Rows: 198
Columns: 6
$ Quarter <qtr> 1970 Q1, 1970 Q2, 1970 Q3, 1970 Q4, 1971 Q1, 1971 Q2, 197…
$ Consumption <dbl> 0.61856640, 0.45198402, 0.87287178, -0.27184793, 1.901344…
$ Income <dbl> 1.0448013, 1.2256472, 1.5851538, -0.2395449, 1.9759249, 1…
$ Production <dbl> -2.45248553, -0.55145947, -0.35865175, -2.18569087, 1.909…
$ Savings <dbl> 5.2990141, 7.7898938, 7.4039841, 1.1698982, 3.5356669, 5.…
$ Unemployment <dbl> 0.9, 0.5, 0.5, 0.7, -0.1, -0.1, 0.1, 0.0, -0.2, -0.1, -0.…Modelos de regressão em dados de séries temporais
ME607 - Séries Temporais
Modelo de regressão em dados de séries temporais

- Verificadas as novas suposições, é só aplicar regressão como sempre?
- Sim, mas deve verificar as suposições!. É muito comúm encontrarmos falsos achados quando trabalhamos com modelos de regressão em dados de séries temporais.
Modelo de regressão em dados de séries temporais
Code
Series: Consumption
Model: TSLM
Residuals:
Min 1Q Median 3Q Max
-0.90555 -0.15821 -0.03608 0.13618 1.15471
