| dias | D1 | D2 | D3 | D4 | D5 | D6 |
|---|---|---|---|---|---|---|
| Segunda | 1 | 0 | 0 | 0 | 0 | 0 |
| Terça | 0 | 1 | 0 | 0 | 0 | 0 |
| Quarta | 0 | 0 | 1 | 0 | 0 | 0 |
| Quinta | 0 | 0 | 0 | 1 | 0 | 0 |
| Sexta | 0 | 0 | 0 | 0 | 1 | 0 |
| Sábado | 0 | 0 | 0 | 0 | 0 | 1 |
| Domingo | 0 | 0 | 0 | 0 | 0 | 0 |
| Segunda | 1 | 0 | 0 | 0 | 0 | 0 |
Modelos de regressão em dados de séries temporais II
ME607 - Séries Temporais
Tendência + Sazonalidade
The USgas series is a ts object with 1 variable and 238 observations
Frequency: 12
Start time: 2000 1
End time: 2019 10 Code
Features engineering | Data Wrangling
ds y
1 2000-01-01 2510.5
2 2000-02-01 2330.7
3 2000-03-01 2050.6
4 2000-04-01 1783.3
5 2000-05-01 1632.9
6 2000-06-01 1513.1Code
ds y trend seasonal
1 2000-01-01 2510.5 1 Jan
2 2000-02-01 2330.7 2 Feb
3 2000-03-01 2050.6 3 Mar
4 2000-04-01 1783.3 4 Apr
5 2000-05-01 1632.9 5 May
6 2000-06-01 1513.1 6 Jun
Call:
lm(formula = y ~ seasonal + trend + I(trend^2), data = USgas_df)
Residuals:
Min 1Q Median 3Q Max
-473.54 -55.44 -0.79 63.31 285.69
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.648e+03 3.166e+01 83.653 < 2e-16 ***
seasonalFeb -3.058e+02 3.476e+01 -8.799 3.77e-16 ***
seasonalMar -4.857e+02 3.476e+01 -13.974 < 2e-16 ***
seasonalApr -9.283e+02 3.476e+01 -26.709 < 2e-16 ***
seasonalMay -1.109e+03 3.476e+01 -31.912 < 2e-16 ***
seasonalJun -1.129e+03 3.476e+01 -32.469 < 2e-16 ***
seasonalJul -9.591e+02 3.476e+01 -27.591 < 2e-16 ***
seasonalAug -9.366e+02 3.476e+01 -26.943 < 2e-16 ***
seasonalSep -1.141e+03 3.477e+01 -32.829 < 2e-16 ***
