suavização Exponencial
ME607 - Séries Temporais
Médias Móveis Simples

Suavização Exponencial Simples
Com este método, a previsão um passo à frente é obtida através de:
\[\hat{y}_{T+1|T} = \alpha y_{T} + (1-\alpha) \hat{y}_{T|T-1} = \hat{y}_{T|T-1} + \alpha (y_T - \hat{y}_{T|T-1}),\] em que \(0 \leq \alpha \leq 1\) é o parâmetro de suavização.
Suavização Exponencial Simples
Code
library(ggplot2)
p <- 0:100
alpha <- c(0.05, 0.2, 0.4, 0.6, 0.8, 0.95)
y1 <- alpha[1] * (1 - alpha[1])^p
y2 <- alpha[2] * (1 - alpha[2])^p
y3 <- alpha[3] * (1 - alpha[3])^p
y4 <- alpha[4] * (1 - alpha[4])^p
y5 <- alpha[5] * (1 - alpha[5])^p
y6 <- alpha[6] * (1 - alpha[6])^p
dados <- data.frame(Pesos = c(y1, y2, y3, y4, y5, y6),
Alpha = c(rep("0.05", 101), rep("0.2", 101),
rep("0.4", 101), rep("0.6", 101),
rep("0.8", 101), rep("0.95", 101)),
Tempo = rep(1:101, 6))
ggplot(dados) + geom_line(aes(x = Tempo, y = Pesos, color = Alpha))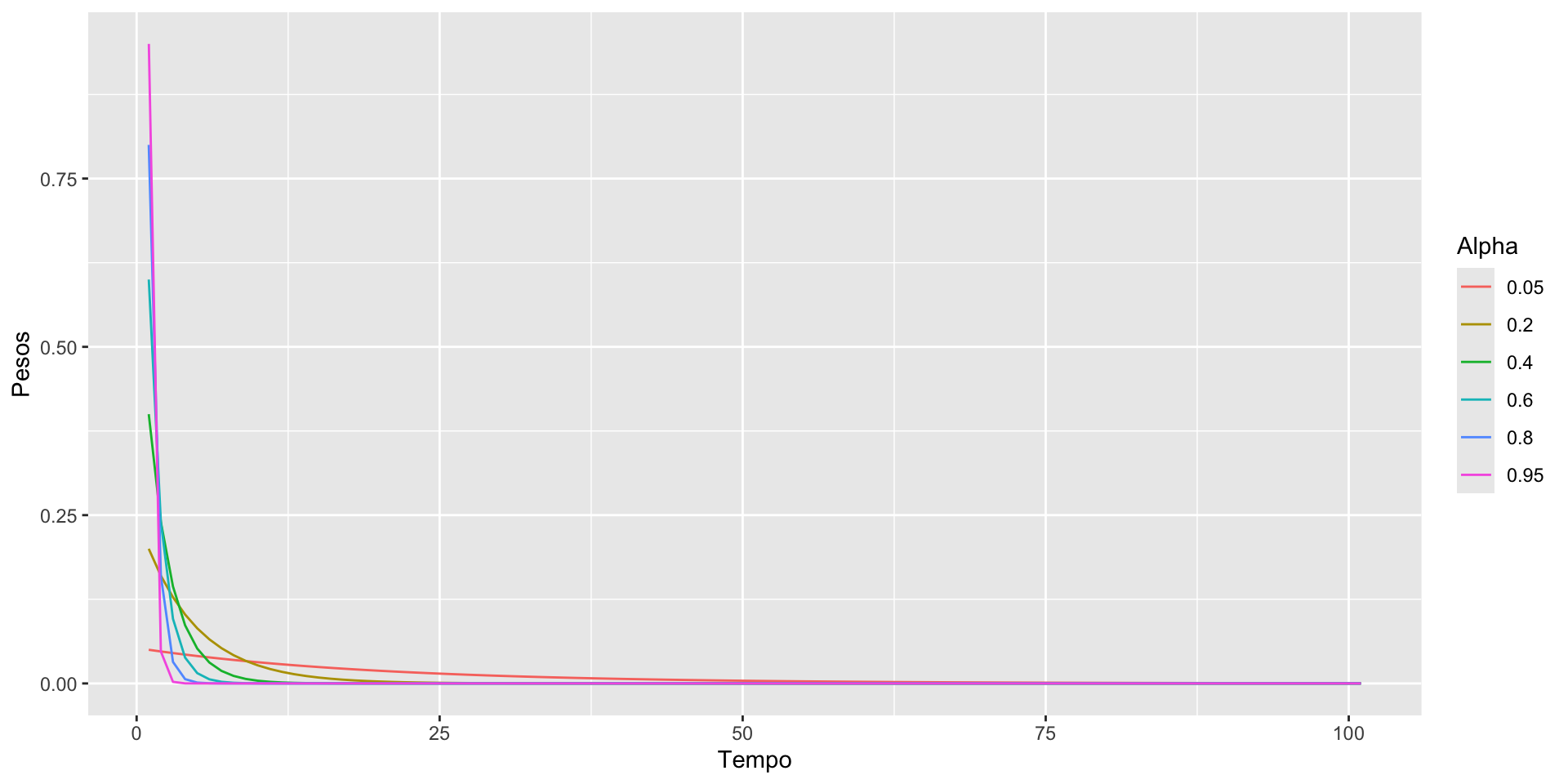
O peso que recebem as observações mais antigas cai rapidamente.
