Code
ME607 - Séries Temporais
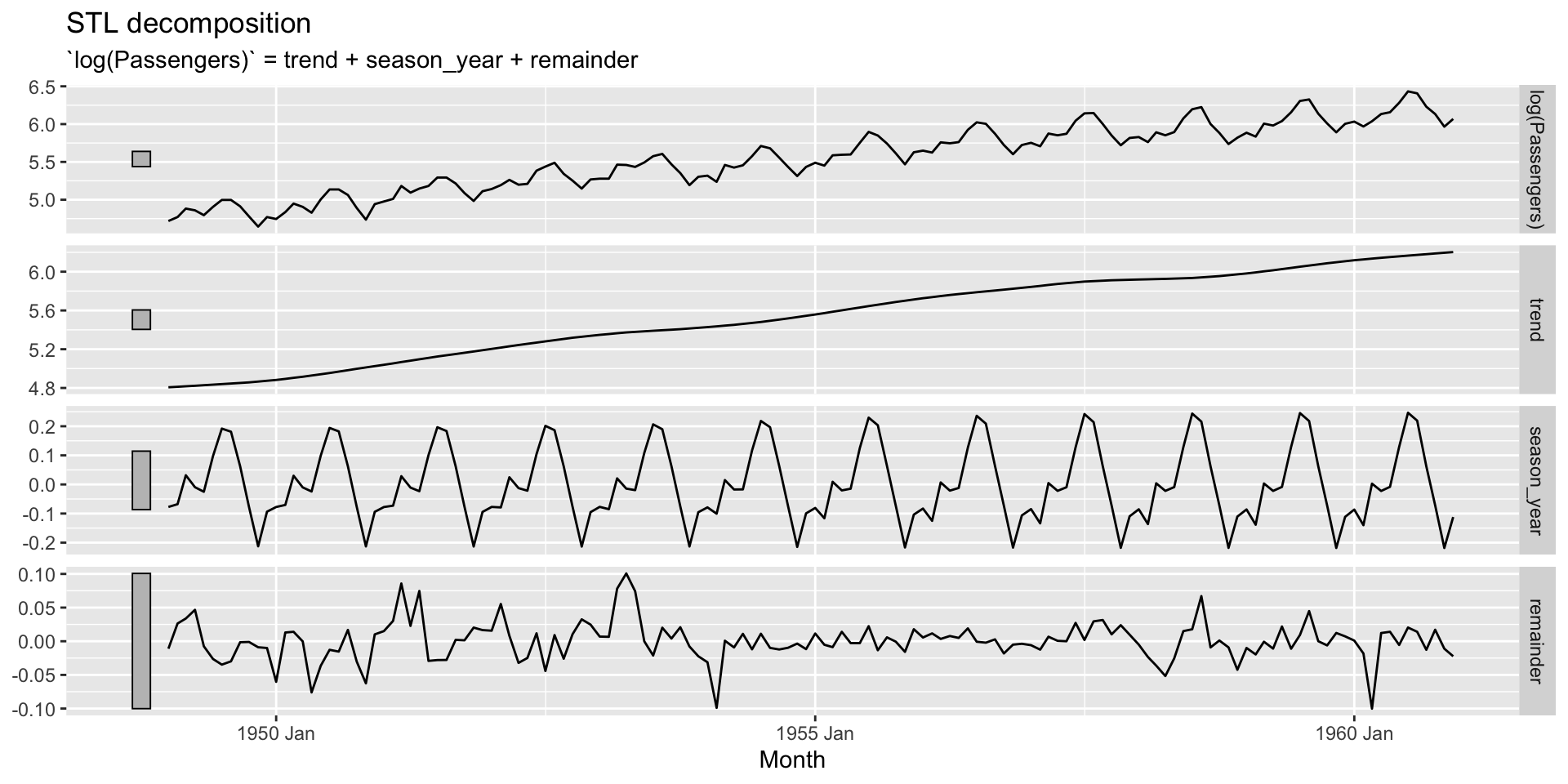
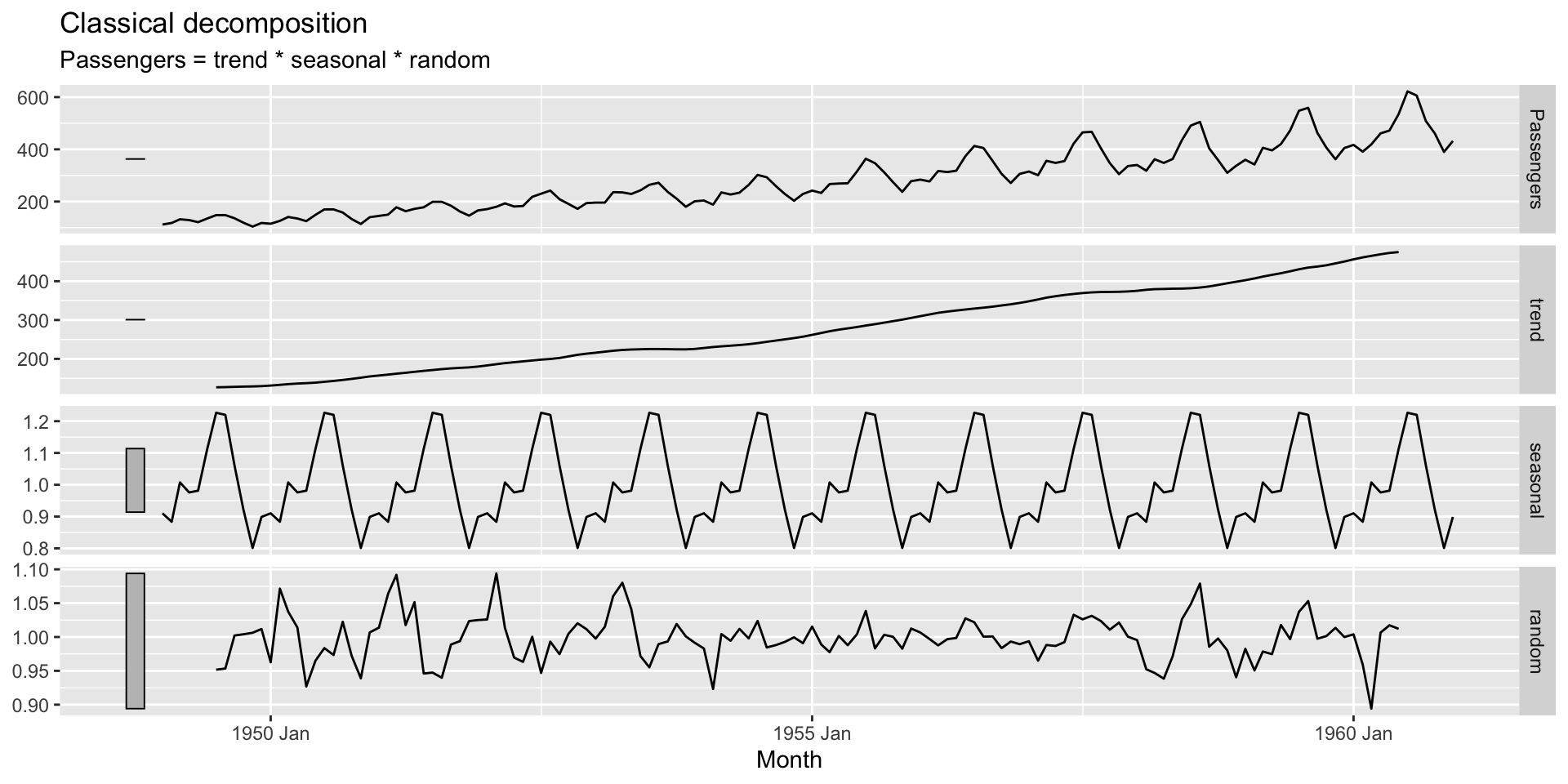