seasonalOct -1.044e+03 3.477e+01 -30.017 < 2e-16 ***
seasonalNov -7.927e+02 3.522e+01 -22.507 < 2e-16 ***
seasonalDec -2.683e+02 3.522e+01 -7.618 7.18e-13 ***
trend -1.560e+00 4.168e-01 -3.743 0.000231 ***
I(trend^2) 1.869e-02 1.689e-03 11.063 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 109.9 on 224 degrees of freedom
Multiple R-squared: 0.9412, Adjusted R-squared: 0.9377
F-statistic: 275.6 on 13 and 224 DF, p-value: < 2.2e-16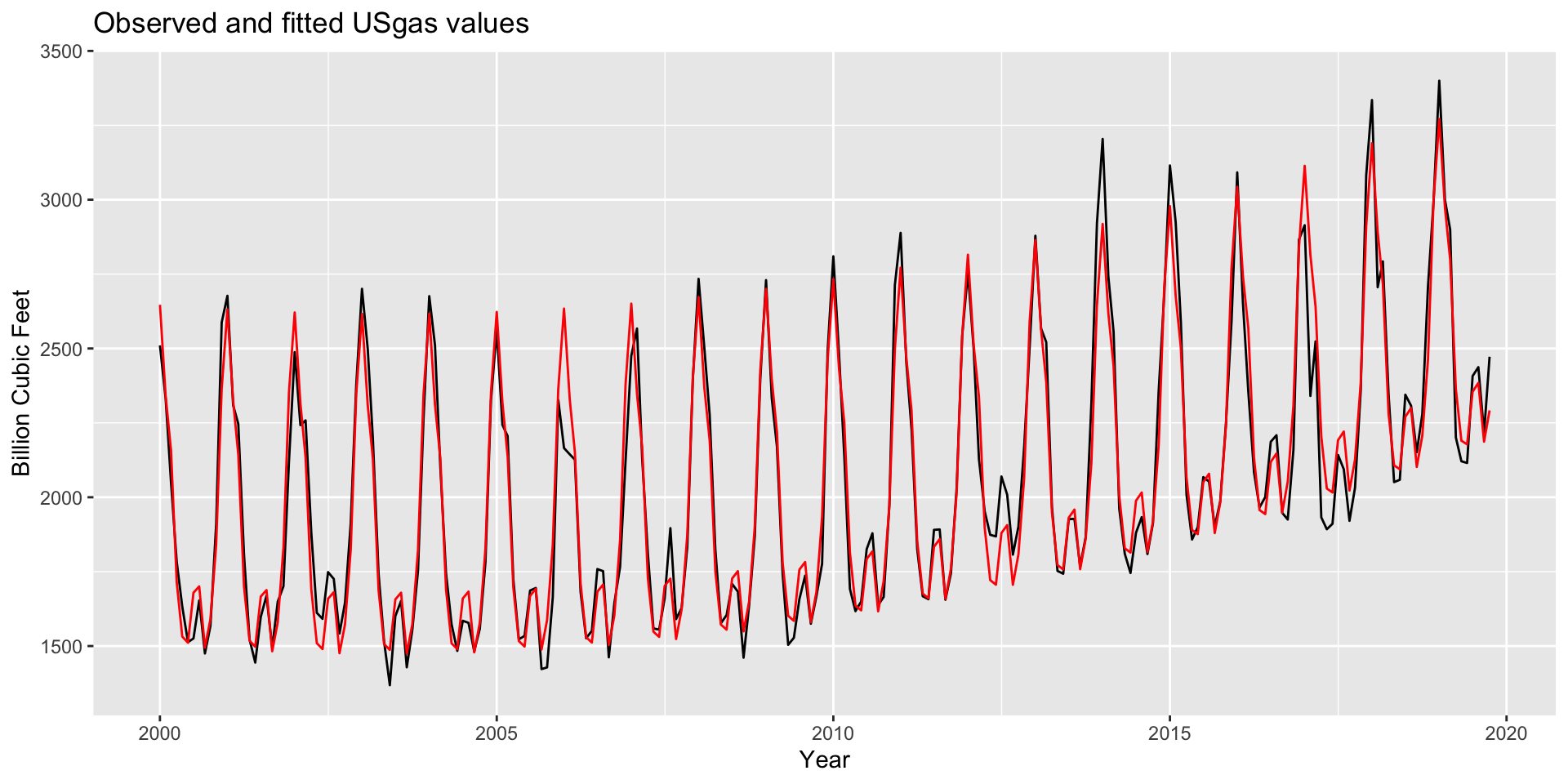
Code
Call:
tslm(formula = USgas ~ season + trend + I(trend^2))
Residuals:
Min 1Q Median 3Q Max
-473.54 -55.44 -0.79 63.31 285.69
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.648e+03 3.166e+01 83.653 < 2e-16 ***
season2 -3.058e+02 3.476e+01 -8.799 3.77e-16 ***
season3 -4.857e+02 3.476e+01 -13.974 < 2e-16 ***
season4 -9.283e+02 3.476e+01 -26.709 < 2e-16 ***
season5 -1.109e+03 3.476e+01 -31.912 < 2e-16 ***
season6 -1.129e+03 3.476e+01 -32.469 < 2e-16 ***
season7 -9.591e+02 3.476e+01 -27.591 < 2e-16 ***
season8 -9.366e+02 3.476e+01 -26.943 < 2e-16 ***
season9 -1.141e+03 3.477e+01 -32.829 < 2e-16 ***
season10 -1.044e+03 3.477e+01 -30.017 < 2e-16 ***
season11 -7.927e+02 3.522e+01 -22.507 < 2e-16 ***
season12 -2.683e+02 3.522e+01 -7.618 7.18e-13 ***
trend -1.560e+00 4.168e-01 -3.743 0.000231 ***
I(trend^2) 1.869e-02 1.689e-03 11.063 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 109.9 on 224 degrees of freedom
Multiple R-squared: 0.9412, Adjusted R-squared: 0.9377
F-statistic: 275.6 on 13 and 224 DF, p-value: < 2.2e-16Tendência + Sazonalidade