Suavização Exponencial Simples
Code
Rows: 58
Columns: 9
Key: Country [1]
$ Country <fct> "Algeria", "Algeria", "Algeria", "Algeria", "Algeria", "Alg…
$ Code <fct> DZA, DZA, DZA, DZA, DZA, DZA, DZA, DZA, DZA, DZA, DZA, DZA,…
$ Year <dbl> 1960, 1961, 1962, 1963, 1964, 1965, 1966, 1967, 1968, 1969,…
$ GDP <dbl> 2723648552, 2434776646, 2001468868, 2703014867, 2909351793,…
$ Growth <dbl> NA, -13.605441, -19.685042, 34.313729, 5.839413, 6.206898, …
$ CPI <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, 2.569025, 2.738580, 2.8…
$ Imports <dbl> 67.14363, 67.50377, 20.81865, 36.82552, 29.43976, 25.83308,…
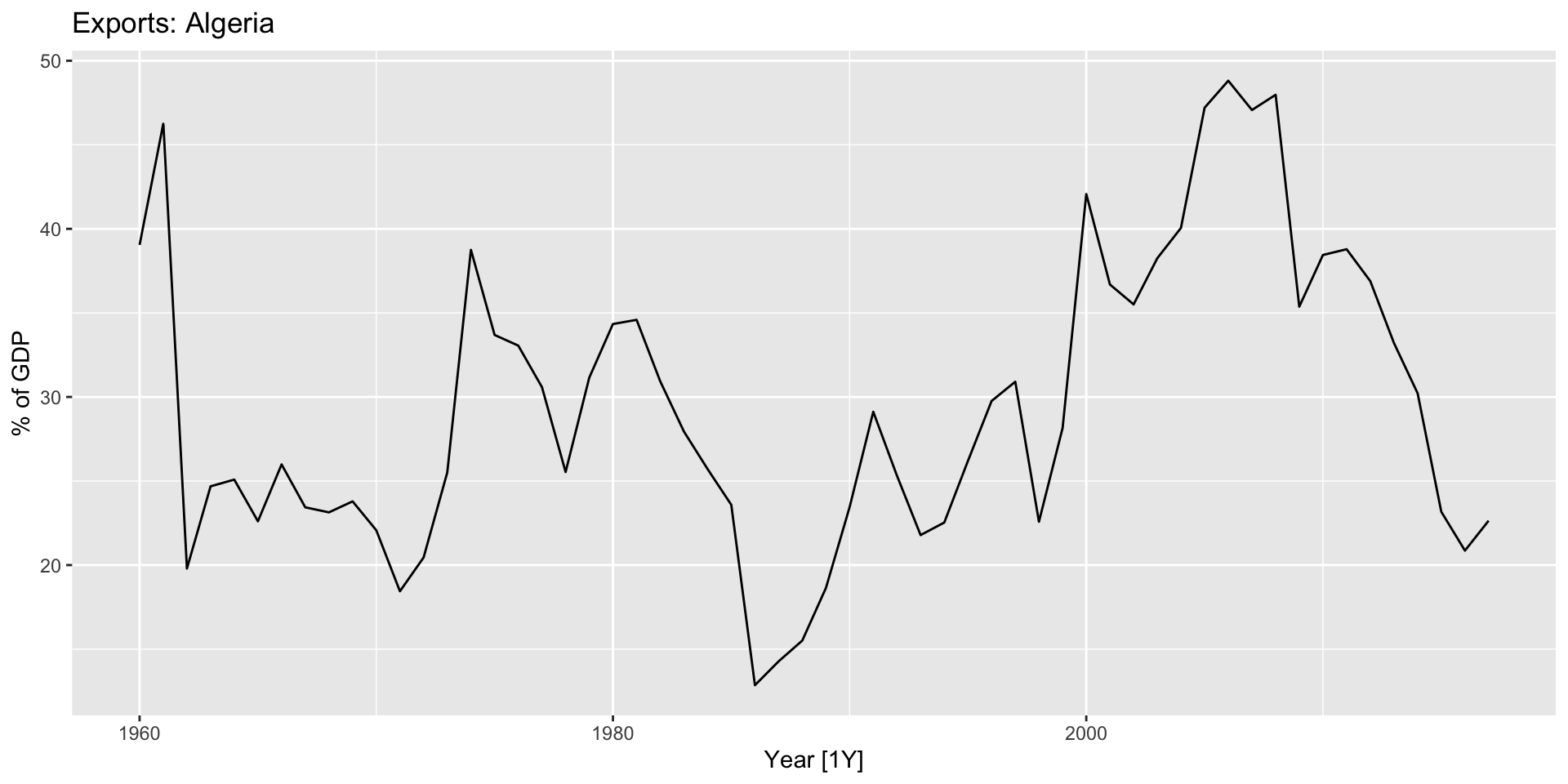
$ Exports <dbl> 39.04317, 46.24456, 19.79387, 24.68468, 25.08406, 22.60394,…