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.253105 0.034470 7.343 5.71e-12 ***
Income 0.740583 0.040115 18.461 < 2e-16 ***
Production 0.047173 0.023142 2.038 0.0429 *
Savings -0.052890 0.002924 -18.088 < 2e-16 ***
Unemployment -0.174685 0.095511 -1.829 0.0689 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3102 on 193 degrees of freedom
Multiple R-squared: 0.7683, Adjusted R-squared: 0.7635
F-statistic: 160 on 4 and 193 DF, p-value: < 2.22e-16Code
library(ggplot2)
augment(modelo) |> select(Quarter, Consumption, .fitted) |>
pivot_longer(cols = c("Consumption", ".fitted"), values_to = "values", names_to = "serie") |> ggplot() +
geom_line(aes(x = Quarter, y = values, color = serie)) +
ggtitle("Variação percentual nas despesas de consumo USA. Período 1970.Q1 -- 2019.Q2")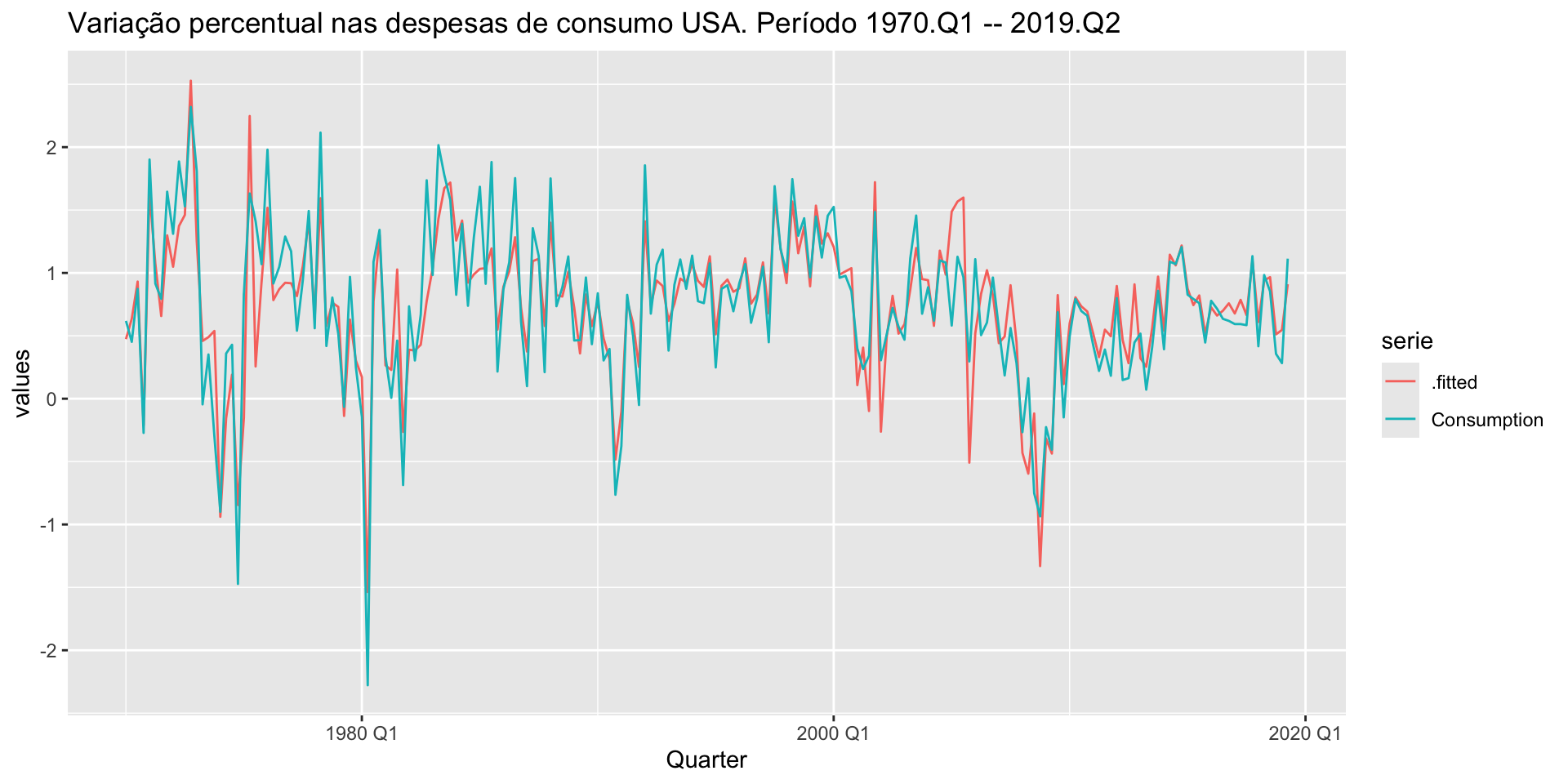
# A tibble: 5 × 6
.model term estimate std.error statistic p.value
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 TSLM(Consumption ~ Income + Produ… (Int… 0.253 0.0345 7.34 5.71e-12