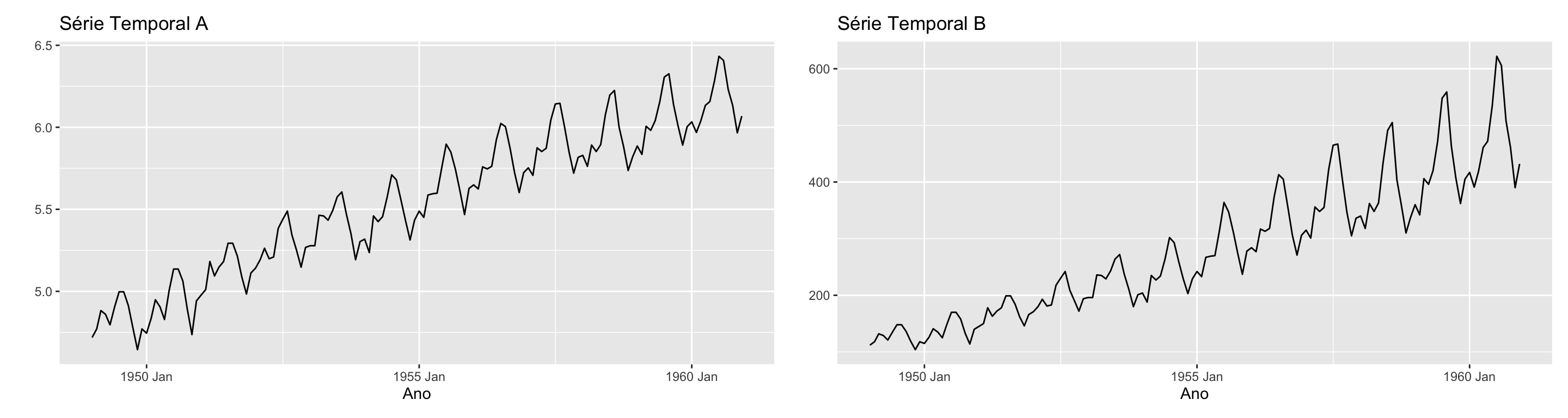
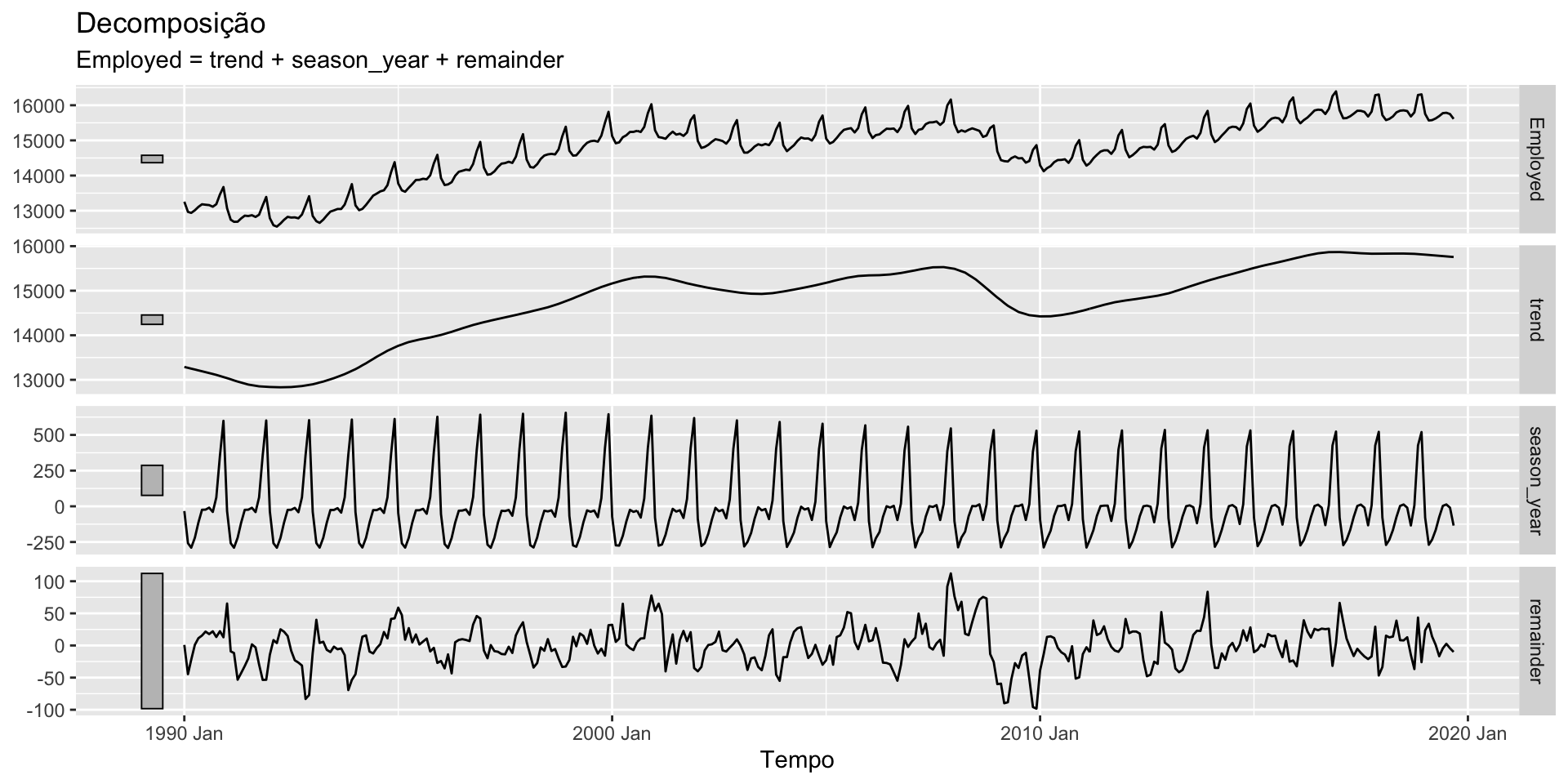
Se a magnitude das oscilações não varia com o nível, então utilizamos uma decomposição aditiva. Caso contrário, uma decomposição multiplicativa.