$ Population <dbl> 11124888, 11404859, 11690153, 11985136, 12295970, 12626952,…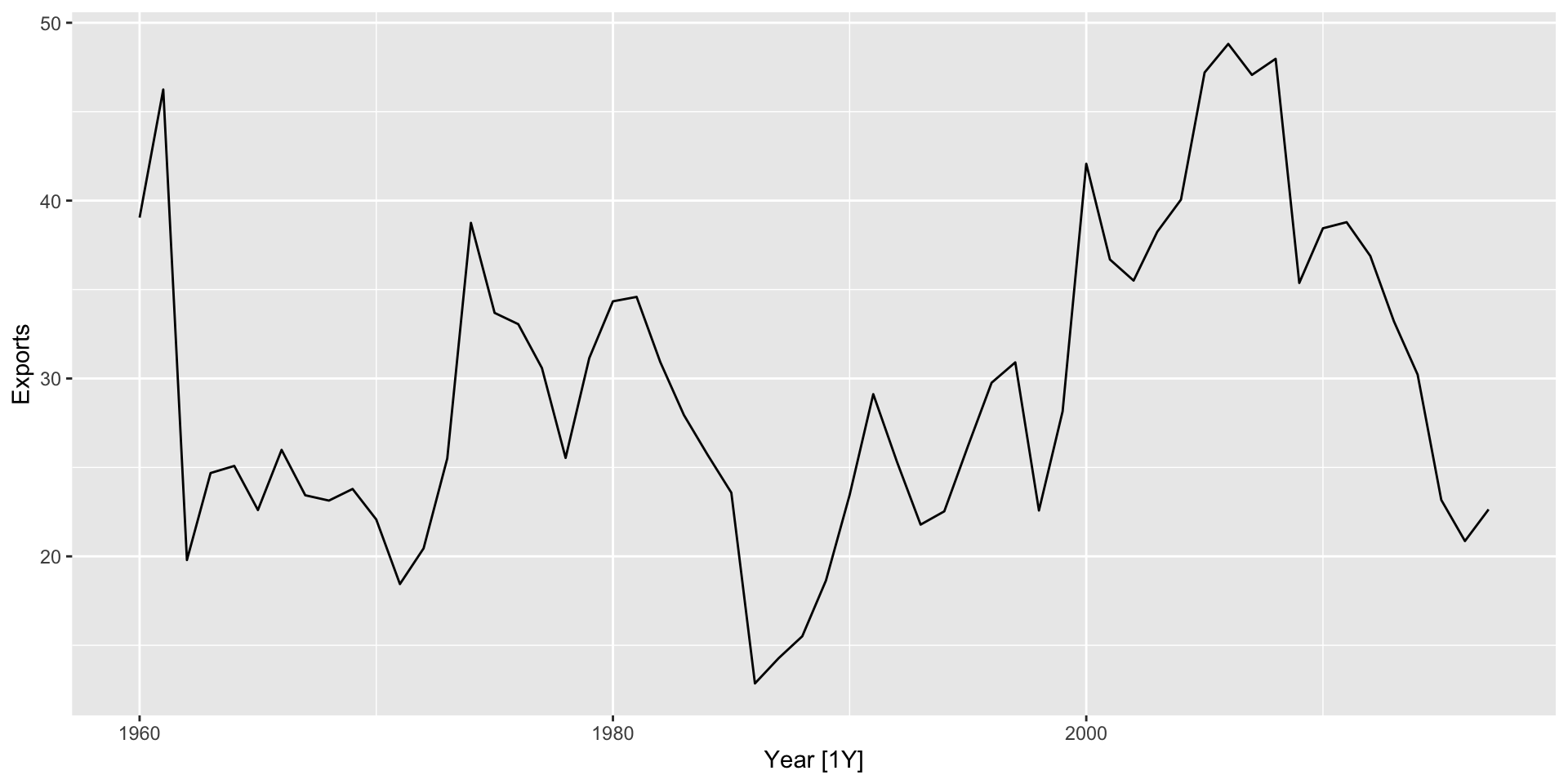
Sem tendência nem sazonalidade claras, canditato perfeito para usar suavização exponencial.
# A fable: 6 x 5 [1Y]
# Key: Country, .model [1]
Country .model Year
<fct> <chr> <dbl>
1 Algeria "ETS(Exports ~ error(\"A\"))" 2018
2 Algeria "ETS(Exports ~ error(\"A\"))" 2019
3 Algeria "ETS(Exports ~ error(\"A\"))" 2020
4 Algeria "ETS(Exports ~ error(\"A\"))" 2021
5 Algeria "ETS(Exports ~ error(\"A\"))" 2022
6 Algeria "ETS(Exports ~ error(\"A\"))" 2023
# ℹ 2 more variables: Exports <dist>, .mean <dbl>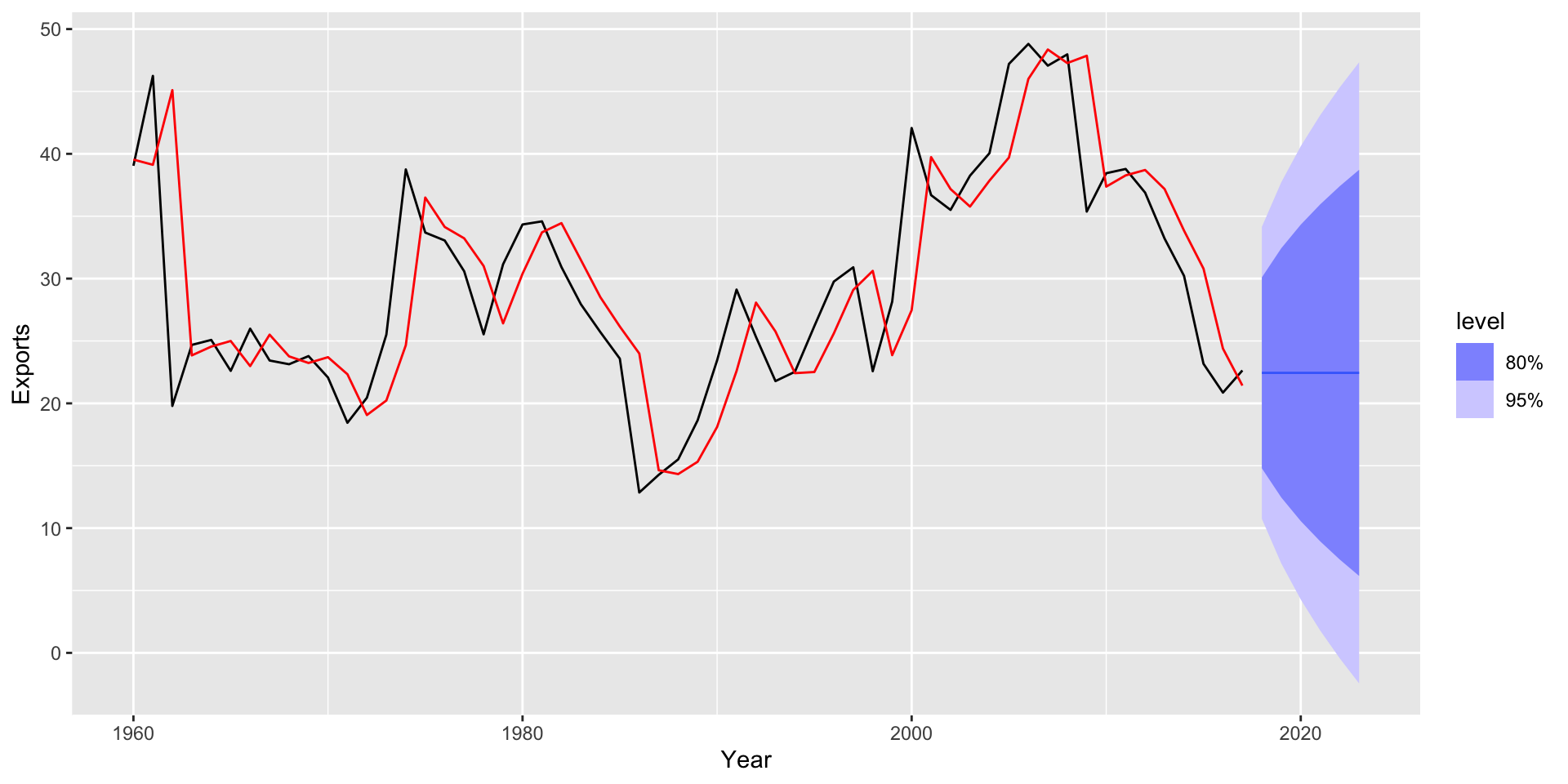
Suavização Exponencial Simples
veja que o proceso da forma \(y_t = \mu_t + e_t\) é um processo em que nem a tendência nem a sazonalidade são aparentes.