Produção trimestral de cerveja na Australia

Contruiremos um modelo da forma \[Beer_t = \beta_0 + \beta_1 t + \beta_2 D_{2,t} + \beta_3 D_{3,t} + \beta_4 D_{4,t} + \epsilon_t,\] em que \(D_{i,t} = 1\) se \(t \in\) Trimestre \(i\) e 0, caso contrário.
Tendência + Sazonalidade: Dummy
Code
augment(modelo_dummy) %>%
ggplot(aes(x = Quarter)) +
geom_line(aes(y = Beer, colour = "Data")) +
geom_line(aes(y = .fitted, colour = "Fitted")) +
scale_colour_manual(values = c(Data = "black", Fitted = "red")) + ylab("Megalitros") + xlab("Trimestre") + ggtitle("Produção trimestral de cerveja australiana") +
guides(colour = guide_legend(title = "Séries"))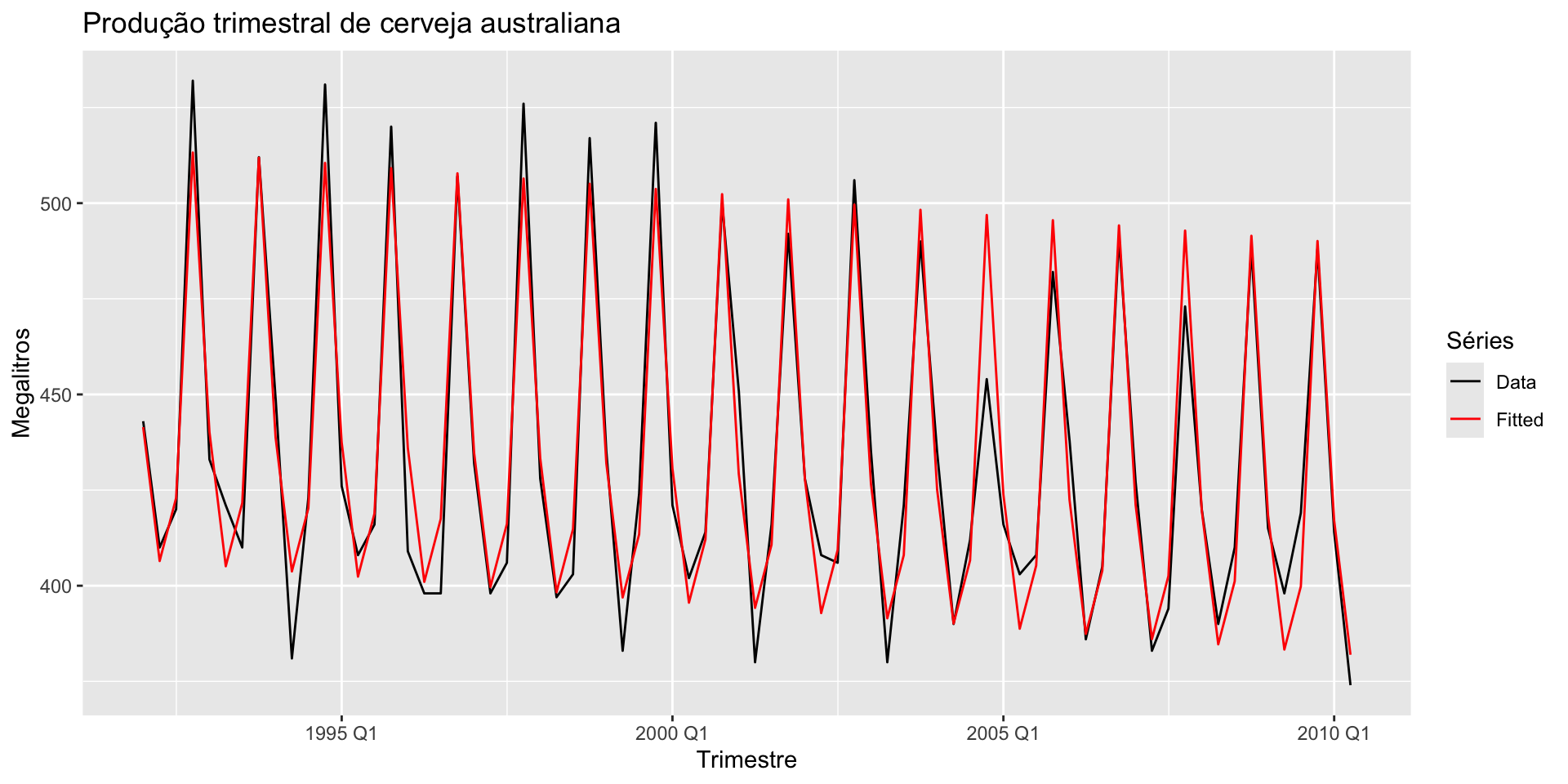
Tendência + Sazonalidade: Fourier
Code
augment(modelo_fourier) %>%
ggplot(aes(x = Quarter)) +
geom_line(aes(y = Beer, colour = "Data")) +
geom_line(aes(y = .fitted, colour = "Fitted")) +
scale_colour_manual(values = c(Data = "black", Fitted = "blue")) + ylab("Megalitros") + xlab("Trimestre") + ggtitle("Produção trimestral de cerveja australiana") +
guides(colour = guide_legend(title = "Séries"))
Tendência + Sazonalidade: Diagnóstico
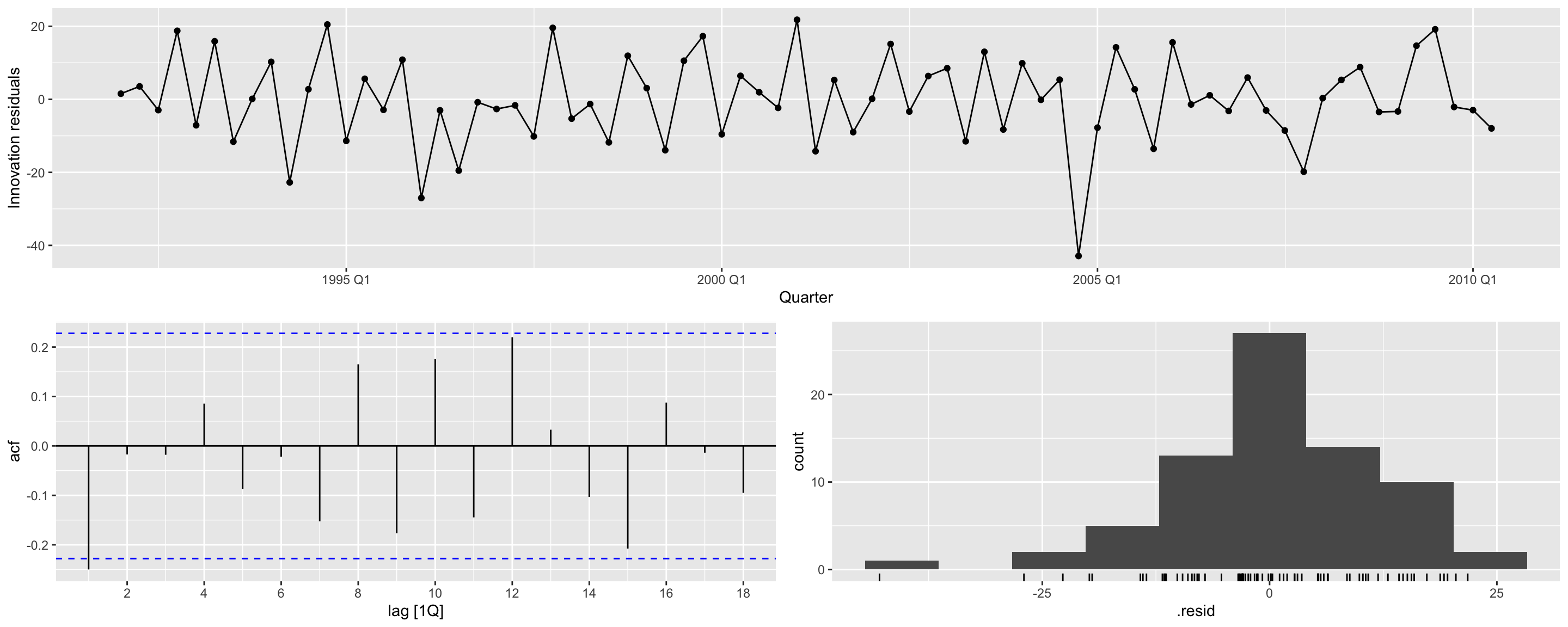
# A tibble: 5 × 6
.model term estimate std.error statistic p.value
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 TSLM(Beer ~ trend() + season()) (Interc… 442. 3.73 118. 2.02e-81
2 TSLM(Beer ~ trend() + season()) trend() -0.340 0.0666 -5.11 2.73e- 6
3 TSLM(Beer ~ trend() + season()) season(… -34.7 3.97 -8.73 9.10e-13
4 TSLM(Beer ~ trend() + season()) season(… -17.8 4.02 -4.43 3.45e- 5