Obs: \[y_t = T_t \times S_t \times R_t \quad \rightarrow \quad \log(y_t) = \log(T_t) + \log(S_t) + \log(R_t)\]
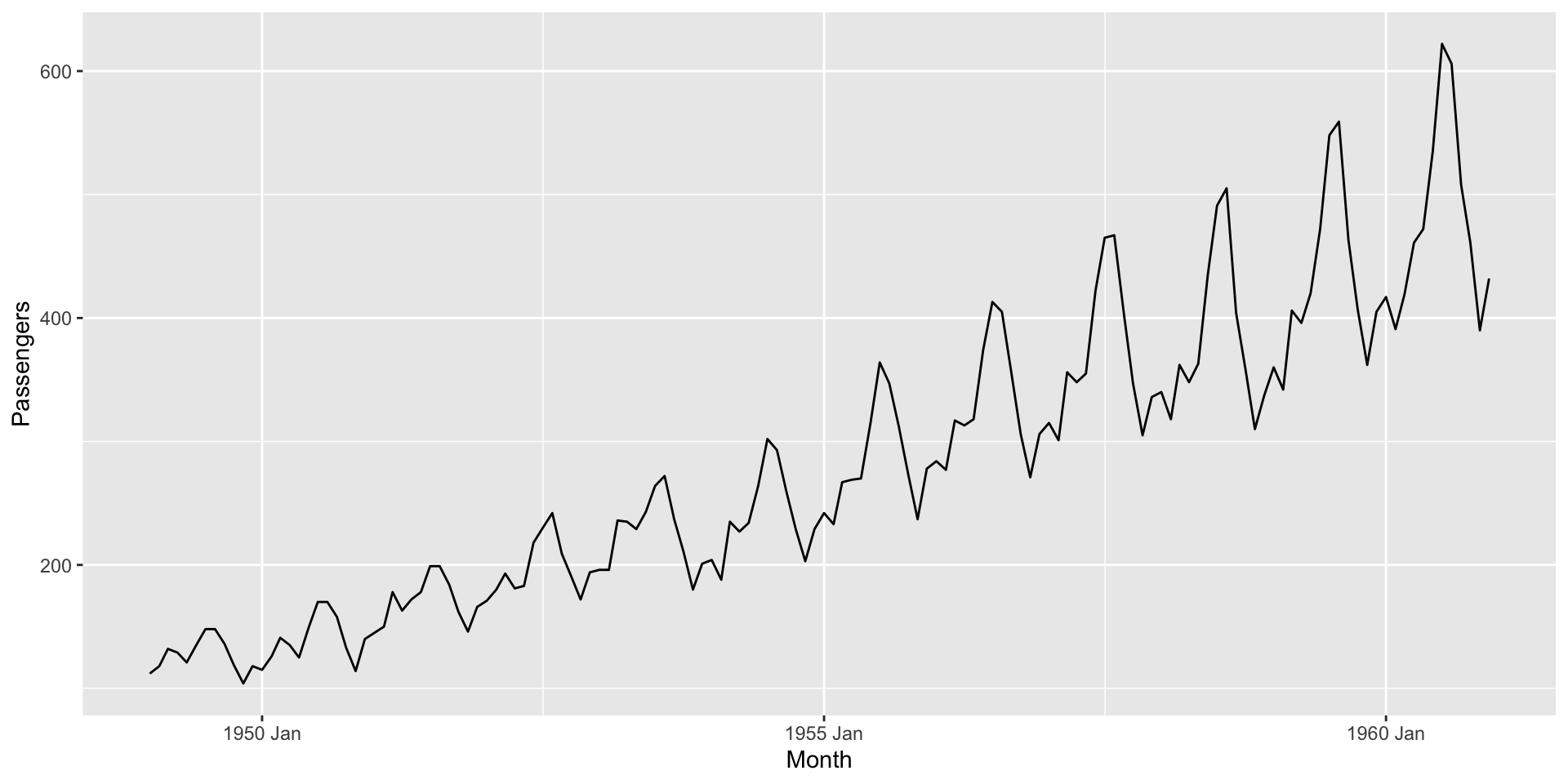
Suponha que temos a seguinte série temporal
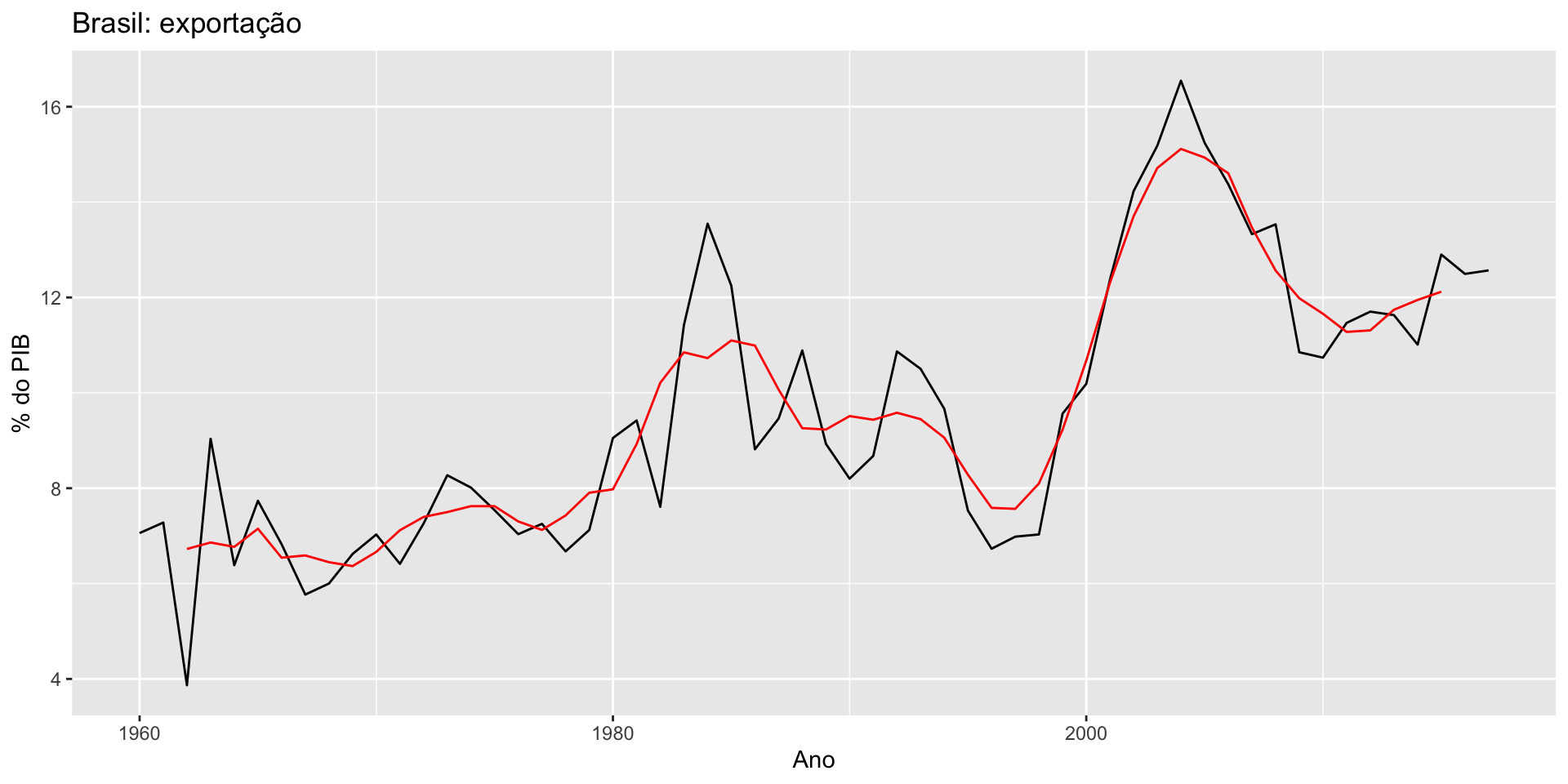
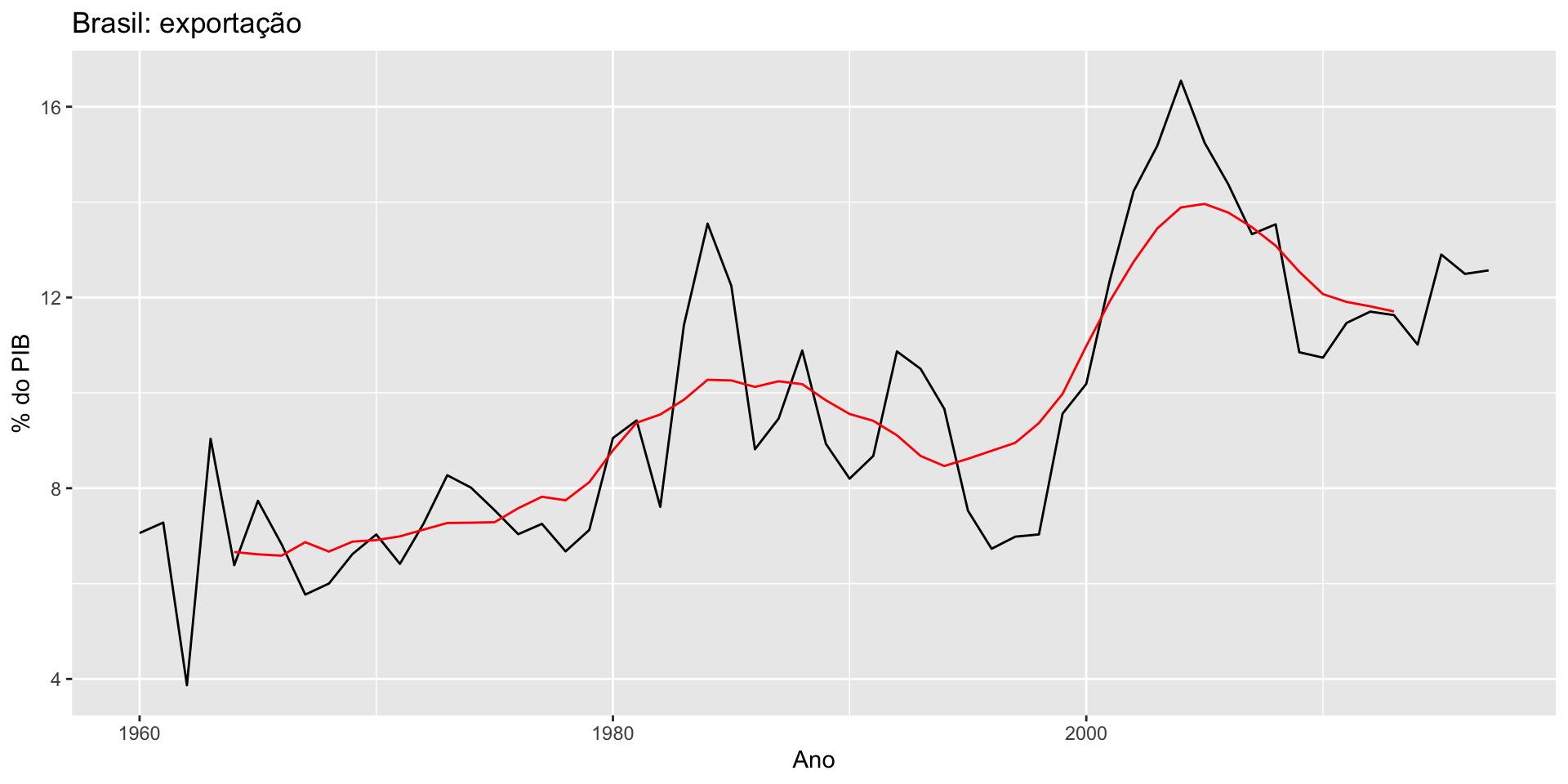
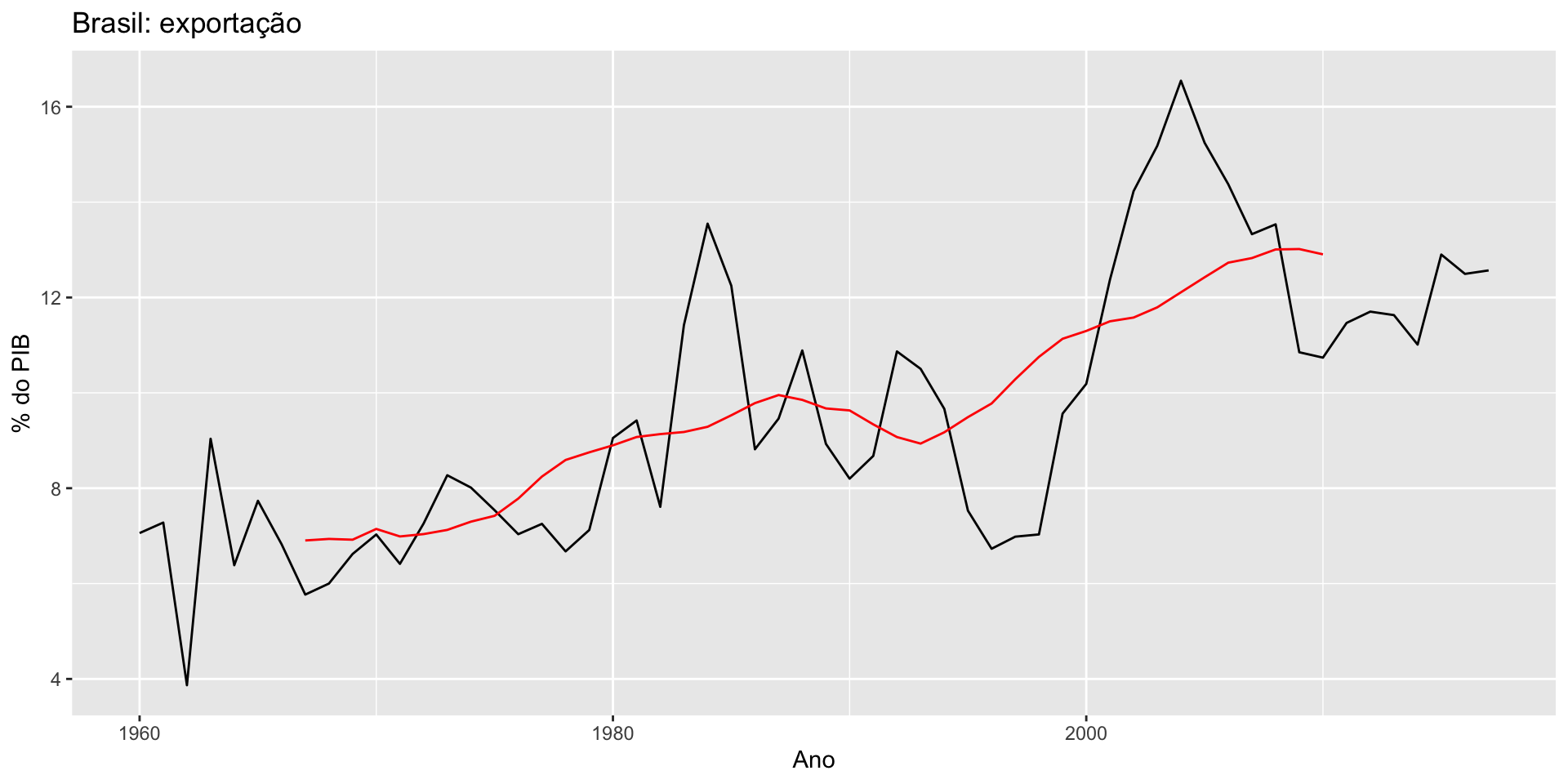
