Modelos básicos + Avaliação de modelos
ME607 - Séries Temporais
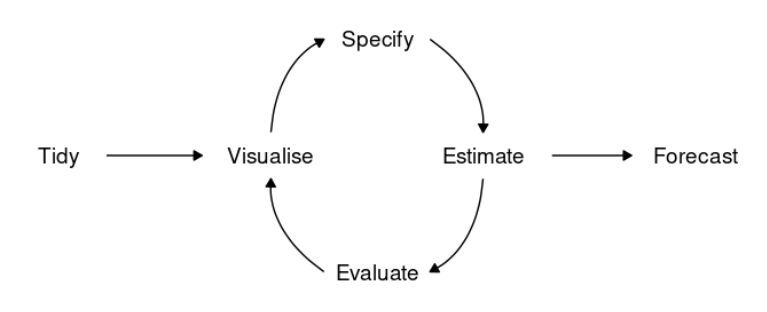
Fluxo de modelagem
Todo projeto relacionado com séries temporais deve passar pelo seguinte fluxo:
Fonte: Livro ‘Forecasting: Principles and Practice’
- Tidy: preparar os dados para podermos utilizar os diversos modelos implementados.
- Visualise: EDA.
- Especificar, estimar e avaliar o modelo (Modelagem).
- Fazer previsões (Forecast).
Modelos básicos
Os modelos básicos são bastante simples, para explicar eles, bem como para ilustrar como especificar e estimar o modelo no R, utilizaremos alguns métodos simples.