5 TSLM(Beer ~ trend() + season()) season(… 72.8 4.02 18.1 6.68e-28# A tibble: 1 × 3
.model bp_stat bp_pvalue
<chr> <dbl> <dbl>
1 TSLM(Beer ~ trend() + season()) 9.53 0.0230# A tibble: 1 × 3
.model lb_stat lb_pvalue
<chr> <dbl> <dbl>
1 TSLM(Beer ~ trend() + season()) 10.4 0.0157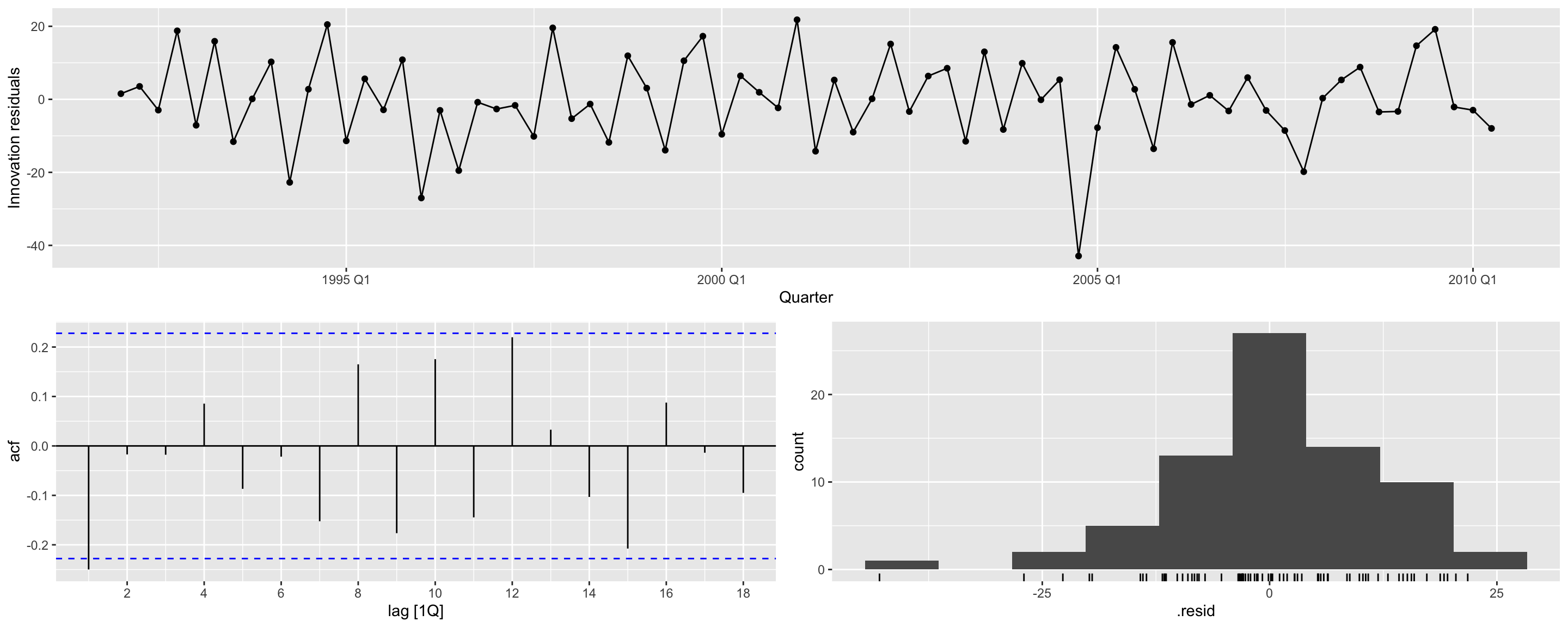
# A tibble: 5 × 6
.model term estimate std.error statistic p.value
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 TSLM(Beer ~ trend() + fourier(K =… (Int… 447. 2.87 156. 1.39e-89
2 TSLM(Beer ~ trend() + fourier(K =… tren… -0.340 0.0666 -5.11 2.73e- 6
3 TSLM(Beer ~ trend() + fourier(K =… four… 8.91 2.01 4.43 3.45e- 5
4 TSLM(Beer ~ trend() + fourier(K =… four… -53.7 2.01 -26.7 4.10e-38
5 TSLM(Beer ~ trend() + fourier(K =… four… -14.0 1.42 -9.83 9.26e-15# A tibble: 1 × 3
.model bp_stat bp_pvalue
<chr> <dbl> <dbl>
1 TSLM(Beer ~ trend() + fourier(K = 2)) 9.53 0.0230# A tibble: 1 × 3
.model lb_stat lb_pvalue
<chr> <dbl> <dbl>
1 TSLM(Beer ~ trend() + fourier(K = 2)) 10.4 0.0157Previsão

- Temos visto como usar modelos de regressão em um contexto de séries temporias, mas nada foi dito sobre como fazer previsão \(h\) passos à frente.
- Sabemos que, com os \(\hat{\beta}s\), podemos obter os valores estimados \(\hat{y}_t\) ( \(t = 1, \ldots, T\)) através da equação \[\hat{y}_t = \hat{\beta}_0 + \hat{\beta}_1 x_{1,t} + \cdots + \hat{\beta}_k x_{k,t}.\]
Previsão
Utilizando o dataset aus_production do pacote fpp3, faremos a previsão \(h = 12\) passos à frente da produção de cerveja (Beer) na Austrália.