2 TSLM(Consumption ~ Income + Produ… Inco… 0.741 0.0401 18.5 1.65e-44
3 TSLM(Consumption ~ Income + Produ… Prod… 0.0472 0.0231 2.04 4.29e- 2
4 TSLM(Consumption ~ Income + Produ… Savi… -0.0529 0.00292 -18.1 2.03e-43
5 TSLM(Consumption ~ Income + Produ… Unem… -0.175 0.0955 -1.83 6.89e- 2# A tibble: 1 × 3
.model bp_stat bp_pvalue
<chr> <dbl> <dbl>
1 TSLM(Consumption ~ Income + Production + Savings + Unemploy… 16.5 0.000879# A tibble: 1 × 3
.model lb_stat lb_pvalue
<chr> <dbl> <dbl>
1 TSLM(Consumption ~ Income + Production + Savings + Unemploy… 17.1 0.000671Por quê 8 e 5?
Regressões espúrias
Os datasets aus_airpassengers a guinea_rice do pacote fpp3, contém informações do número total de passageiros (em milhões) na Austrália e da produção anual de arroz (em milhões de toneladas) na Guiné, respectivamente.
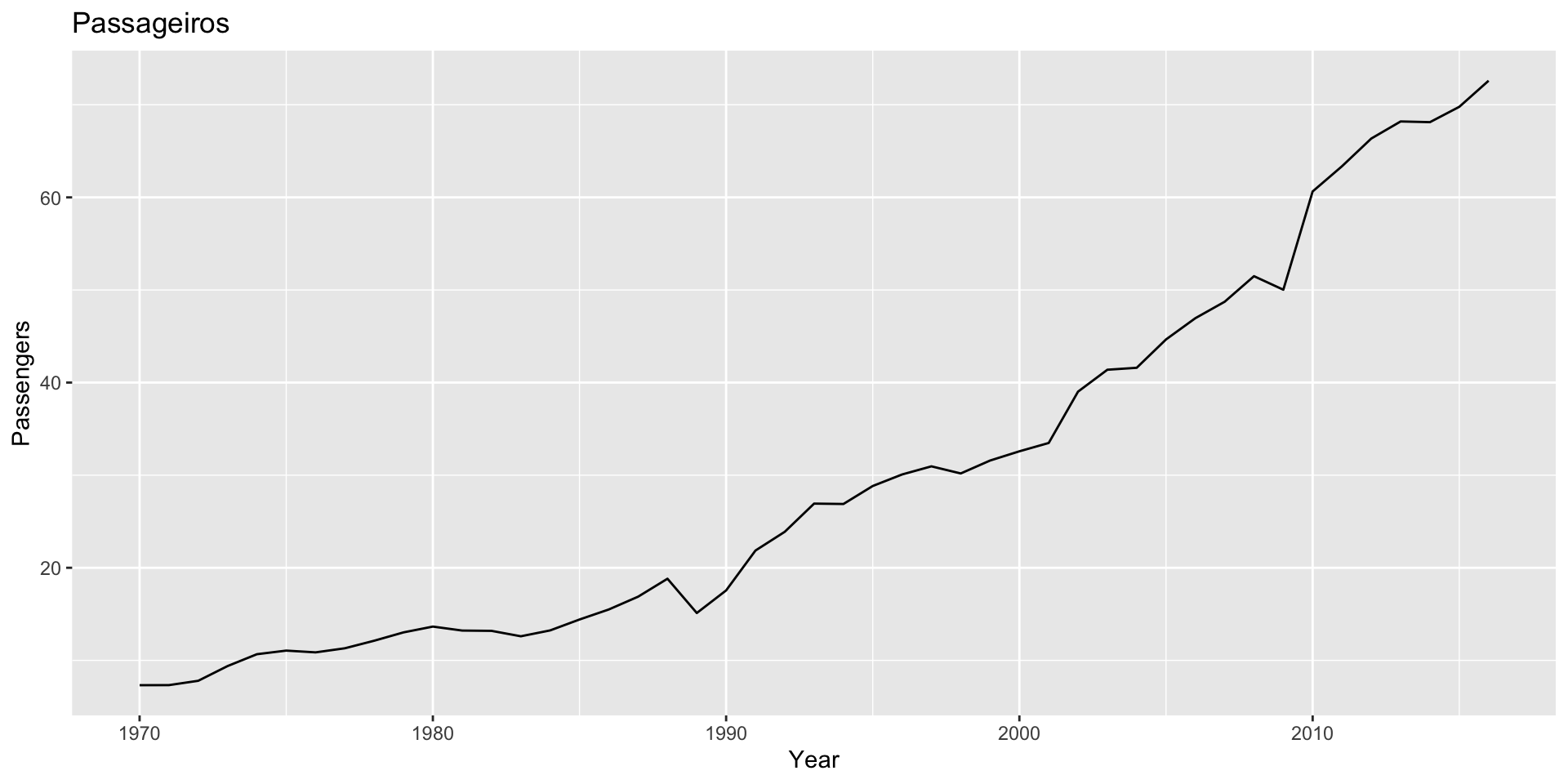
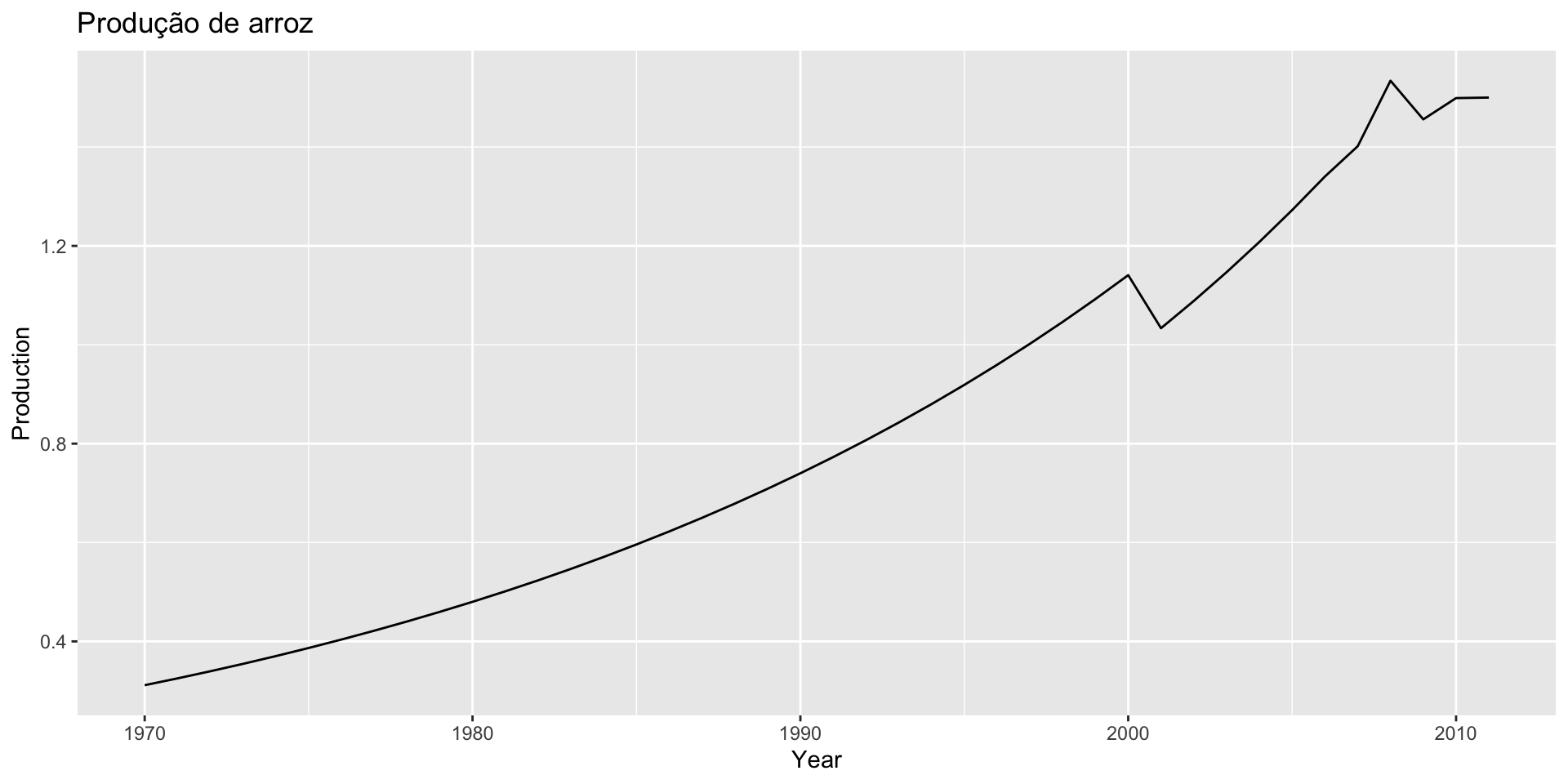
As séries não tem nenhuma relação, a não ser que ambas são não estacionárias.