Code
Rows: 58
Columns: 2
$ Year <int> 1960, 1961, 1962, 1963, 1964, 1965, 1966, 1967, 1968, 1969, 197…
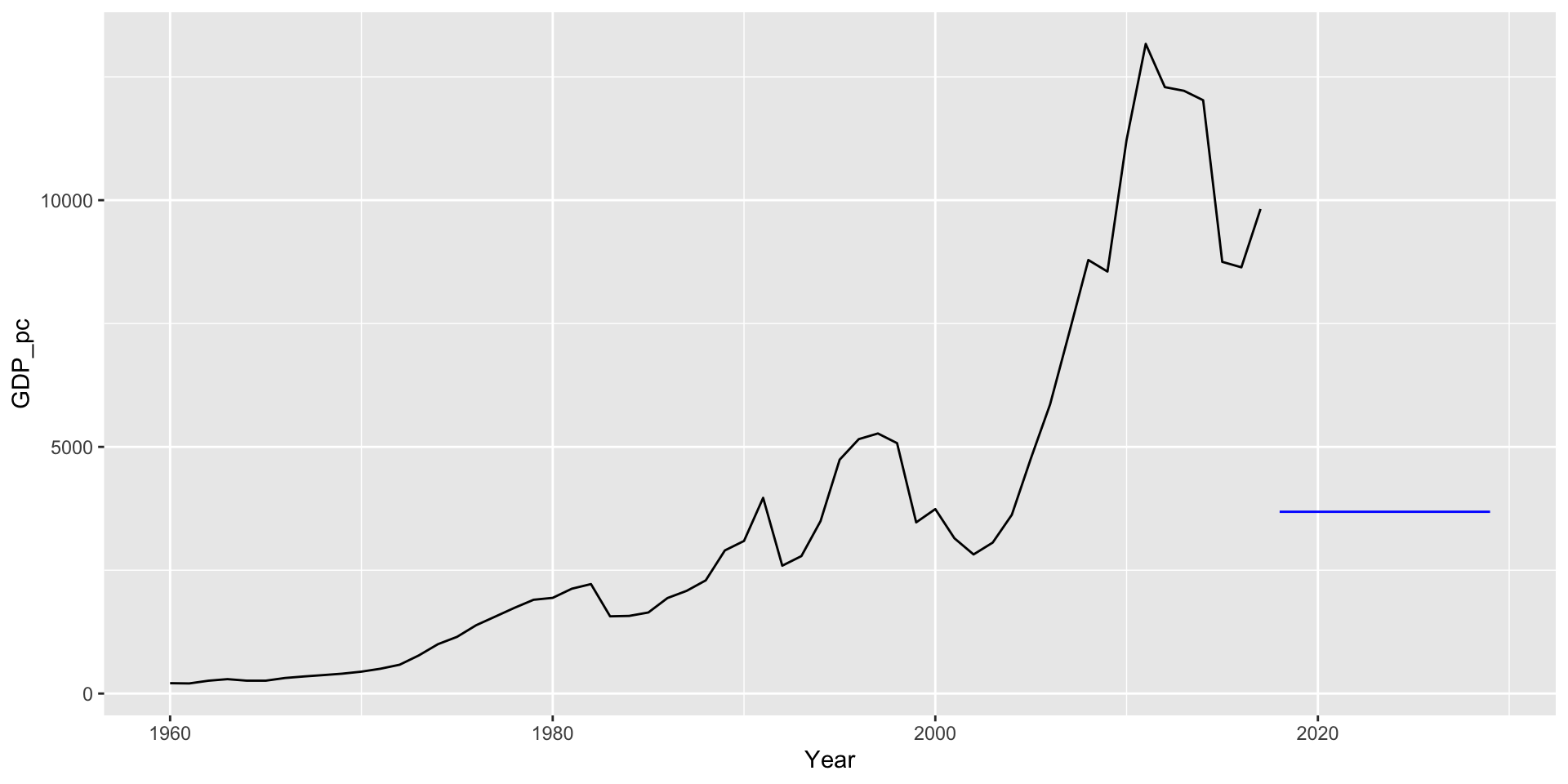
$ GDP_pc <dbl> 210.0275, 204.9293, 260.2253, 291.9506, 261.3311, 260.9647, 315…\[\hat{y}_{T+h|T} = \dfrac{\sum_{i=1}^T y_i}{T}\]
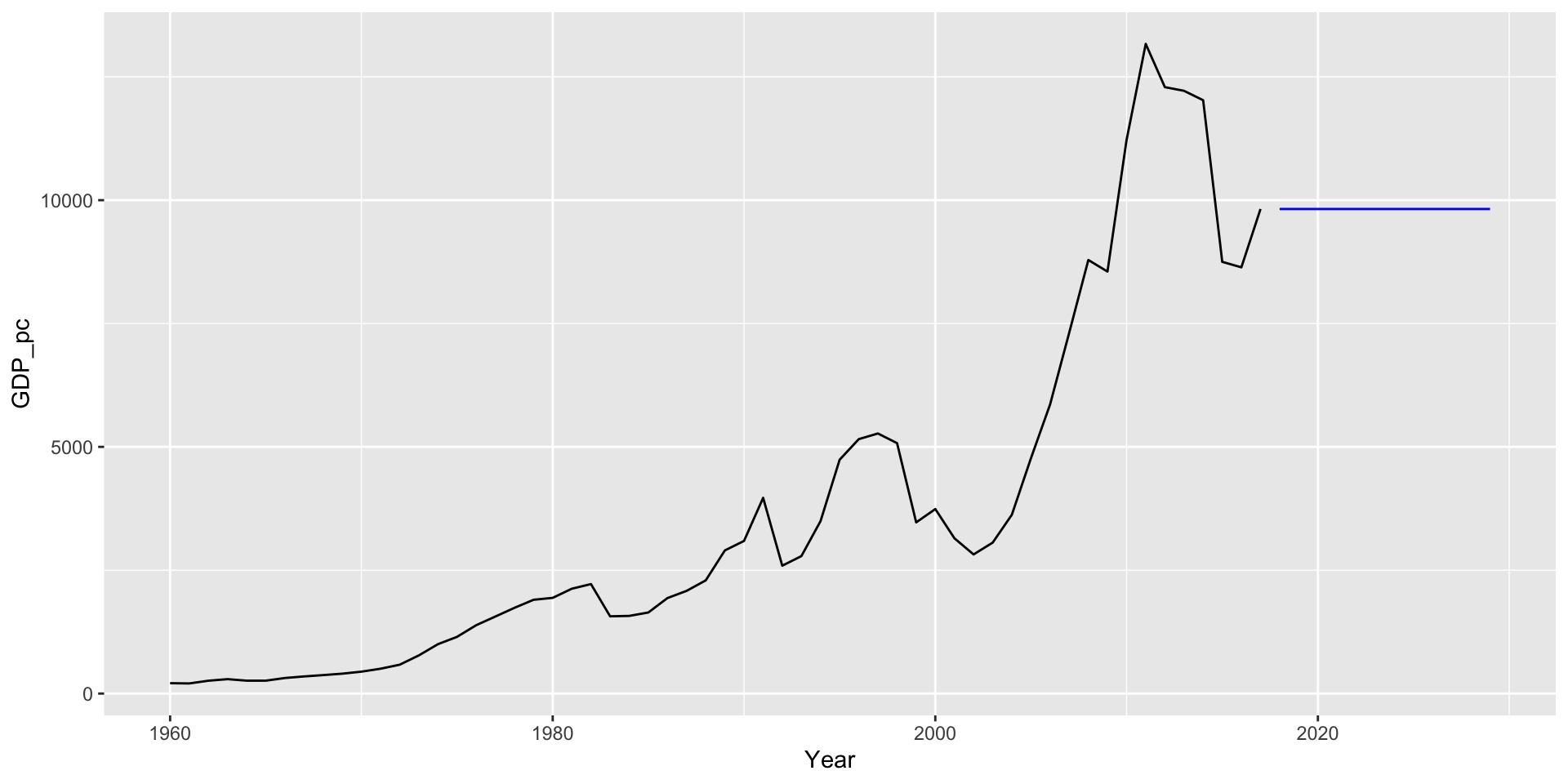
\[\text{Naive } \equiv \text{ Ingênuo}\]
Todas as previões são iguais à última observação, \(\hat{y}_{T+h|T} = y_T\).
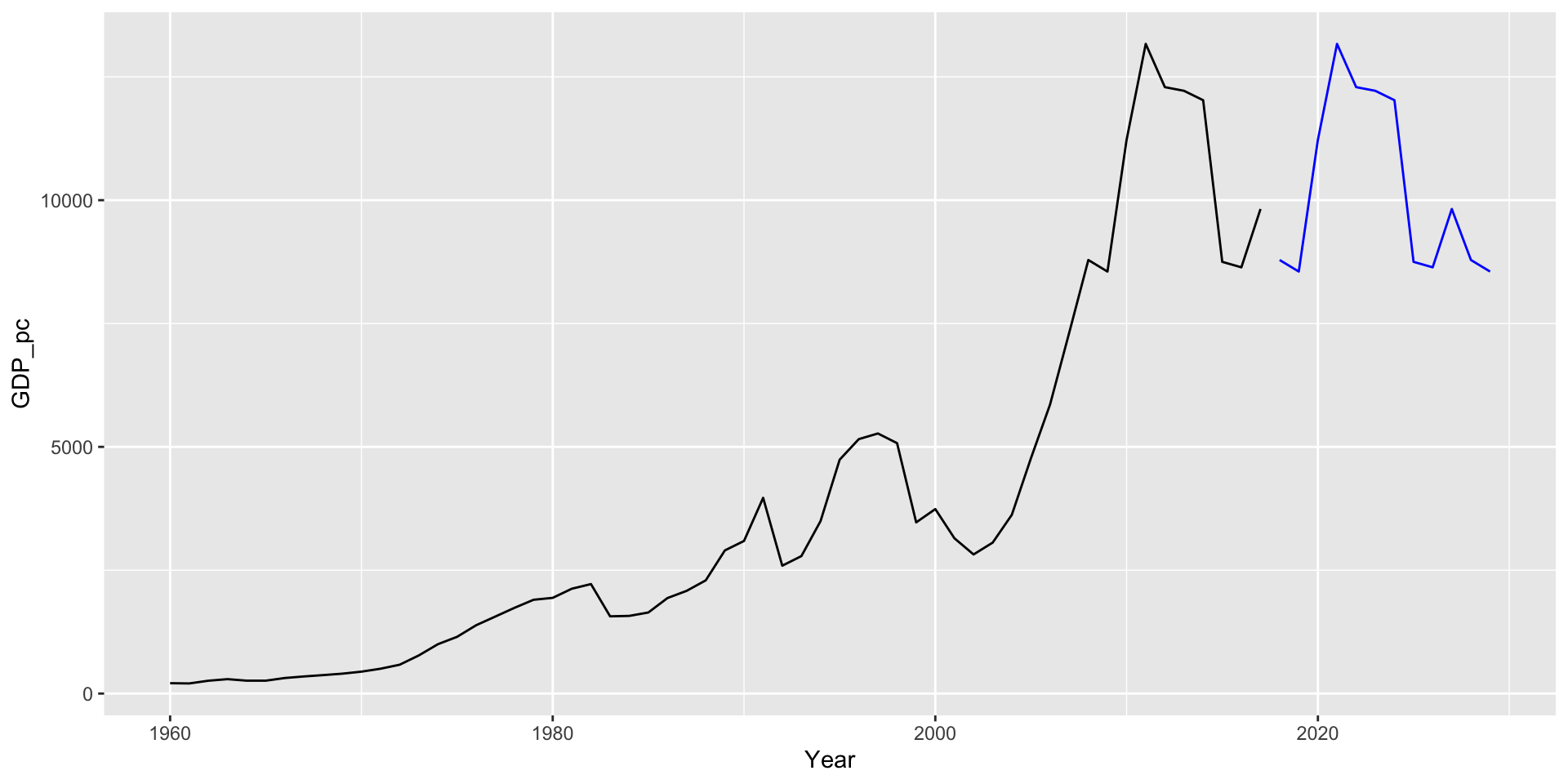
As previões são iguais à última observação do mesmo período sazonal.