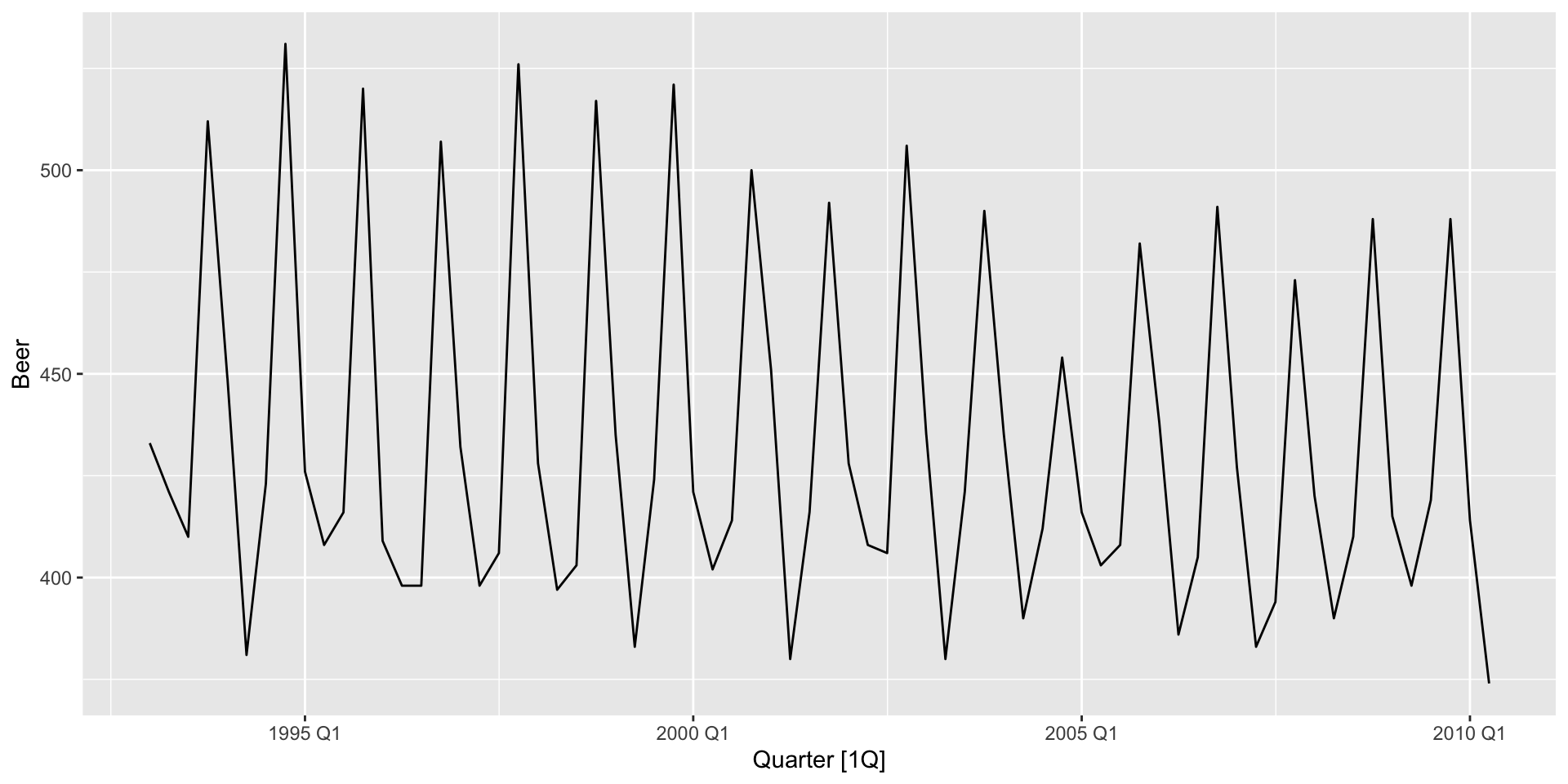
Series: Beer
Model: TSLM
Residuals:
Min 1Q Median 3Q Max
-42.1193 -7.7552 -0.5074 7.7665 22.3373
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 439.41993 3.87255 113.471 < 2e-16 ***
trend() -0.31359 0.07303 -4.294 5.98e-05 ***
season()year2 -34.79753 4.11473 -8.457 4.51e-12 ***
season()year3 -17.56209 4.17414 -4.207 8.09e-05 ***
season()year4 71.75149 4.17478 17.187 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 12.34 on 65 degrees of freedom
Multiple R-squared: 0.9213, Adjusted R-squared: 0.9164
F-statistic: 190.1 on 4 and 65 DF, p-value: < 2.22e-16# A fable: 12 x 4 [1Q]
# Key: .model [1]
.model Quarter
<chr> <qtr>
1 TSLM(Beer ~ trend() + season()) 2010 Q3
2 TSLM(Beer ~ trend() + season()) 2010 Q4
3 TSLM(Beer ~ trend() + season()) 2011 Q1
4 TSLM(Beer ~ trend() + season()) 2011 Q2
5 TSLM(Beer ~ trend() + season()) 2011 Q3
6 TSLM(Beer ~ trend() + season()) 2011 Q4
7 TSLM(Beer ~ trend() + season()) 2012 Q1
8 TSLM(Beer ~ trend() + season()) 2012 Q2
9 TSLM(Beer ~ trend() + season()) 2012 Q3
10 TSLM(Beer ~ trend() + season()) 2012 Q4
11 TSLM(Beer ~ trend() + season()) 2013 Q1
12 TSLM(Beer ~ trend() + season()) 2013 Q2
# ℹ 2 more variables: Beer <dist>, .mean <dbl>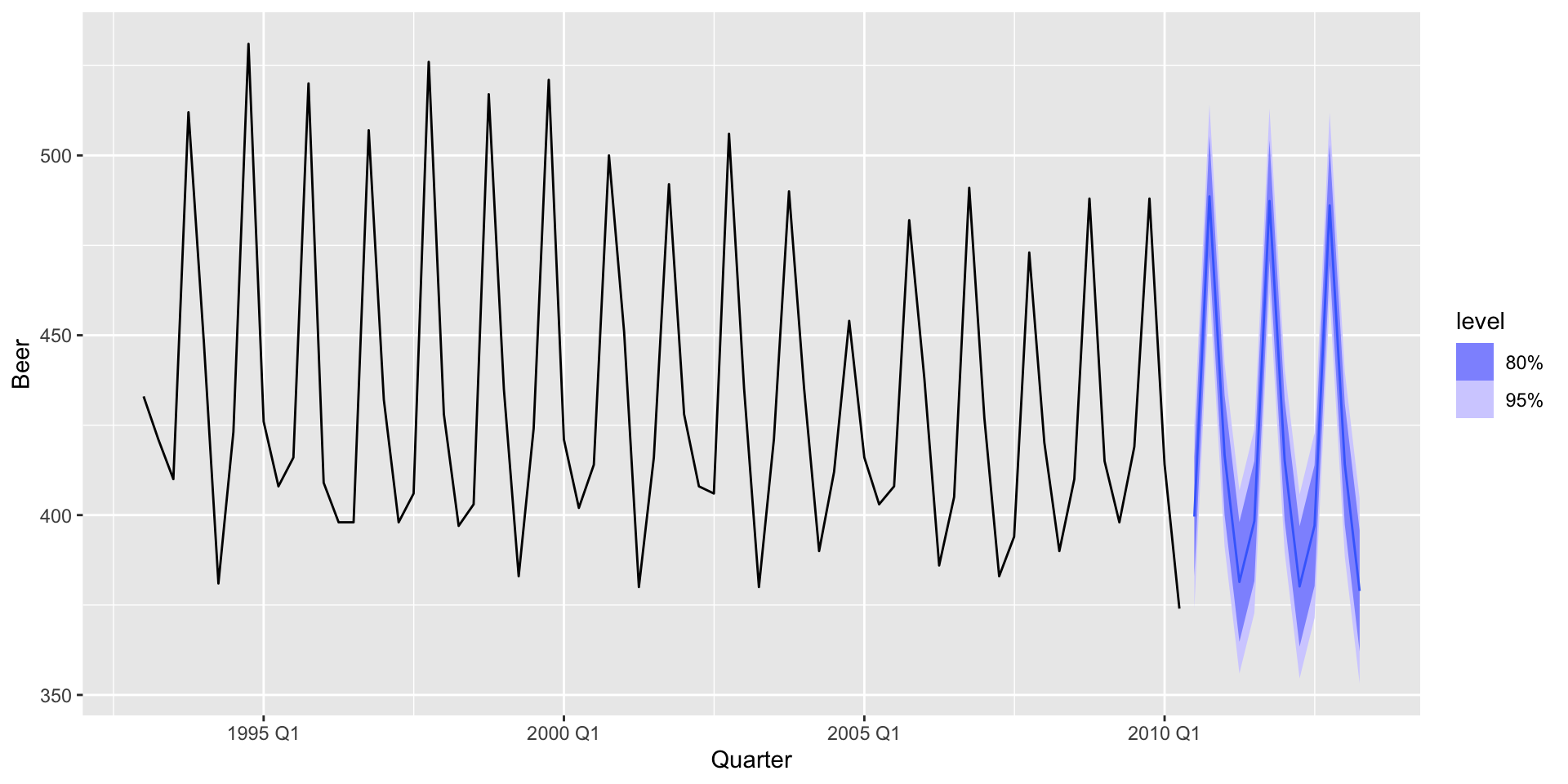
Previsão
O modelo que estou utilizando tem variáveis que não são determinísticas, e agora?