Regressões espúrias
\[Passageiros= \beta_0 + \beta_1 \text{Produção de Arroz} + e\]
Code
Series: Passengers
Model: TSLM
Residuals:
Min 1Q Median 3Q Max
-5.9448 -1.8917 -0.3272 1.8620 10.4210
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -7.493 1.203 -6.229 2.25e-07 ***
Production 40.288 1.337 30.135 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.239 on 40 degrees of freedom
Multiple R-squared: 0.9578, Adjusted R-squared: 0.9568
F-statistic: 908.1 on 1 and 40 DF, p-value: < 2.22e-16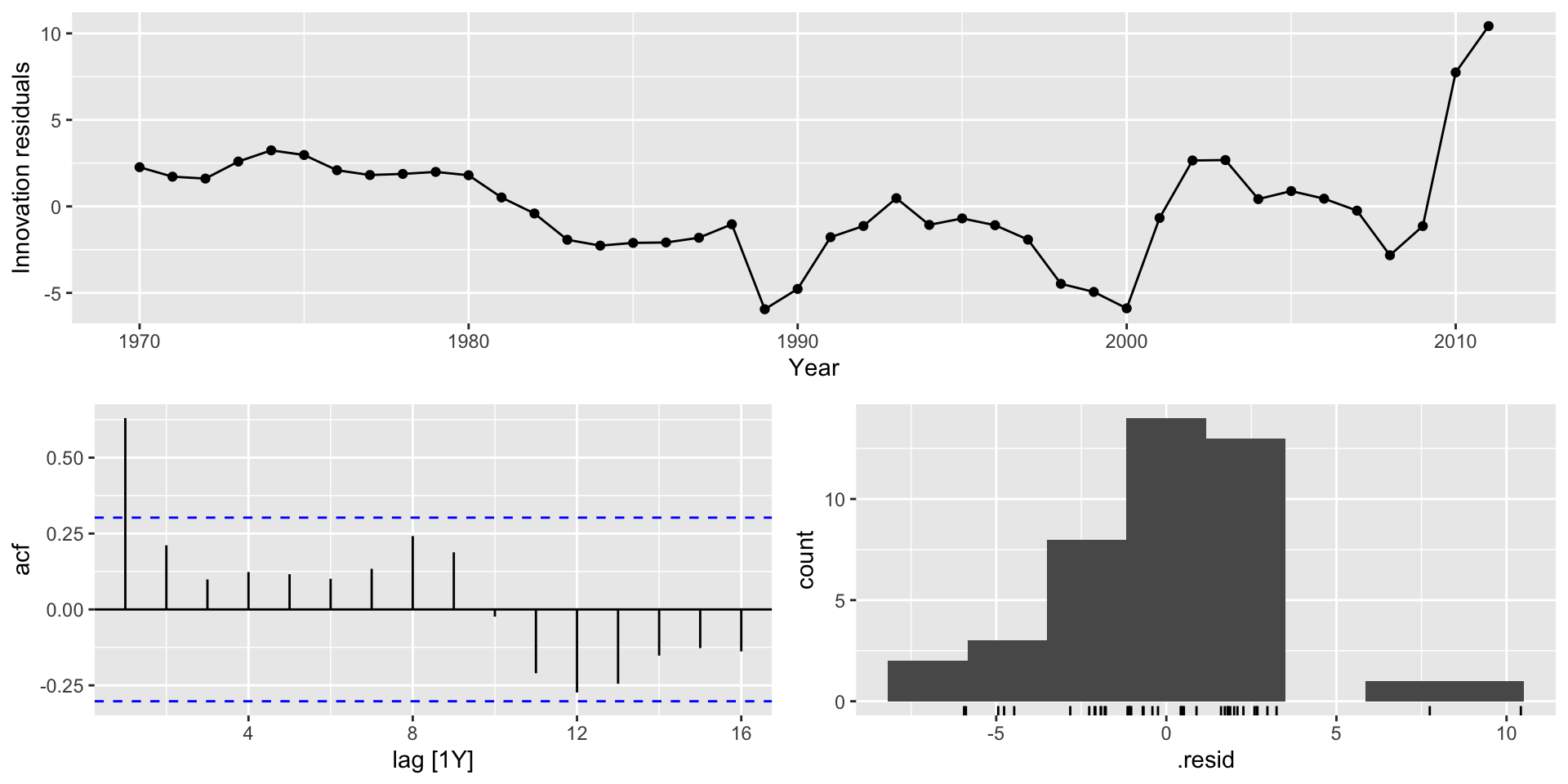
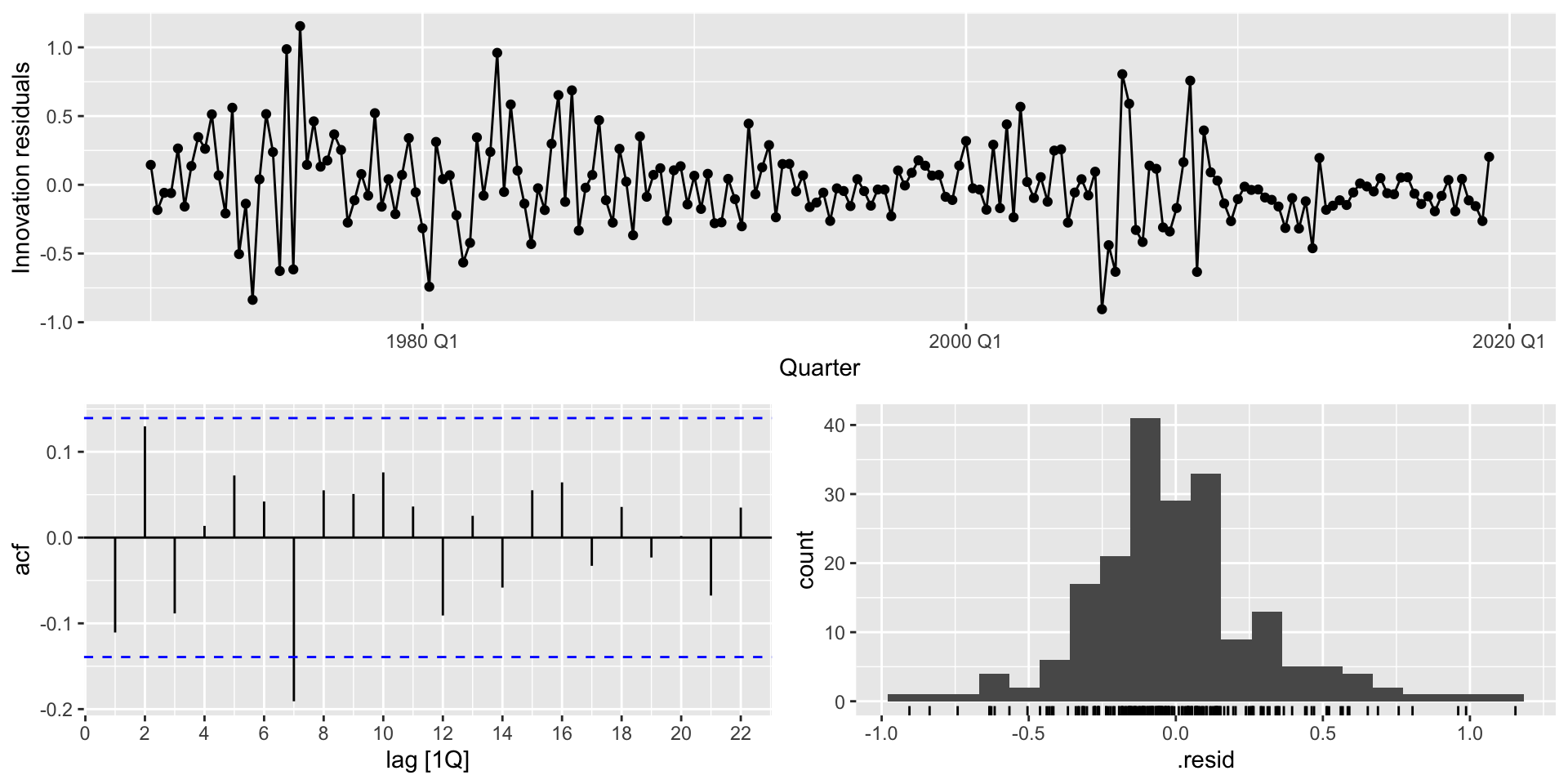
Aparentemente, temos um achado!! a cada unidade de aumento na produção de arroz na Guiné, o número de passageiros na Austrália aumenta em 40 unidades 🤣
Regressões espúrias
Mas, como sei se a série que estou utilizando é não estacionária?