Para ilustrar o método, vamos supor que nossos dados possuem um período sazonal \(m = 10\), ou seja que de 10 em 10 anos existe um padrão sazonal.
O drift (quantidade de mudança ao longo do tempo) é calculado como a mudança média nos dados históricos, \(\hat{y}_{T+h|T} = y_T + \dfrac{h}{T-1} \displaystyle \sum_{t=2}^T (y_t-y_{t-1}) = y_T + h \Big( \dfrac{y_T - y_1}{T-1} \Big)\).
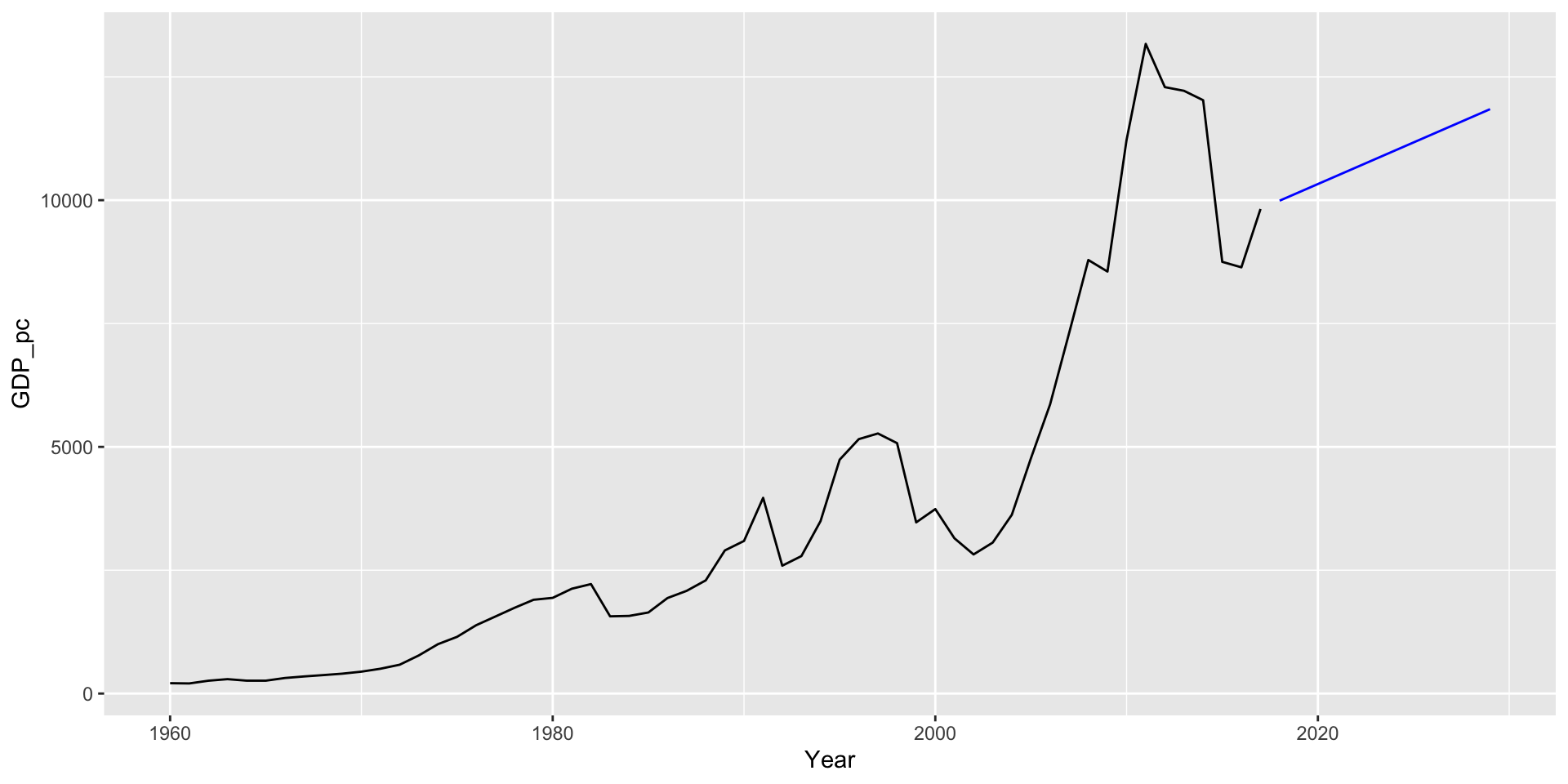
Modelos básicos
Repare na sintaxe da forma model(nome_qqr = nome_do_modelo(y ~ x))
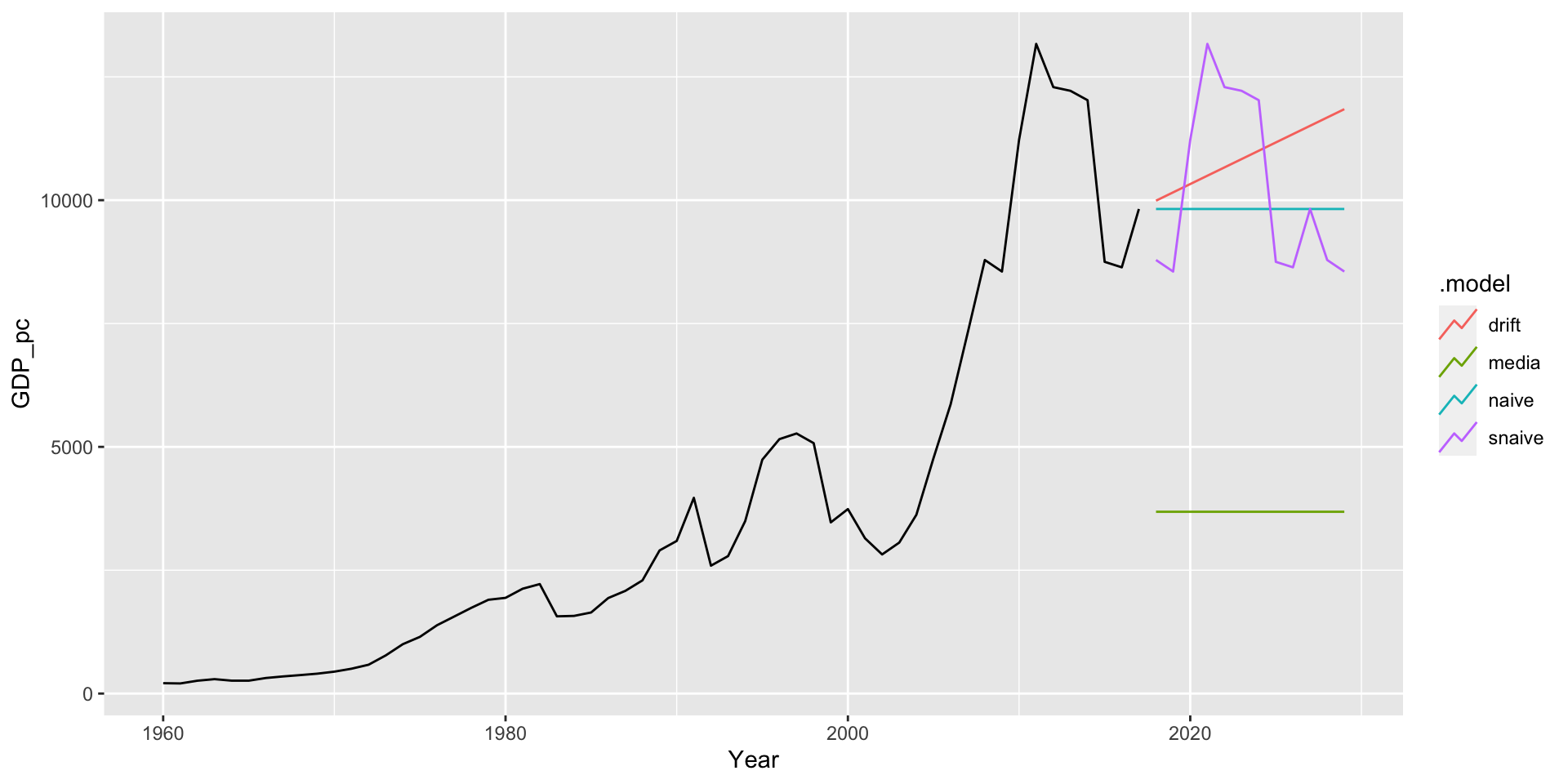
Modelos básicos
- Será que o modelo utilizado capturou as carecterísticas da série ao ponto que, os resíduos são apenas um ruido branco? (diagnóstico do modelo).