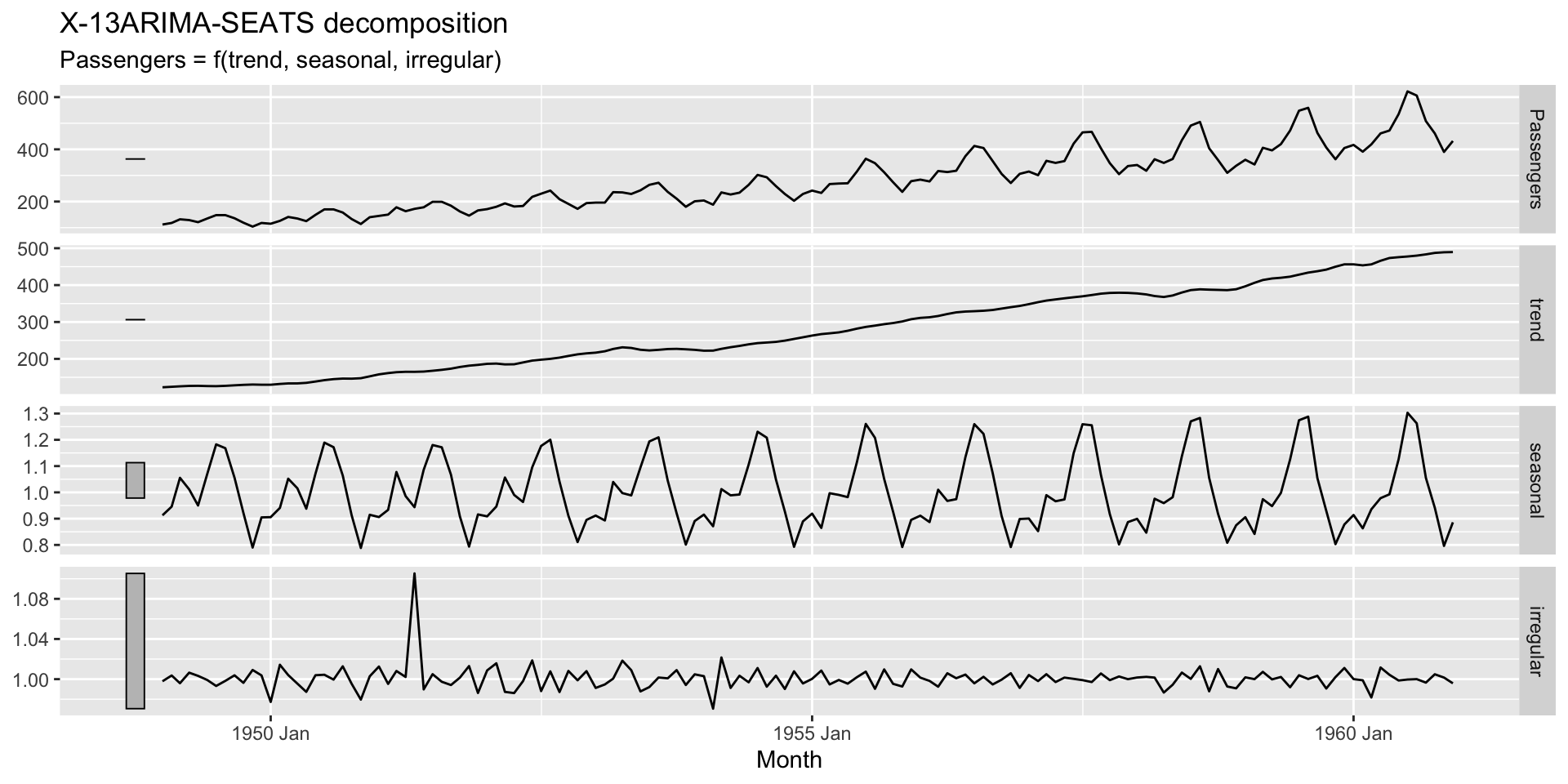
O objetivo é decompor a série na suas componentes.
Se a componente sazonal é removida da série, dizemos que a serié é sazonalmente ajustada. Esta série (sazonalmente ajustada) é dada, dependendo se utilizarmos uma decomposição aditiva ou multiplicativa, por: \[y_t - S_t \quad ou \quad y_t/S_t\]
Rows: 144
Columns: 2
$ Month <chr> "1949-01", "1949-02", "1949-03", "1949-04", "1949-05", "194…
$ Passengers <int> 112, 118, 132, 129, 121, 135, 148, 148, 136, 119, 104, 118,…Rows: 144
Columns: 2
$ Month <mth> 1949 Jan, 1949 Feb, 1949 Mar, 1949 Apr, 1949 May, 1949 Jun,…
$ Passengers <int> 112, 118, 132, 129, 121, 135, 148, 148, 136, 119, 104, 118,…# A dable: 144 x 7 [1M]
# Key: .model [1]
# : Passengers = trend * seasonal * random
.model Month Passengers trend seasonal random season_adjust
<chr> <mth> <int> <dbl> <dbl> <dbl> <dbl>
1 decomposition 1949 Jan 112 NA 0.910 NA 123.