- Utilizar previsões das variáveis preditoras utilizadas no modelo.
- Trabalhar com cenários.
Previsão
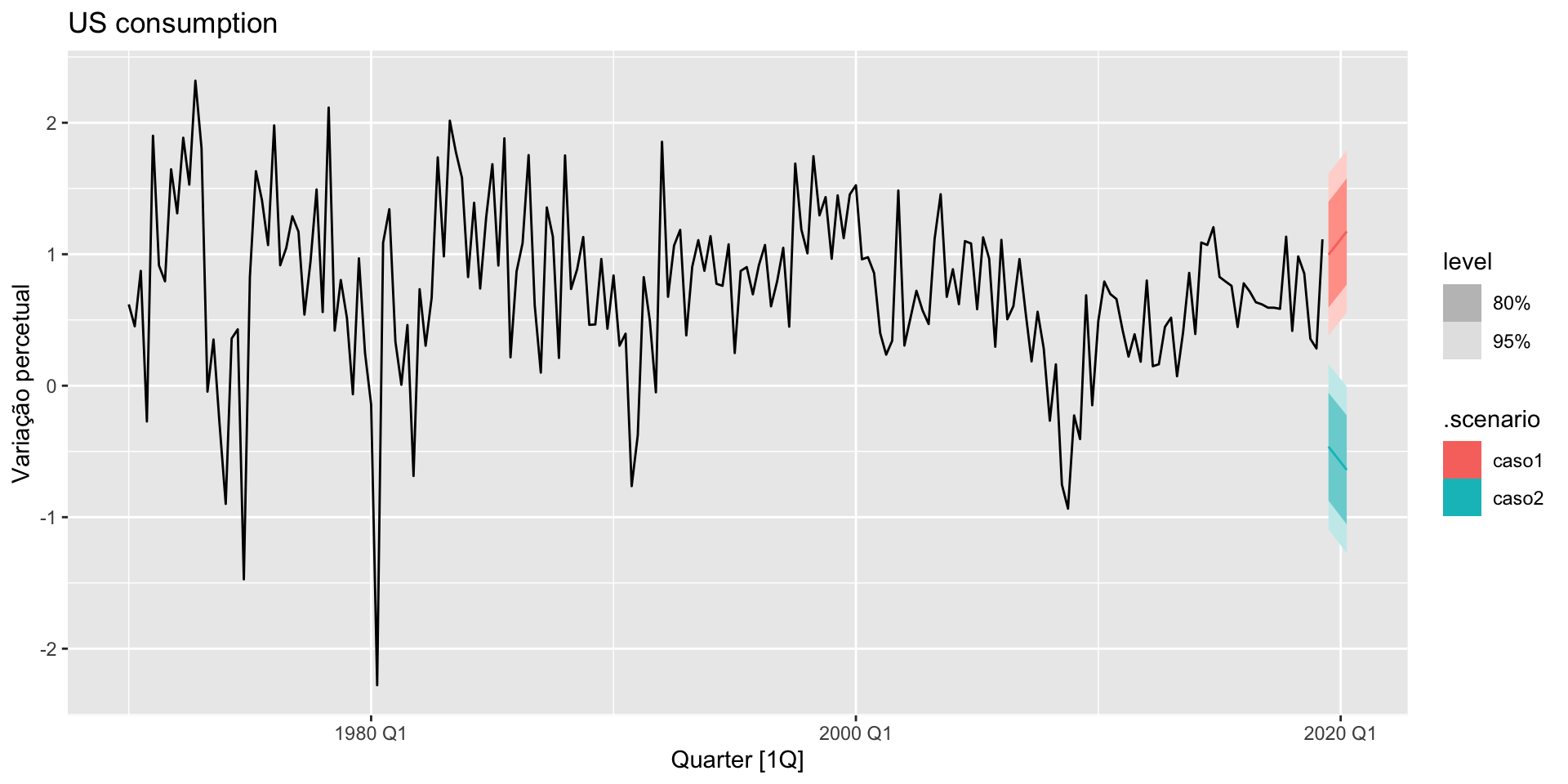
Não lineariedades
O dataset boston_marathon do pacote fpp3 contém informações sobre o tempo (em segundos) dos ganhadores da maratona ao longo dos anos de 5 categorias diferentes.