- Será que se utilizarmos o mesmo método por vários períodos de tempo teriamos um desempenho melhor do que modelos concorrentes?
- Por quê é importante avaliar o desempenho de um modelo?
Para responder isto, faremos um diagnóstico do modelo e avaliaremos o desempenho fora da amostra
Diagnóstico do modelo
Code
# Importando os dados
uri <- "https://raw.githubusercontent.com/ctruciosm/ctruciosm.github.io/master/datasets/lajeado_rs.csv"
lajeado_rs <- read.csv(uri, sep = ";")
# Passando para um formato de séries temporais
lajeado_rs <- lajeado_rs %>%
mutate(ano_mes = yearmonth(ano_mes)) %>%
select(ano_mes, temp_media) %>%
as_tsibble(index = ano_mes)
glimpse(lajeado_rs)Rows: 79
Columns: 2
$ ano_mes <mth> 2015 Jan, 2015 Feb, 2015 Mar, 2015 Apr, 2015 May, 2015 Jun,…
$ temp_media <dbl> 25.6, 24.8, 24.2, 21.2, 18.5, 16.2, 15.9, 21.0, 17.8, 19.4,…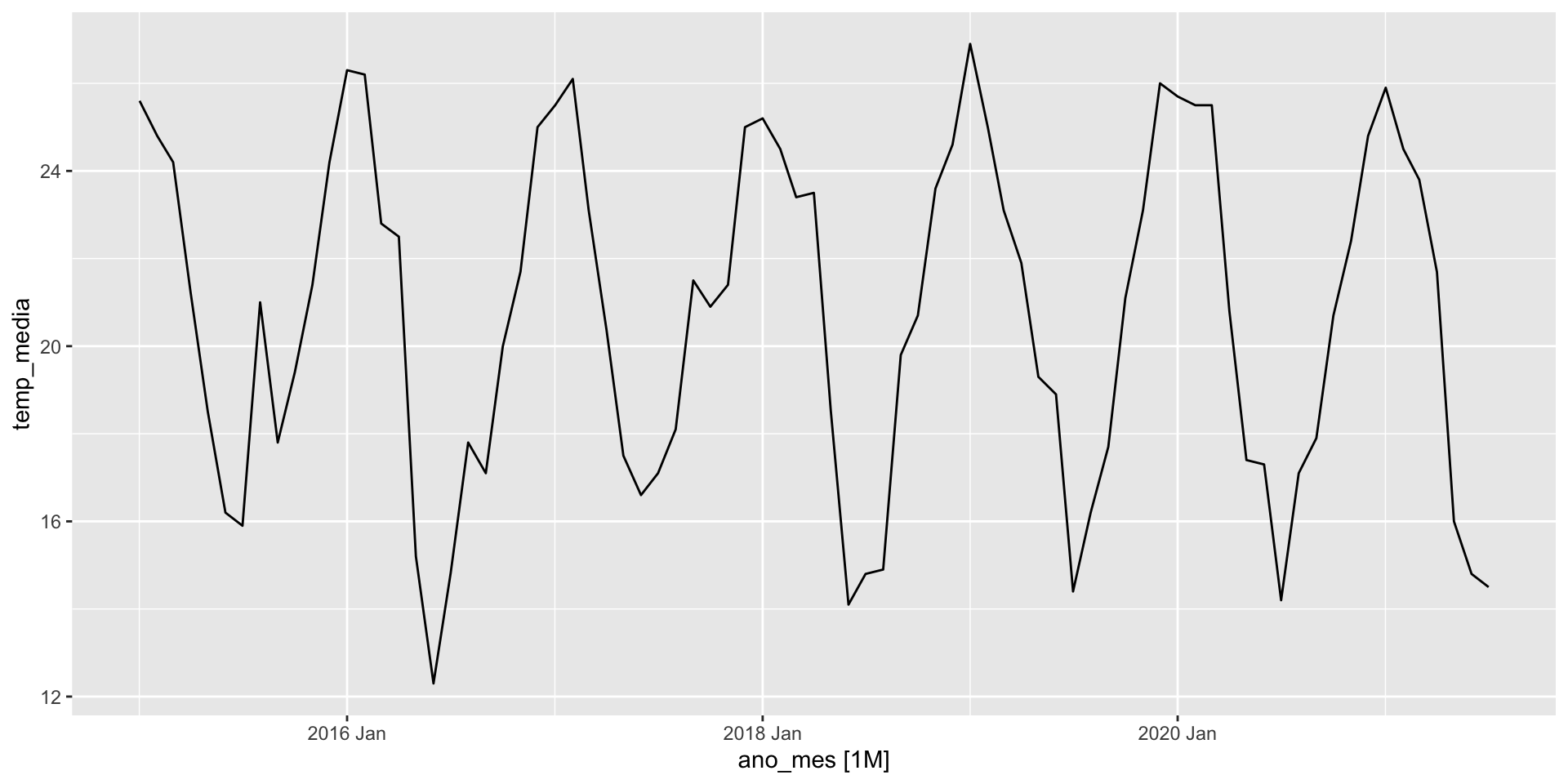
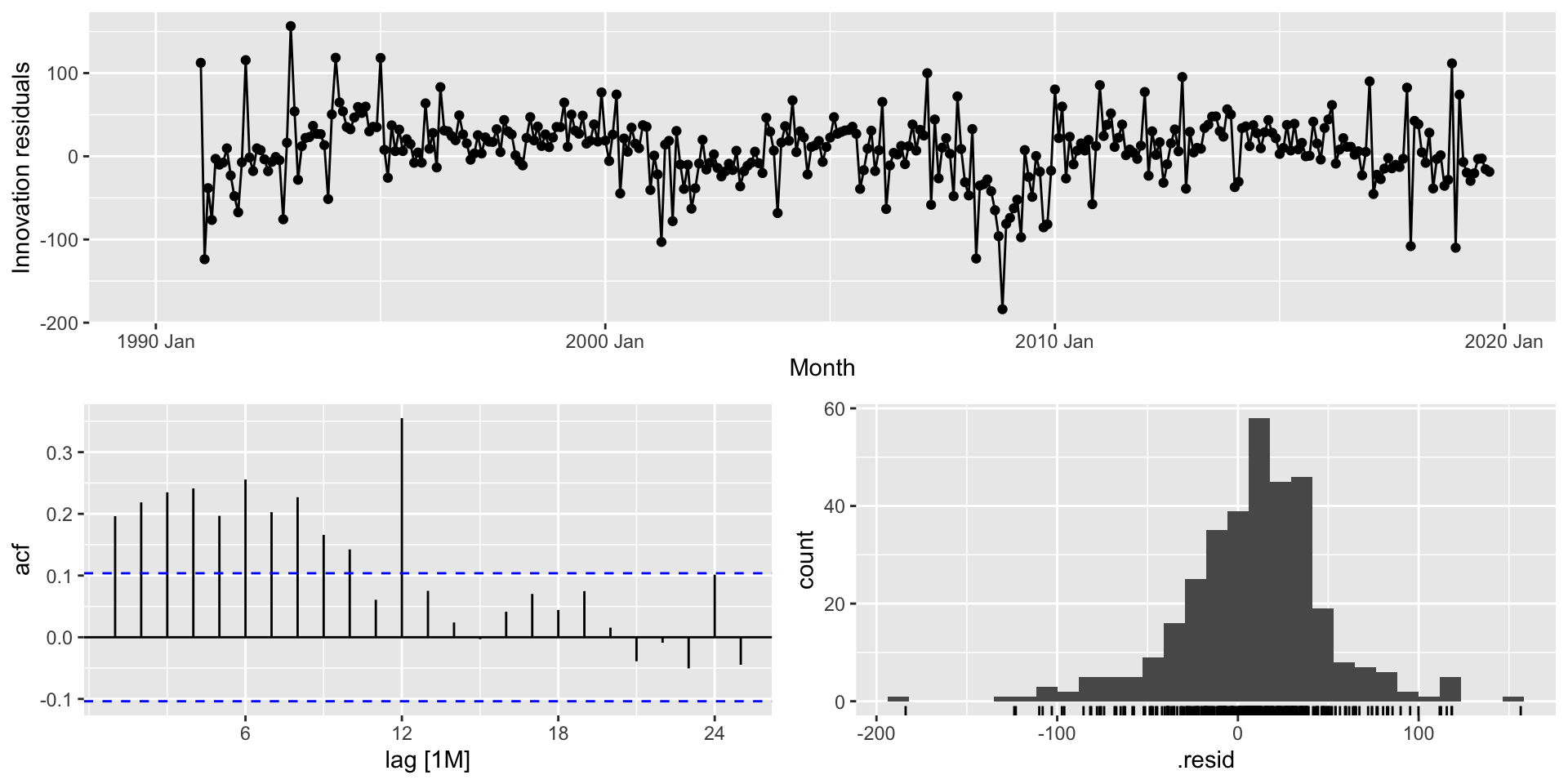
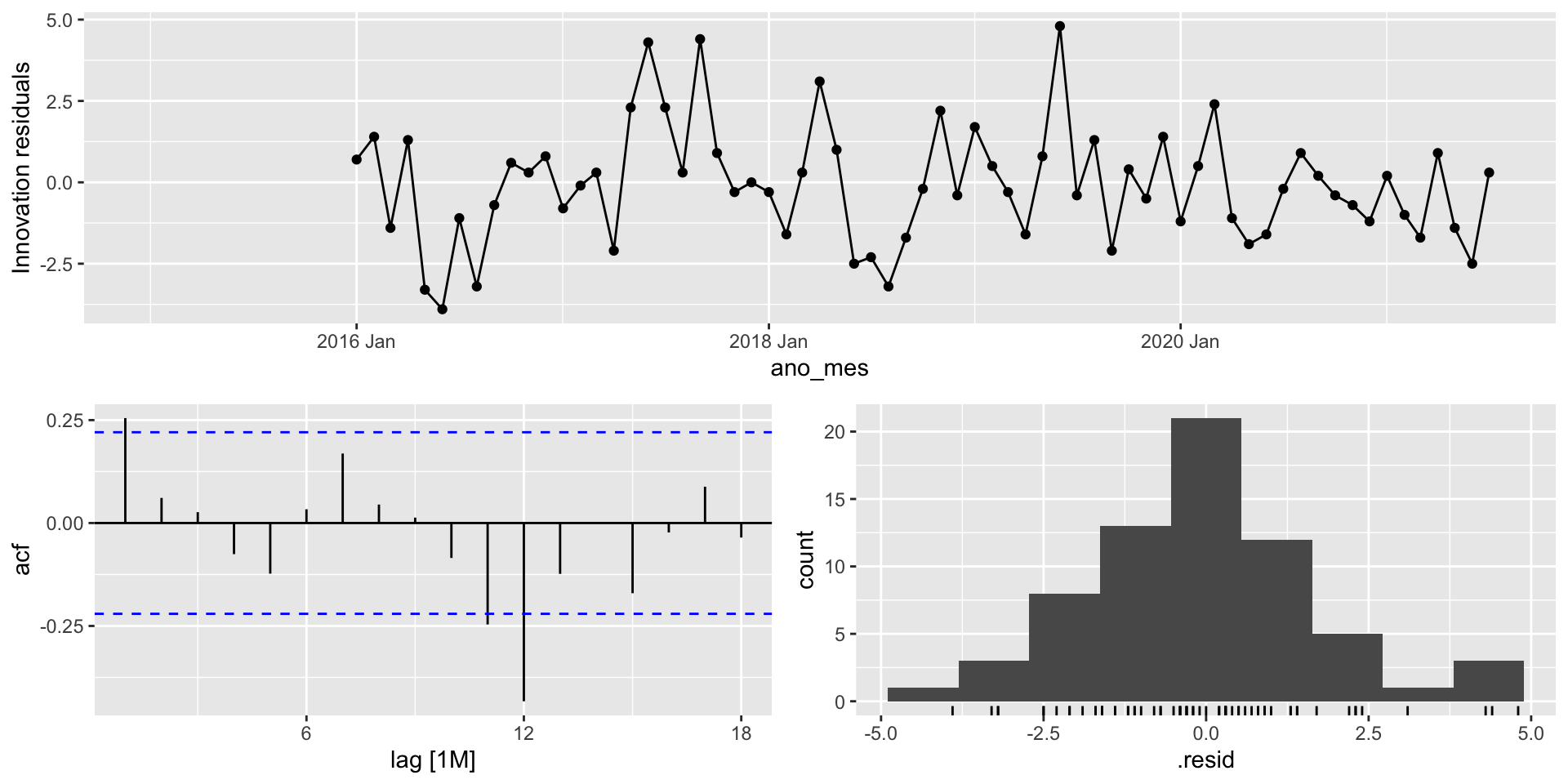
A função gg_tsresiduals() do pacote feasts (que já é carregado quando utilizamos o pacote fpp3) nos ajudará a fazer o diagnóstico do modelo. A função fornece o gráfico de sequência, o gráfico da função de autocorrelação e o histograma dos resíduos de inovação.