- Lembre-se da definição da estacionariedade!.
- Graficamente, se a série tiver tendência e/ou a variabilidade aumentar (ou diminuir) ao longo do tempo, a série é não estacionária.
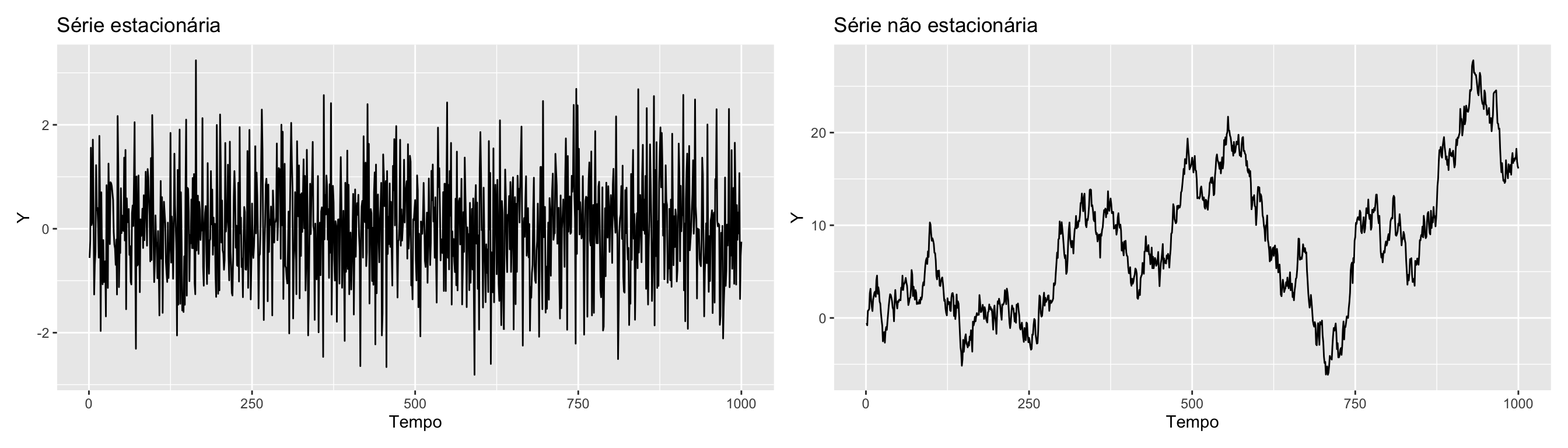
Regressões espúrias
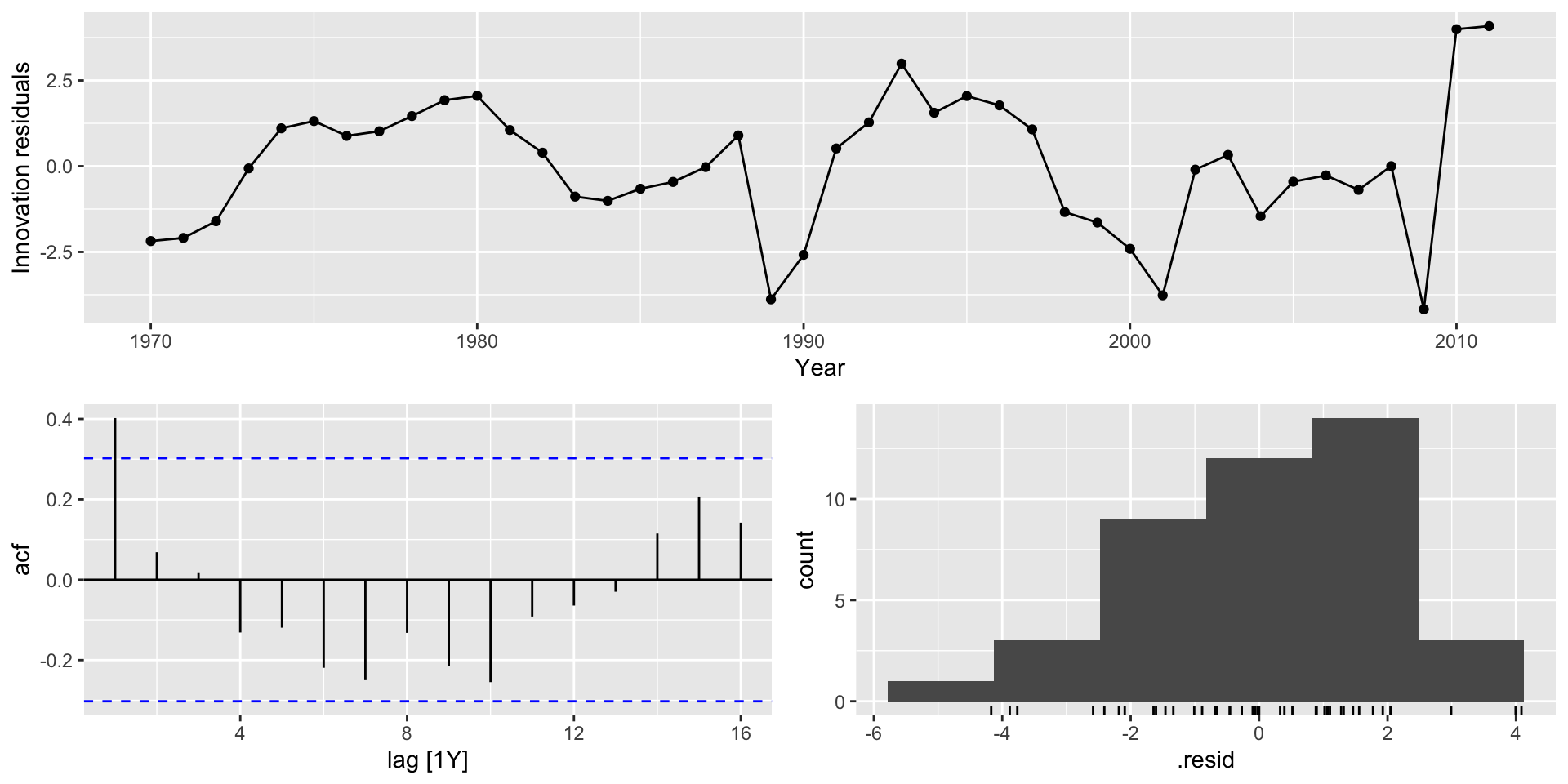
Às vezes, olhando para o gráfico da série temporal, não é facil de verificar se a série é não estacionária.