Code
Rows: 123
Columns: 2
$ Year <int> 1897, 1898, 1899, 1900, 1901, 1902, 1903, 1904, 1905, 1906, 19…
$ Minutos <dbl> 175.1667, 162.0000, 174.6333, 159.7333, 149.3833, 163.2000, 16…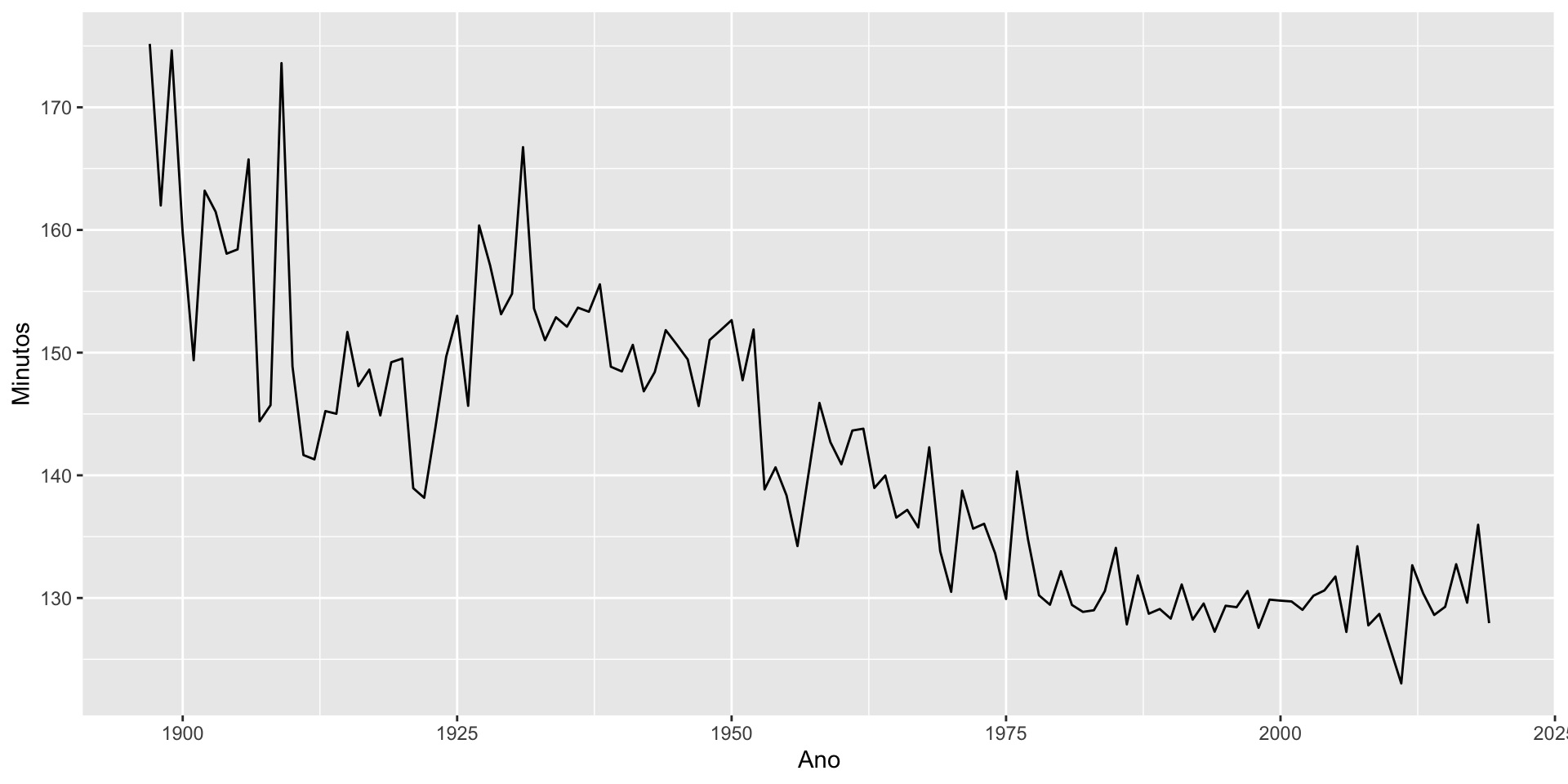
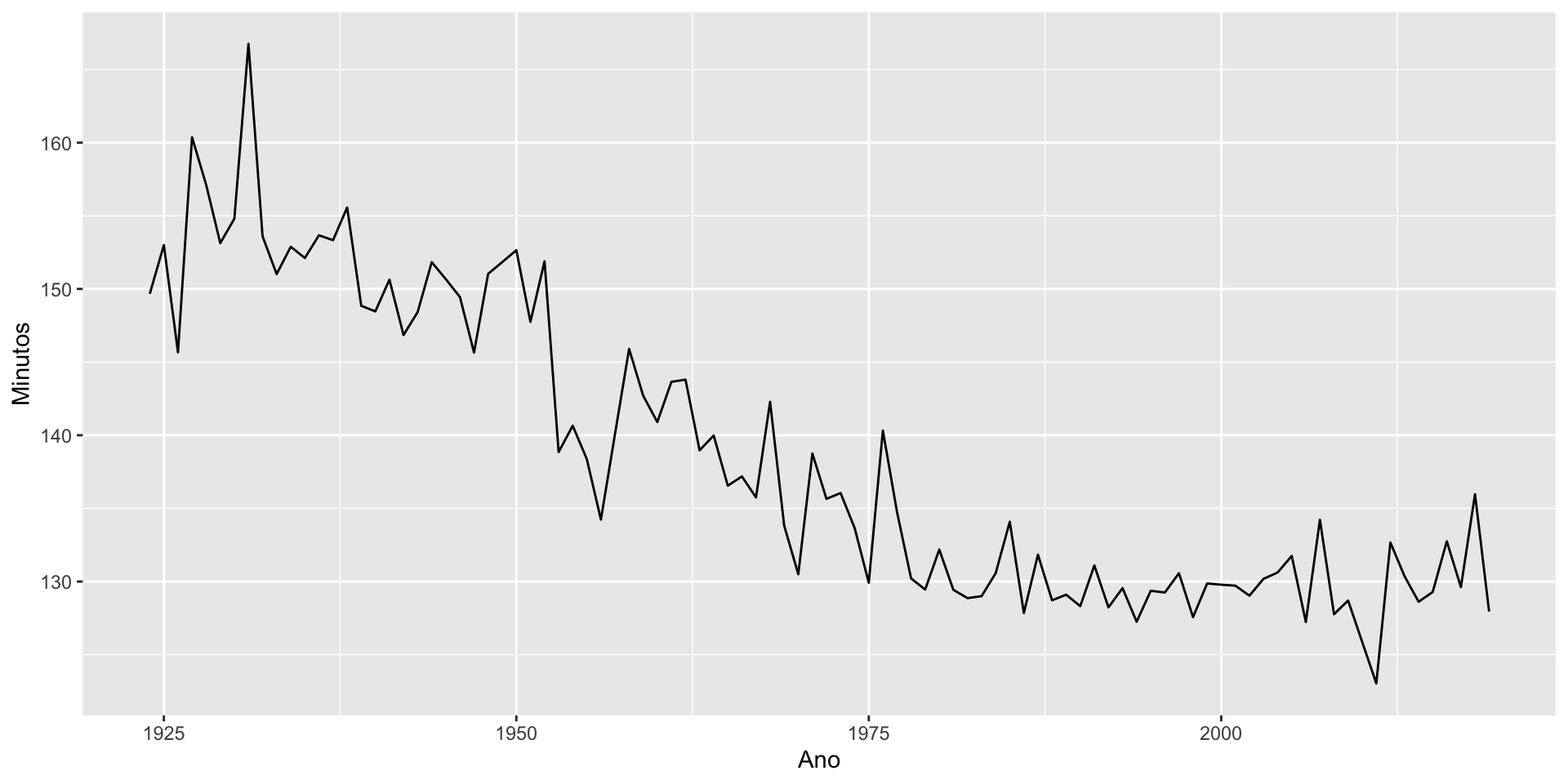
Code
# A fable: 36 x 4 [1Y]
# Key: .model [3]
.model Year
<chr> <dbl>
1 linear 2020
2 linear 2021
3 linear 2022
4 linear 2023
5 linear 2024
6 linear 2025
7 linear 2026