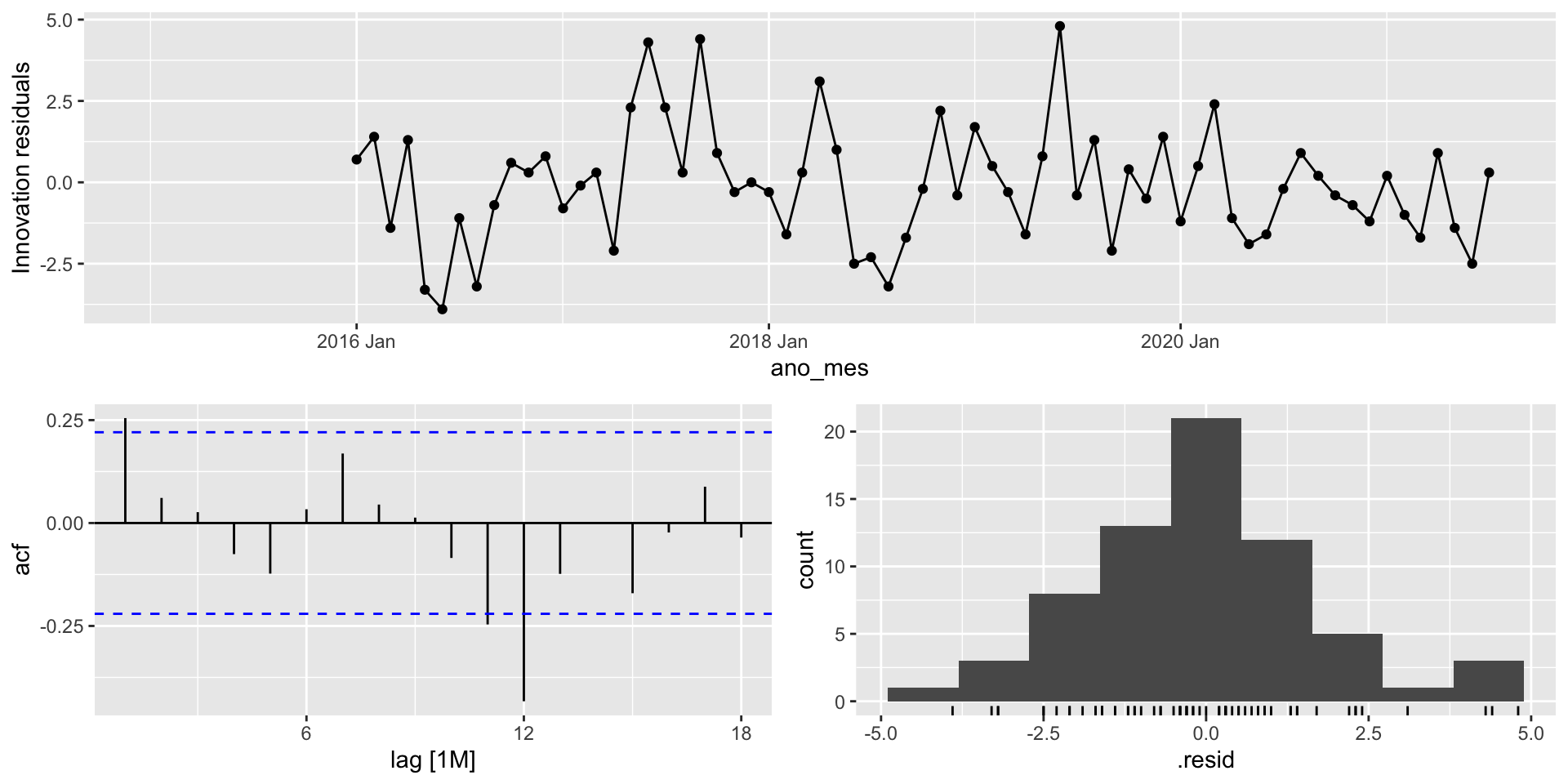
Diagnóstico do modelo: Exemplo
- Na aula anterior aprendimos como fazer previsão quando utilizamos modelo de decomposição.
- Fazemos previsão de \(S_t\) e \(\underbrace{T_t + R_t}_{A_t}\) de forma independente e depois unimos as previsões segundo o tipo de decomposição utilizada.
- Utilizaremos um SNAIVE para \(S_t\)
- Para \(A_t\), utilizaremos LOES.