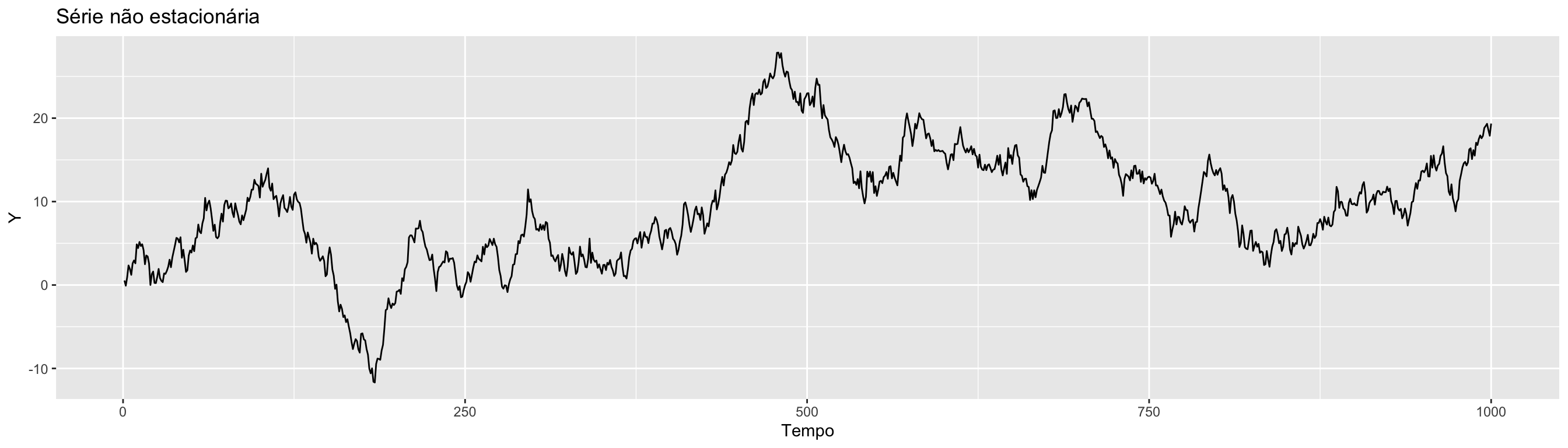
Gráfico alternativo: função de autocorrelação (correlograma): Se as autocorrelações forem significativas e cairem devagar 🐢 , a série é não estacionária.
Regressões espúrias
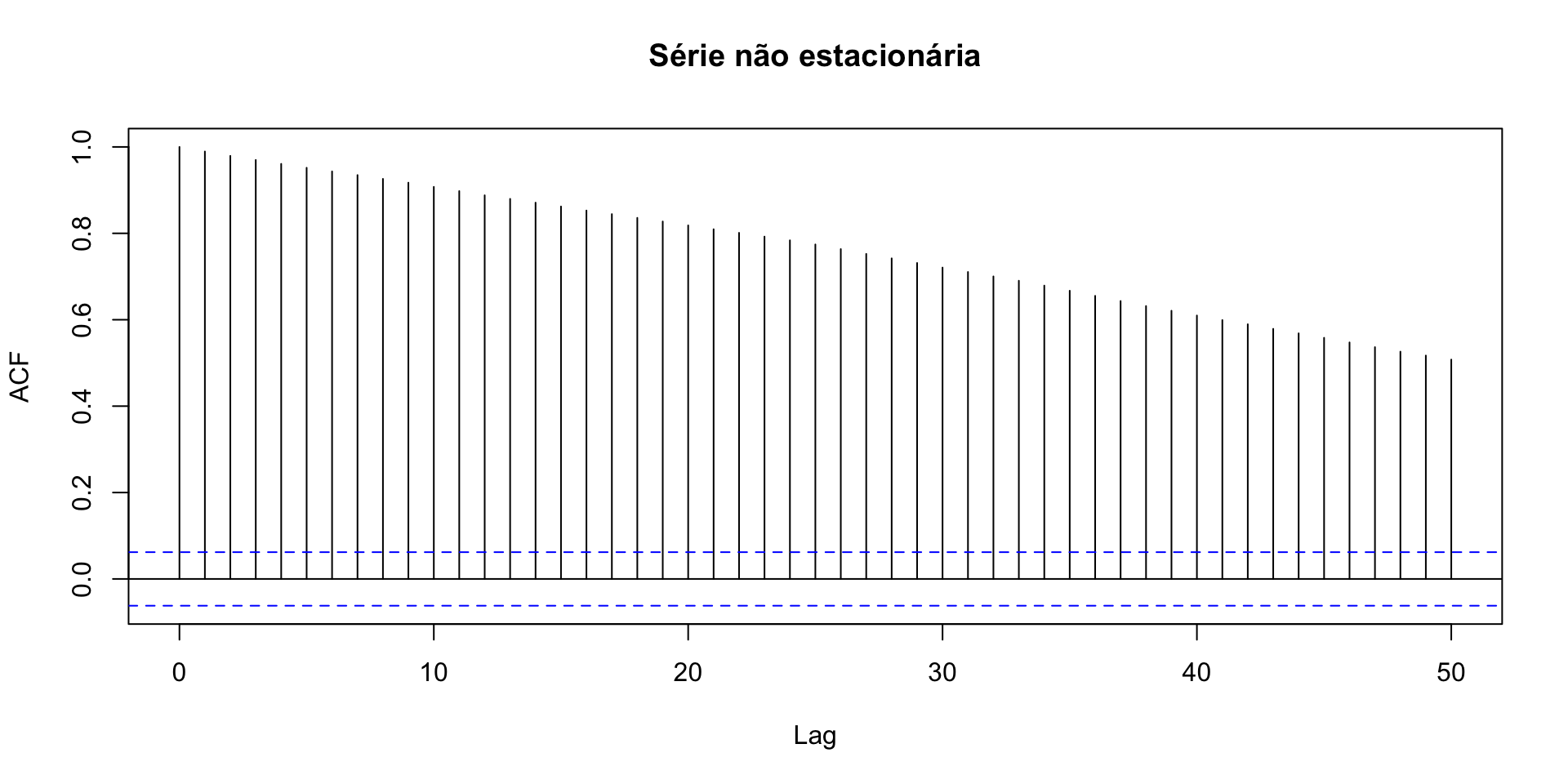
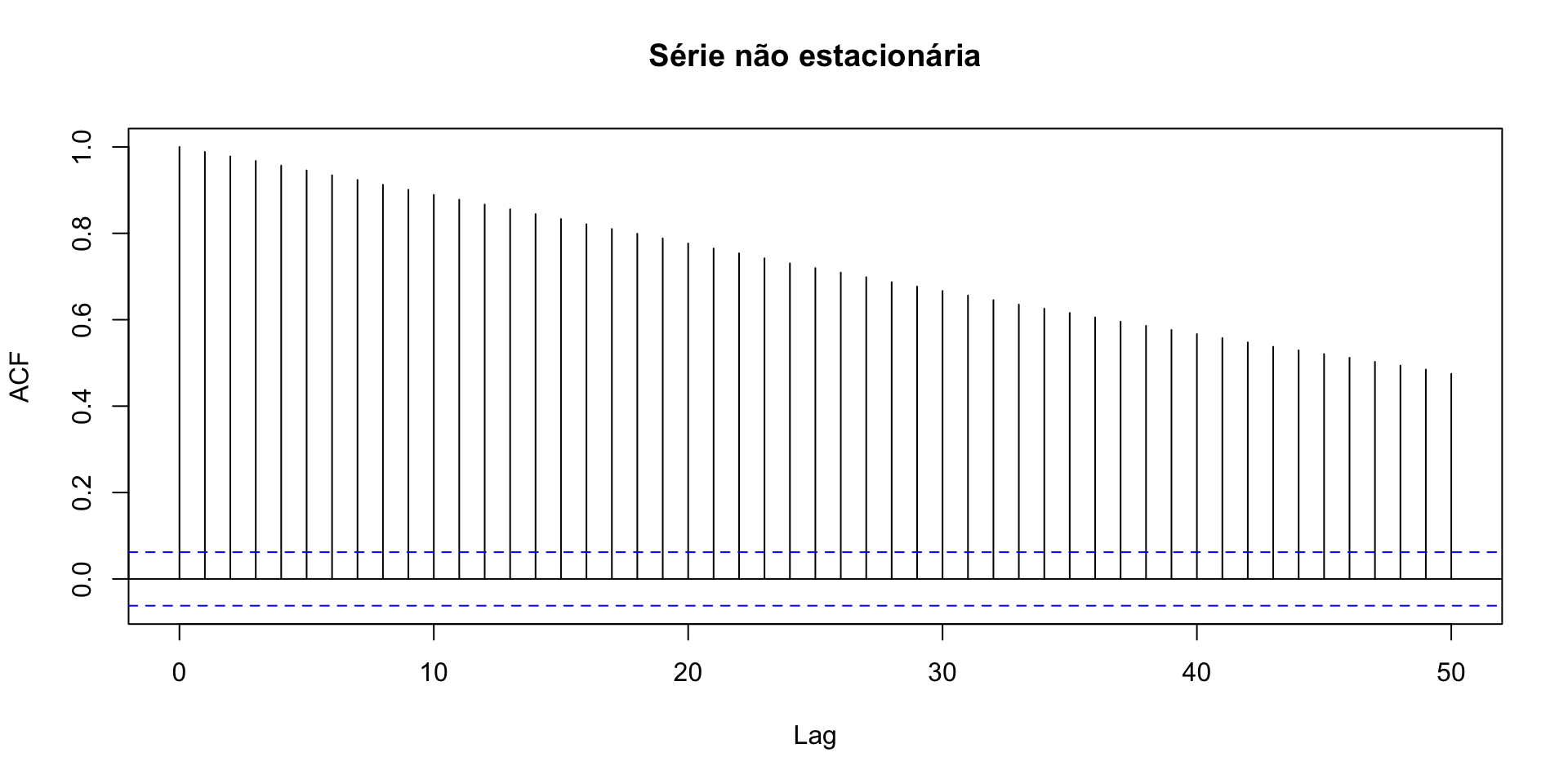
Se as autocorrelações forem significativas e cairem devagar, a série é não estacionária.
Regressões espúrias

Em alguns casos, existem alternativas simples para continuar utilizando modelos de regressão no contexto de séries temporais e não cair na regressão espúria.
Séries com tendência e modelos de regressão
- Ao remover o efeito da tendência,
Productionnão é mais estatísticamente significativa, o que faz muito mais sentido 🏄♀️ 🏄♀️. - Mesmo com a variável
Productionnão sendo estatísticamente significativa, o \(R^2\) do modelo deu \(\approx\) 0.98!. Será que o modelo capturou mesmo a dinâmica dos dados?