Suavização Exponencial Simples tem previsão “flat”, i.e. \[\hat{y}_{T+h|T} = \hat{y}_{T+1|T} = \alpha y_T + (1 - \alpha) \hat{y}_{T|T-1}\]
Método de Holt
Code
Rows: 58
Columns: 10
Key: Country [1]
$ Country <fct> "Australia", "Australia", "Australia", "Australia", "Austra…
$ Code <fct> AUS, AUS, AUS, AUS, AUS, AUS, AUS, AUS, AUS, AUS, AUS, AUS,…
$ Year <dbl> 1960, 1961, 1962, 1963, 1964, 1965, 1966, 1967, 1968, 1969,…
$ GDP <dbl> 18573188487, 19648336880, 19888005376, 21501847911, 2375853…
$ Growth <dbl> NA, 2.4856050, 1.2964777, 6.2142784, 6.9787237, 5.9834500, …
$ CPI <dbl> 7.960458, 8.142560, 8.116545, 8.168574, 8.402706, 8.688866,…
$ Imports <dbl> 14.06175, 15.02508, 12.63093, 13.83405, 13.76450, 15.26734,…
$ Exports <dbl> 12.99445, 12.40310, 13.94301, 13.00589, 14.93825, 13.22018,…
$ Population <dbl> 10276477, 10483000, 10742000, 10950000, 11167000, 11388000,…
$ Pop <dbl> 10.27648, 10.48300, 10.74200, 10.95000, 11.16700, 11.38800,…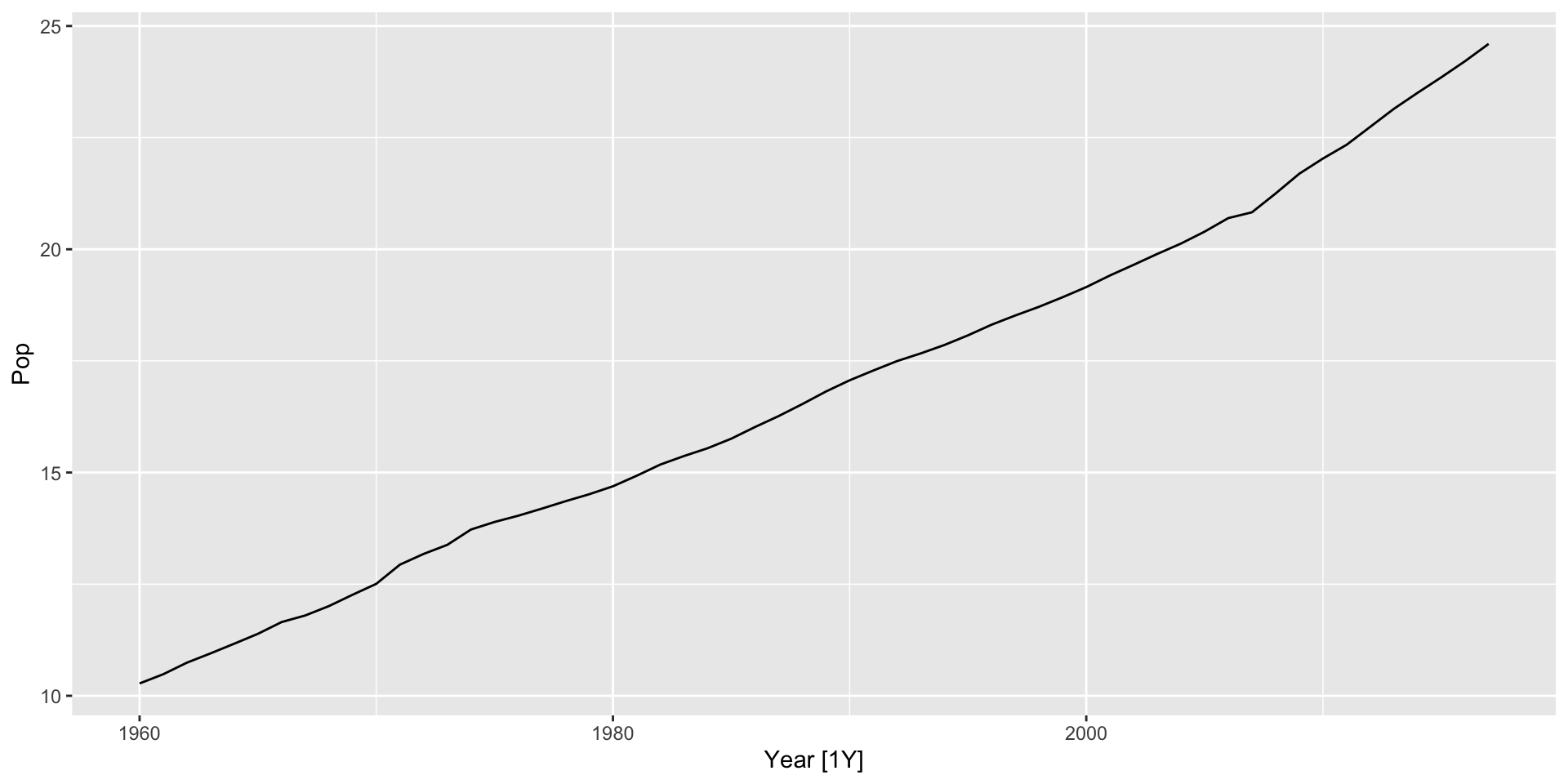
# A fable: 6 x 5 [1Y]
# Key: Country, .model [1]
Country .model Year
<fct> <chr> <dbl>
1 Australia "ETS(Pop ~ error(\"A\") + trend(\"A\"))" 2018
2 Australia "ETS(Pop ~ error(\"A\") + trend(\"A\"))" 2019
3 Australia "ETS(Pop ~ error(\"A\") + trend(\"A\"))" 2020
4 Australia "ETS(Pop ~ error(\"A\") + trend(\"A\"))" 2021
5 Australia "ETS(Pop ~ error(\"A\") + trend(\"A\"))" 2022
6 Australia "ETS(Pop ~ error(\"A\") + trend(\"A\"))" 2023
# ℹ 2 more variables: Pop <dist>, .mean <dbl>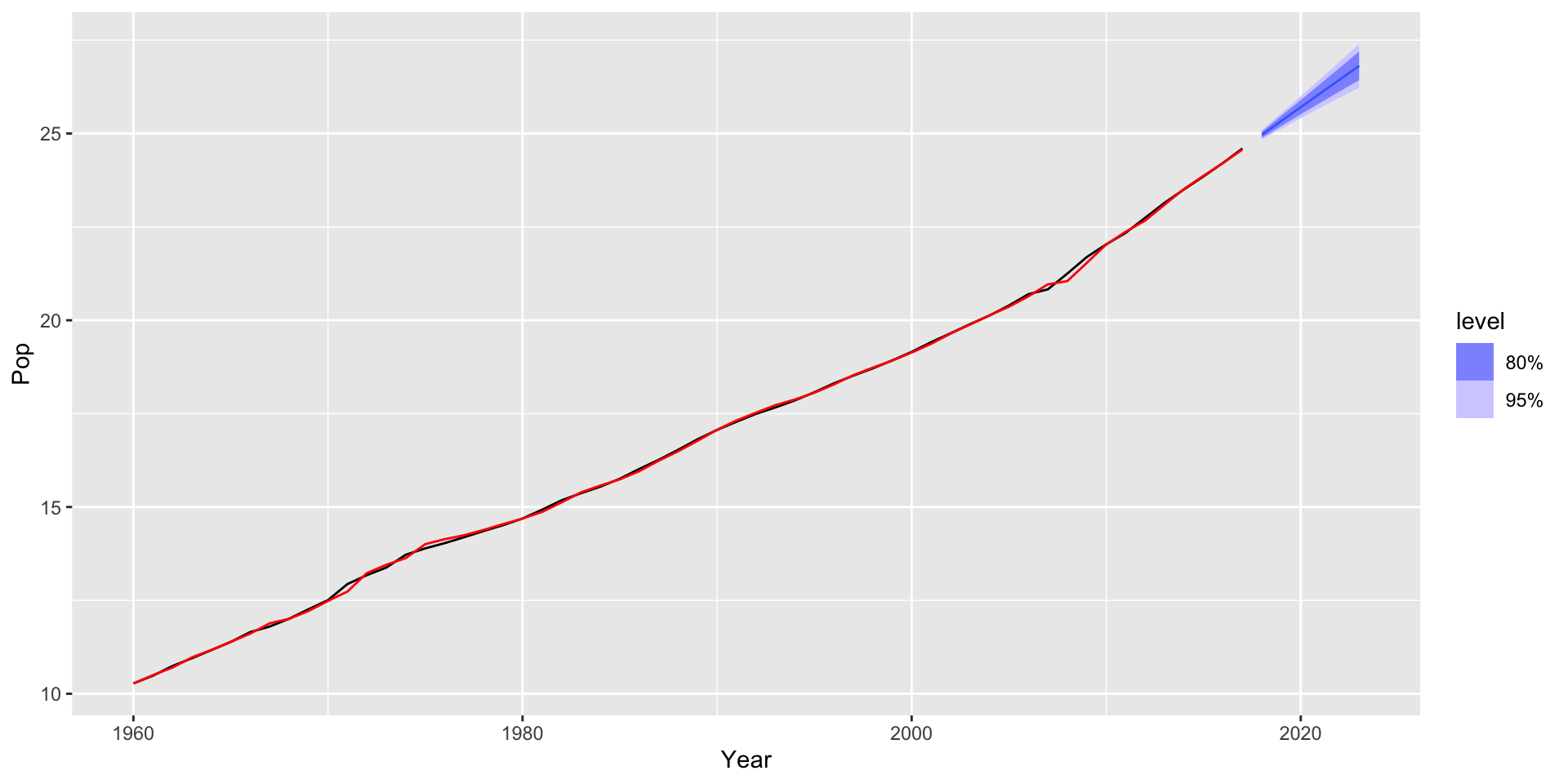
Code
Holt's method
Call:
holt(y = australia_economy_ts, h = 6, initial = "optimal")
Smoothing parameters:
alpha = 0.9999
beta = 0.3267
Initial states:
l = 10.0541
b = 0.2225
sigma: 0.0643
AIC AICc BIC
-76.98568 -75.83184 -66.68347 Método de Holt com tendência não constante
Code
Series: Pop
Model: ETS(A,Ad,N)
Smoothing parameters:
alpha = 0.9986305
beta = 0.4271838
phi = 0.98
Initial states:
l[0] b[0]
10.03648 0.2478533
sigma^2: 0.0045
AIC AICc BIC
-71.01630 -69.36924 -58.65364 # A fable: 12 x 5 [1Y]
# Key: Country, .model [2]
Country .model Year
<fct> <chr> <dbl>
1 Australia holt 2018
2 Australia holt 2019
3 Australia holt 2020
4 Australia holt 2021
5 Australia holt 2022
6 Australia holt 2023
7 Australia amortecimento 2018
8 Australia amortecimento 2019
9 Australia amortecimento 2020
10 Australia amortecimento 2021
11 Australia amortecimento 2022
12 Australia amortecimento 2023
# ℹ 2 more variables: Pop <dist>, .mean <dbl>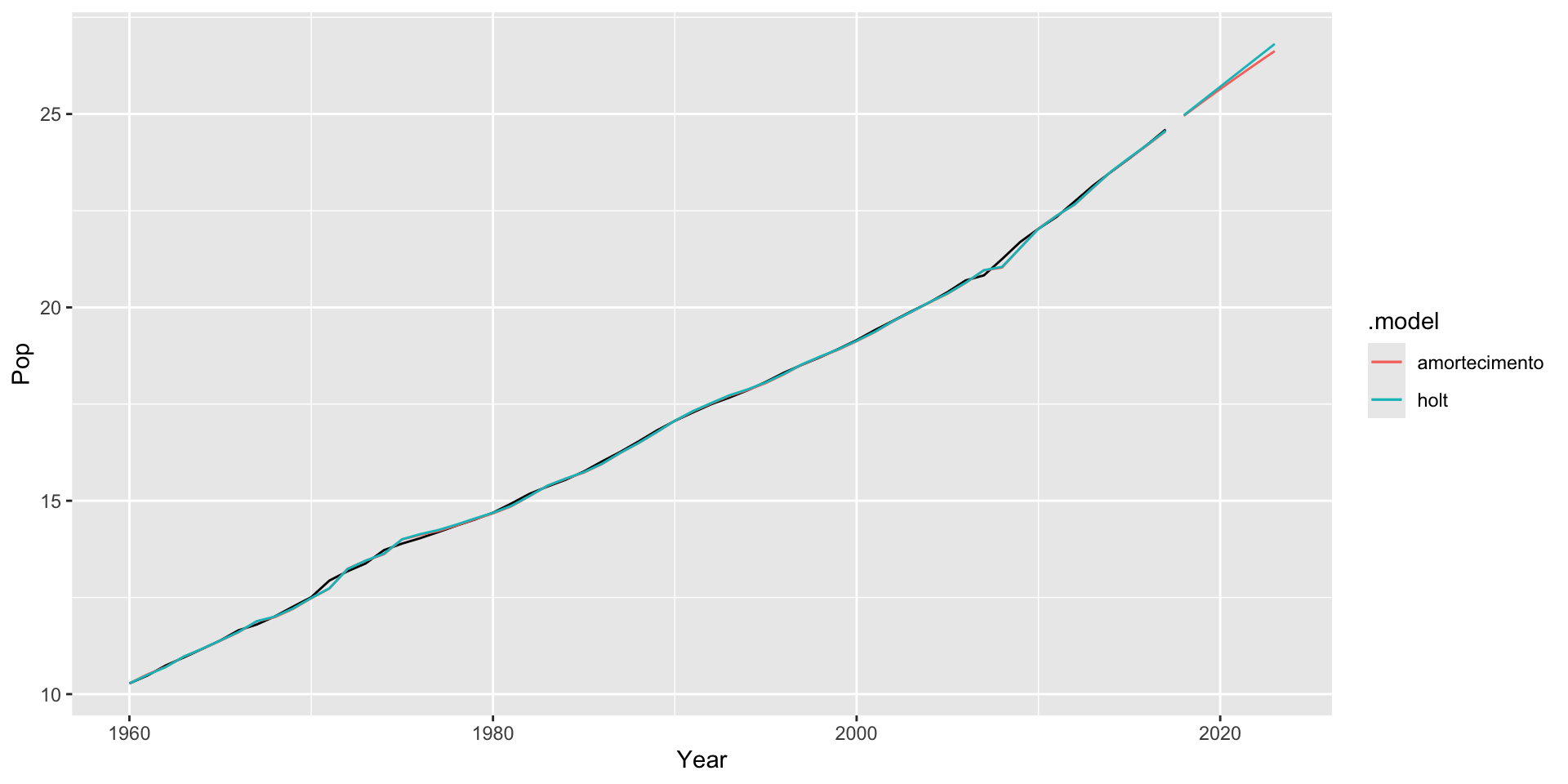
Code
Damped Holt's method
Call:
holt(y = australia_economy_ts, h = 6, damped = TRUE, initial = "optimal")
Smoothing parameters:
alpha = 0.9984
beta = 0.4272
phi = 0.98
Initial states:
l = 10.0365
b = 0.2478
sigma: 0.0672
AIC AICc BIC
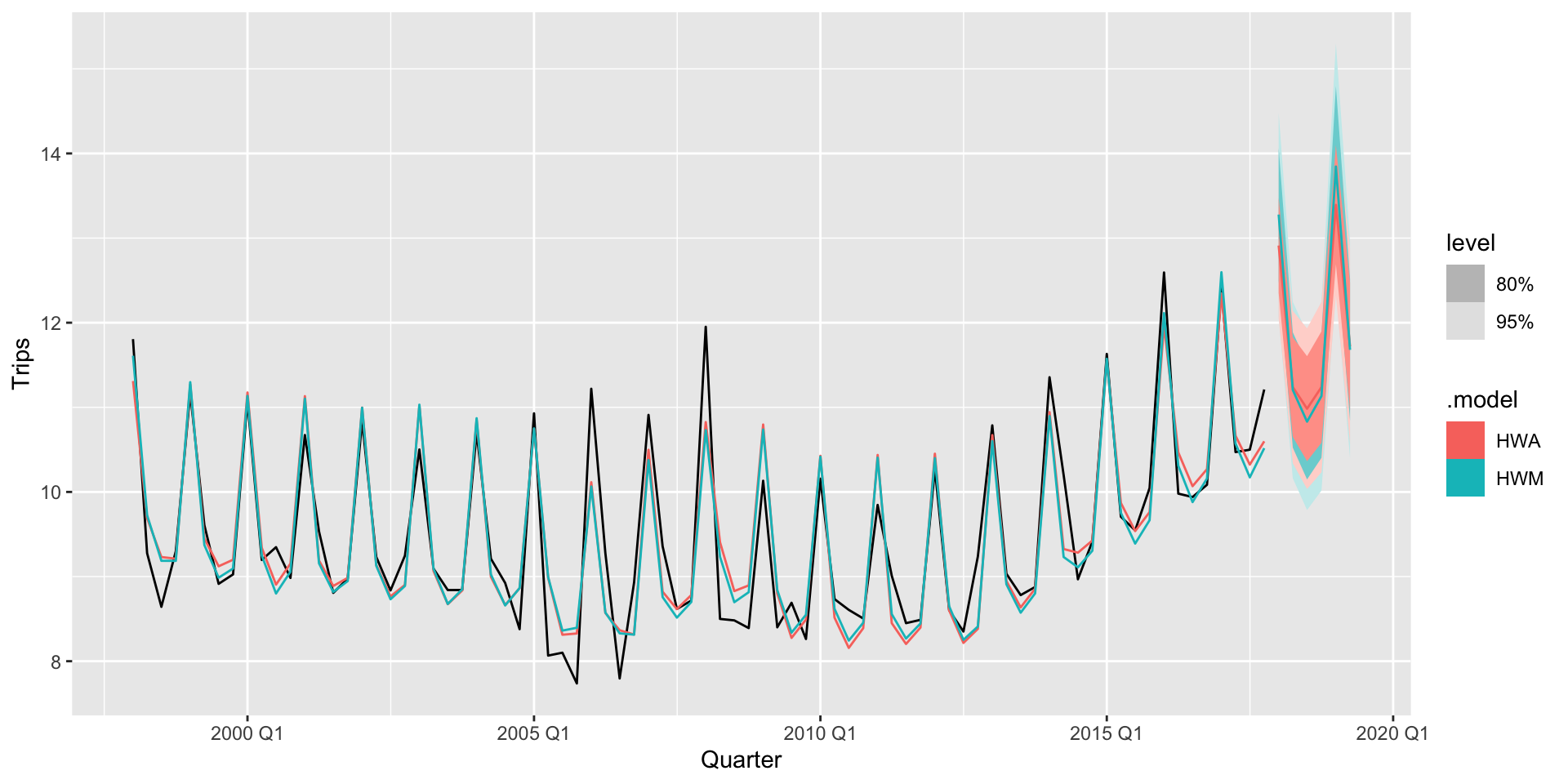
-71.01628 -69.36923 -58.65363 Método de Holt-Winters
Code
Rows: 80
Columns: 2
$ Quarter <qtr> 1998 Q1, 1998 Q2, 1998 Q3, 1998 Q4, 1999 Q1, 1999 Q2, 1999 Q3,…
$ Trips <dbl> 11.806038, 9.275662, 8.642489, 9.299524, 11.172027, 9.607613, …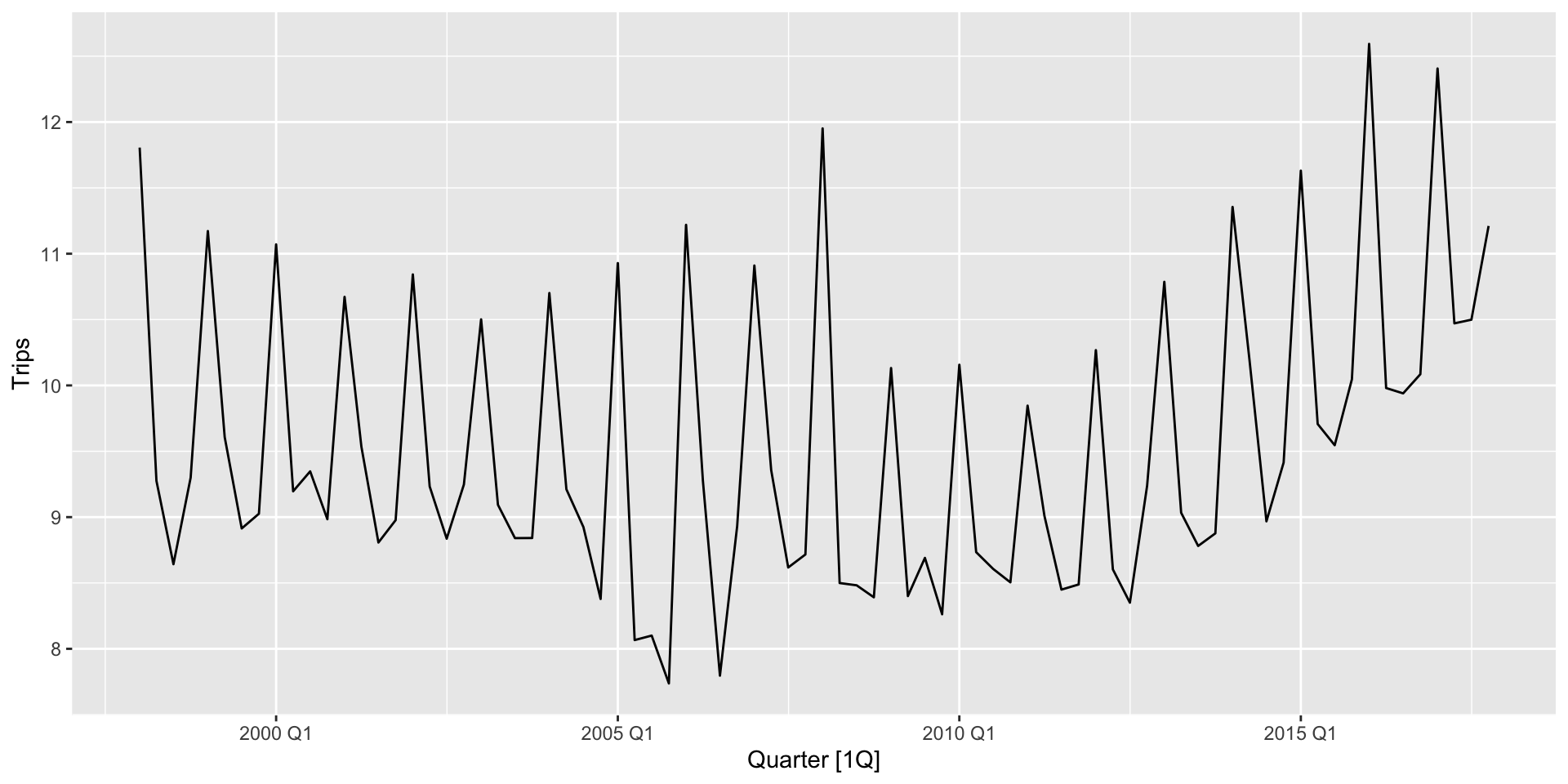
Code
Series: Trips
Model: ETS(A,A,A)
Smoothing parameters:
alpha = 0.2620382