8 linear 2027
9 linear 2028
10 linear 2029
# ℹ 26 more rows
# ℹ 2 more variables: Minutos <dist>, .mean <dbl>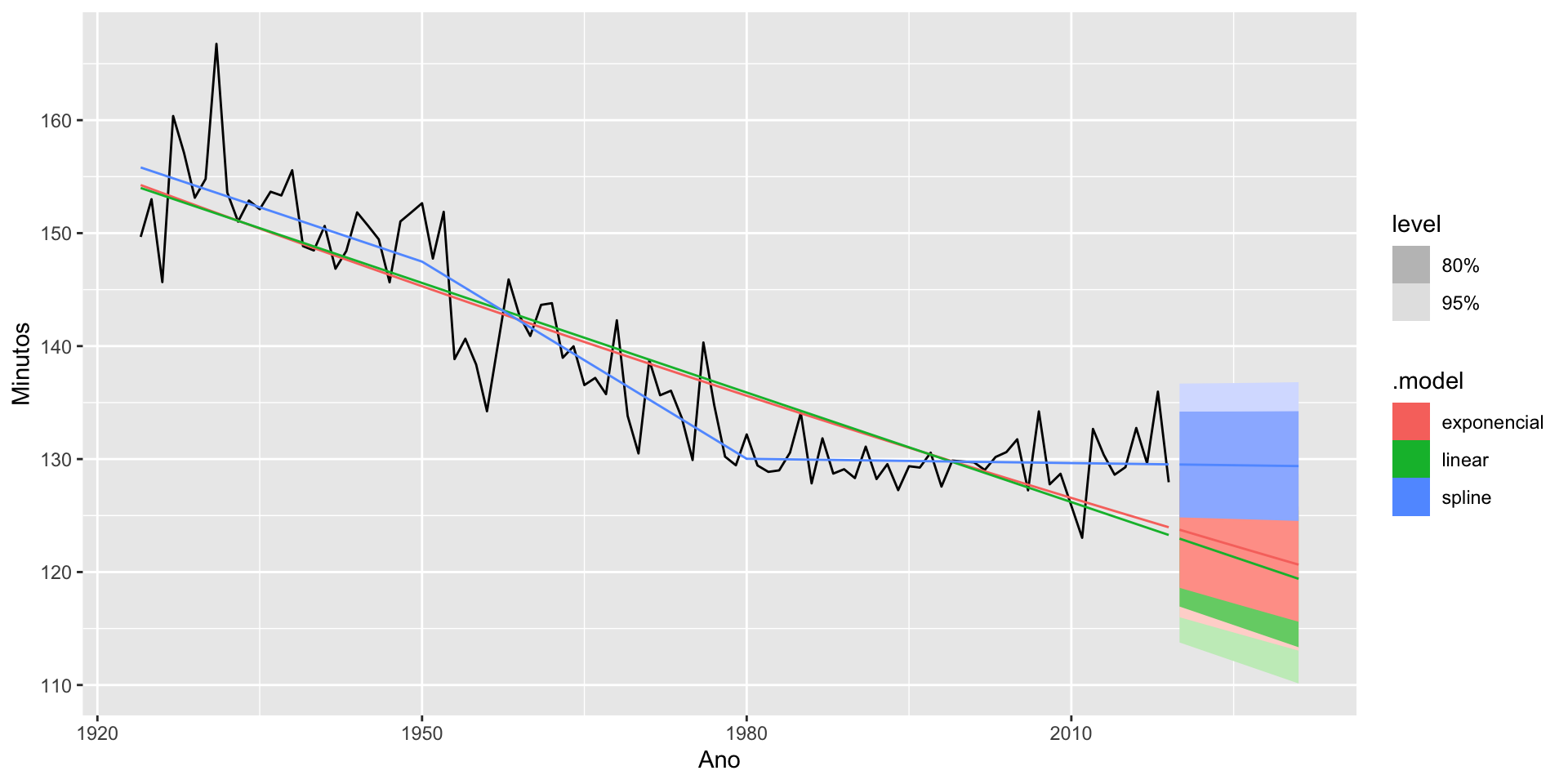
Quando trabalhamos com um modelo com splines, podemos passar no argumento knots tanto as posições exatas dos nós, quanto o número de nós. Nesse último caso, a posição do nó será calculada automaticamente.
Procedimentos automáticos ajudam, mas não estão isentos de erro.