2 decomposition 1949 Feb 118 NA 0.884 NA 134.
3 decomposition 1949 Mar 132 NA 1.01 NA 131.
4 decomposition 1949 Apr 129 NA 0.976 NA 132.
5 decomposition 1949 May 121 NA 0.981 NA 123.
6 decomposition 1949 Jun 135 NA 1.11 NA 121.
7 decomposition 1949 Jul 148 127. 1.23 0.952 121.
8 decomposition 1949 Aug 148 127. 1.22 0.953 121.
9 decomposition 1949 Sep 136 128. 1.06 1.00 128.
10 decomposition 1949 Oct 119 129. 0.922 1.00 129.
# ℹ 134 more rowsyearmonth() do pacote tsibble, outras funções úteis são yearquarter(), yearweek(), as_date(), ymd(), ymd_hms().type dentro de classical_decomposition() pode ser “multiplicative” ou “aditive”, dependendo do tipo de decomposição a ser utilizada.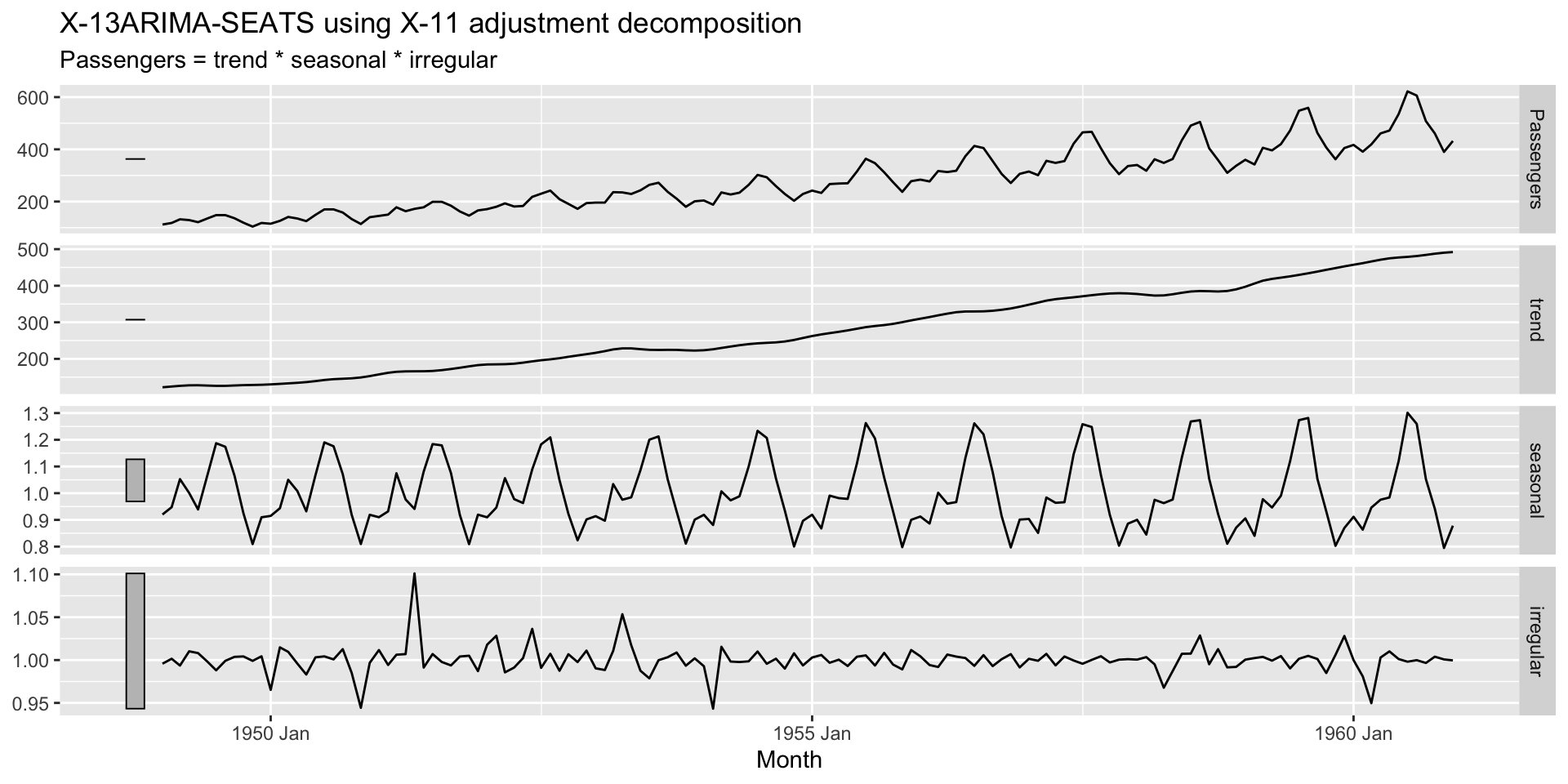
SEATS (Seasonal Extraction in ARIMA Time Series).
STL (Seasonal and Trend decomposition using Loess) 1