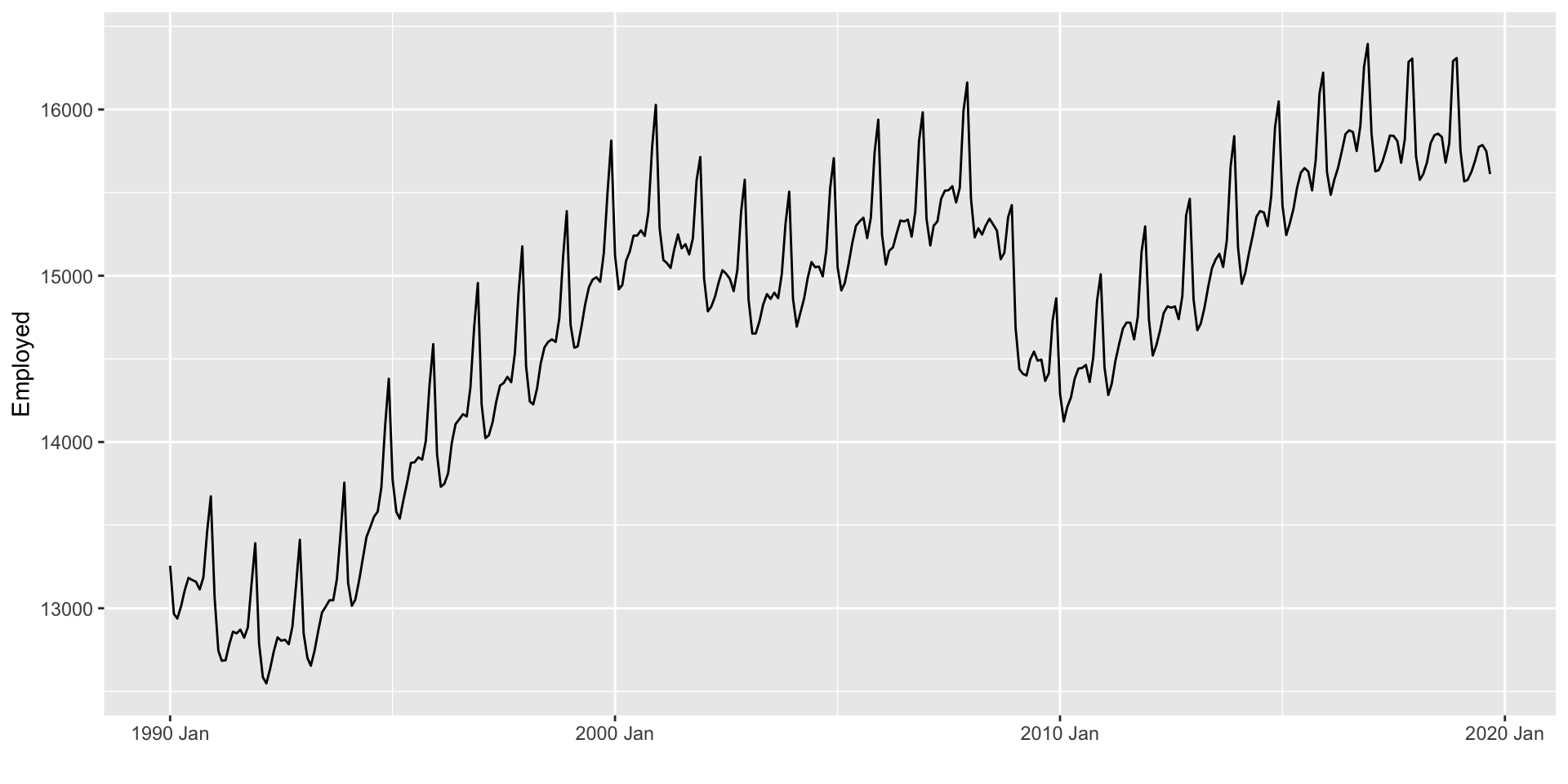
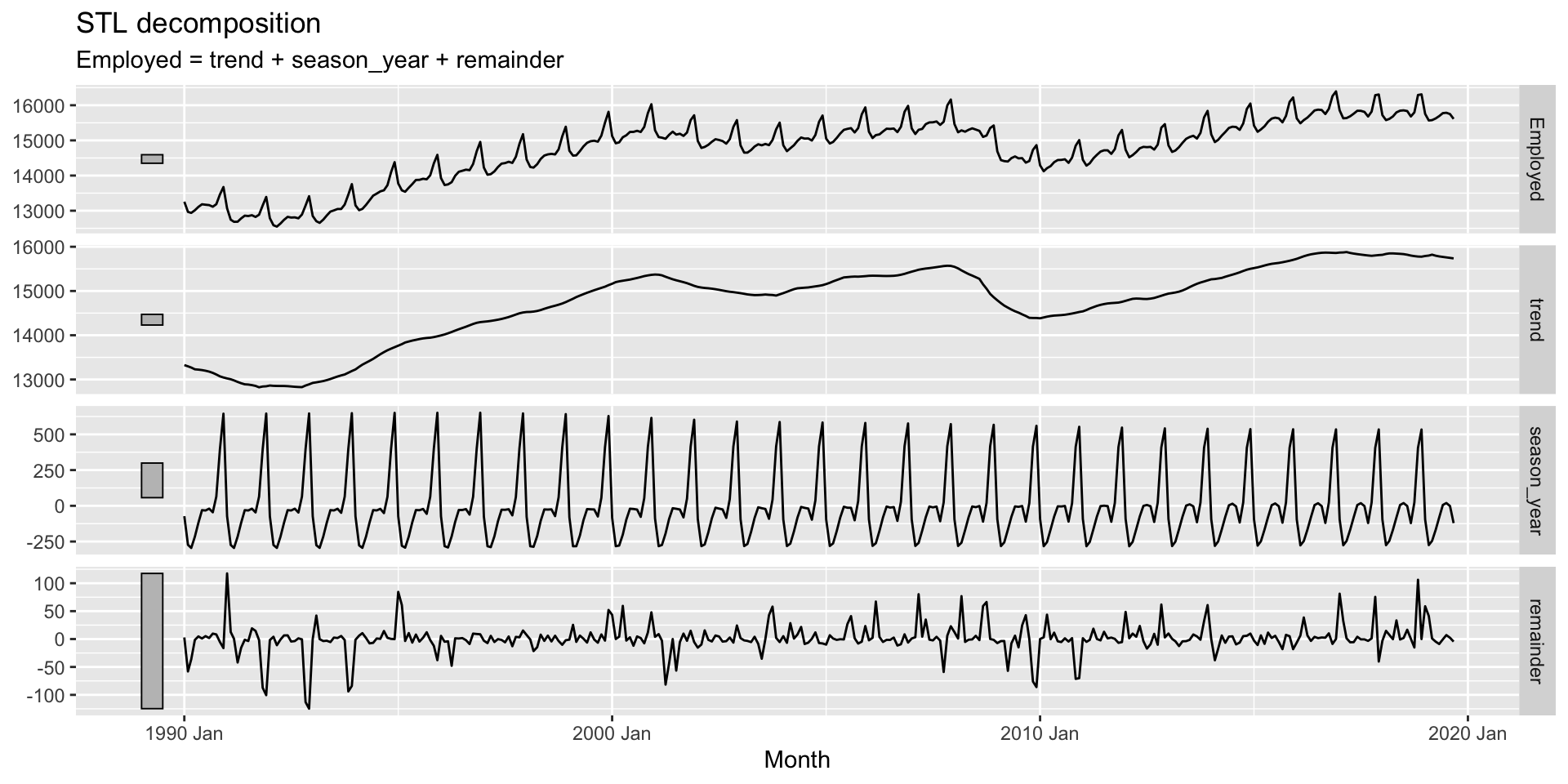
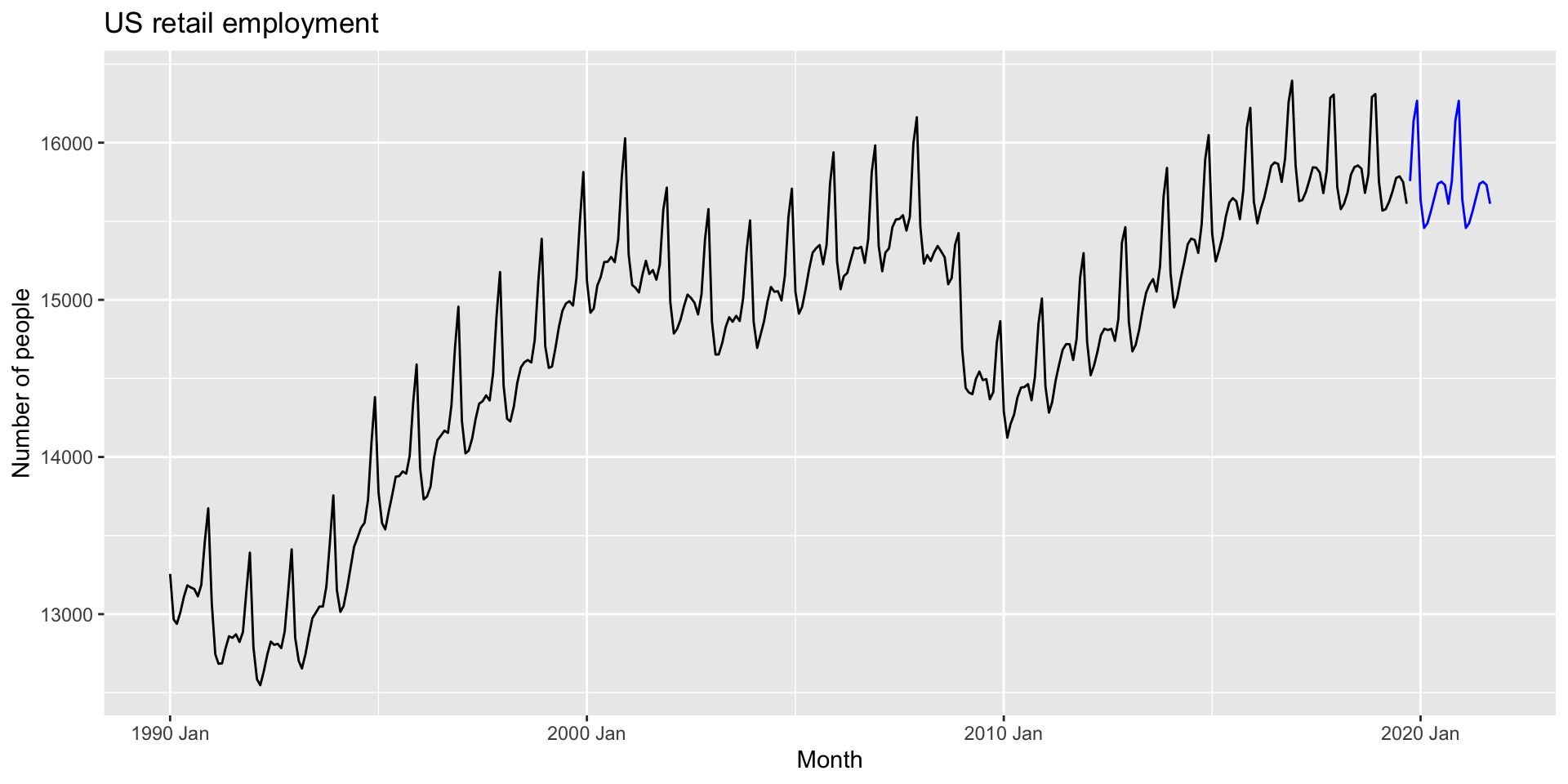
Avaliação do desempenho fora da amostra

Avaliação do desempenho fora da amostra
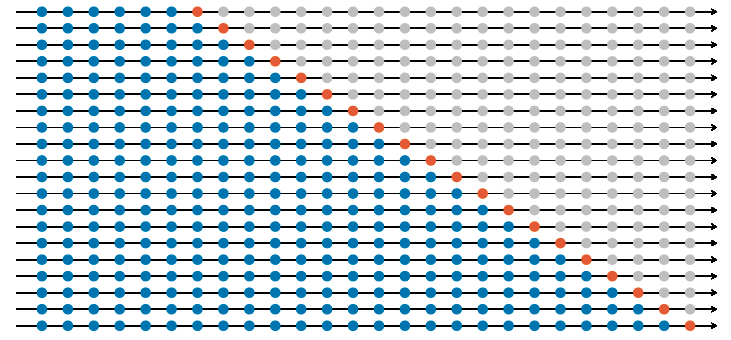
Fonte: Livro ‘Forecasting: Principles and Practice’
Conhecido também como expanding/stretching window.
Avaliação do desempenho fora da amostra
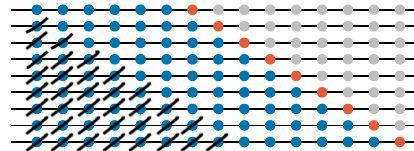
Fonte: Livro ‘Forecasting: Principles and Practice’
Conhecido também como rolling window.
Avaliação do desempenho fora da amostra
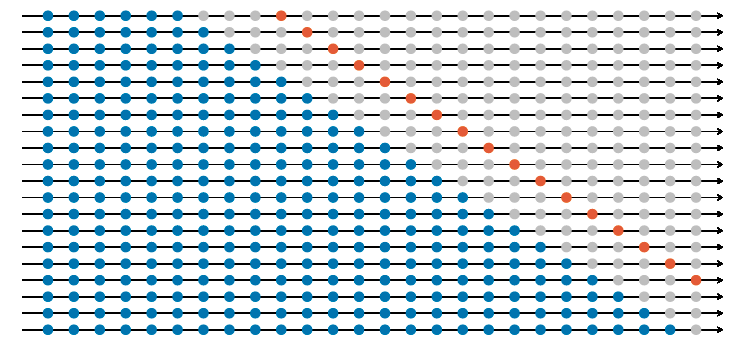
Fonte: Livro ‘Forecasting: Principles and Practice’
Avaliação do desempenho fora da amostra
E se quisermos uma medida de quão bem está performando o modelo?

Avaliação do desempenho fora da amostra
Será que o modelo SNAIVE, que obteme as melhores métricas de desempenho fora-da-amostra, capturou bem a dinâmica dos dados?.
Referências
- Hyndman, R.J., & Athanasopoulos, G. (2021). Forecasting: principles and practice, 3rd edition, OTexts: Melbourne, Australia. OTexts.com/fpp3.. Chapter 5.
- Brockwell, P.J & Davis, R.A. (2016). Introduction to Time Series and Forecasting, 3rd editions, Springer. Section 1.5