beta = 0.04314266
gamma = 0.0001000312
Initial states:
l[0] b[0] s[0] s[-1] s[-2] s[-3]
9.791341 0.02106875 -0.534408 -0.6697662 -0.2937802 1.497954
sigma^2: 0.1931
AIC AICc BIC
228.5676 231.1390 250.0058 Series: Trips
Model: ETS(M,A,M)
Smoothing parameters:
alpha = 0.2236926
beta = 0.03042124
gamma = 0.0001000009
Initial states:
l[0] b[0] s[0] s[-1] s[-2] s[-3]
10.01351 -0.01141645 0.9430572 0.9270043 0.9692079 1.160731
sigma^2: 0.0021
AIC AICc BIC
226.7196 229.2910 248.1578 # A fable: 12 x 4 [1Q]
# Key: .model [2]
.model Quarter
<chr> <qtr>
1 HWA 2018 Q1
2 HWA 2018 Q2
3 HWA 2018 Q3
4 HWA 2018 Q4
5 HWA 2019 Q1
6 HWA 2019 Q2
7 HWM 2018 Q1
8 HWM 2018 Q2
9 HWM 2018 Q3
10 HWM 2018 Q4
11 HWM 2019 Q1
12 HWM 2019 Q2
# ℹ 2 more variables: Trips <dist>, .mean <dbl>