class: center, middle, inverse, title-slide # Modelos de Regressão e Previsão (ACA228) ## Regressão e séries temporais II. ### Prof. Carlos Trucíos <br><a href="http://ctruciosm.github.io"> <i class="fa fa-desktop fa-fw"></i> ctruciosm.github.io</a><br> <a href="mailto:carlos.trucios@facc.ufrj.br"><i class="fa fa-paper-plane fa-fw"></i> carlos.trucios@facc.ufrj.br</a><br> ### Faculdade de Administração e Ciências Contábeis, </br> Universidade Federal de Rio de Janeiro --- layout: true <a class="footer-link" href="http://ctruciosm.github.io">ctruciosm.github.io — Carlos Trucíos (FACC/UFRJ)</a> --- <div> <style type="text/css">.xaringan-extra-logo { width: 200px; height: 350px; z-index: 0; background-image: url(imagens/UFRJ.png); background-size: contain; background-repeat: no-repeat; position: absolute; top:1em;right:1em; } </style> <script>(function () { let tries = 0 function addLogo () { if (typeof slideshow === 'undefined') { tries += 1 if (tries < 10) { setTimeout(addLogo, 100) } } else { document.querySelectorAll('.remark-slide-content:not(.title-slide):not(.inverse):not(.hide_logo)') .forEach(function (slide) { const logo = document.createElement('div') logo.classList = 'xaringan-extra-logo' logo.href = null slide.appendChild(logo) }) } } document.addEventListener('DOMContentLoaded', addLogo) })()</script> </div> ## Introdução - Na aula anterior vimos como usar modelos de regressão em um contexto de séries temporias, mas nada foi dito sobre como fazer previsão `\(h\)` passos à frente. -- - Sabemos que, com os `\(\hat{\beta}s\)`, podemos obter os valores estimados `\(\hat{y}_t\)` ( `\(t = 1, \ldots, T\)`) através da equação `$$\hat{y}_t = \hat{\beta}_0 + \hat{\beta}_1 x_{1,t} + \cdots + \hat{\beta}_k x_{k,t}$$` -- - Mas, como fazer se estamos interessados em `\(\hat{y}_t\)` para `\(t > T\)`? --- class: inverse, right, middle # Ex-ante e Ex-post --- ## Ex-ante e Ex-post Quando trabalhamos com séries temporais é muito comum encontrarmos os termos _Previsão ex-ante_ e _Previsão ex-post_. Esses termos **não são a mesma coisa!**. -- .pull-left[ #### Previsão ex-ante - .red[Ex-ante: antes do evento] - Utilizando a informação disponível até o tempo `\(T\)`, fazer previsão para o tempo `\(T+h\)` (fazemos a previsão para `\(T+h\)` antes de `\(T+h\)` acontecer) ] -- .pull-right[ #### Previsão ex-post - .red[Ex-post: depois do evento] - Utilizando informação disponível até o tempo `\(T\)`, fazer "previsão" para o tempo `\(t\)` ( `\(t < T\)`). - Formalmente, previsões ex-post são também aquelas onde queremos fazer previsão para o tempo `\(T+h\)` mas já conhecemos (por adiantado) o valor das variáveis regressoras para os tempos `\(T+1, \cdots, T+h\)`. ] -- > Ex-ante são verdadeiras previsões enquanto ex-post são os valores estimados [(ver slide 24 da segunda aula de séries temporais)](https://ctruciosm.github.io/ACA-228/ACA228_ST_02?panelset5=autocovari%25C3%25A2ncias2&panelset6=gr%25C3%25A1fico-brasil2&panelset7=m%25C3%25A9dia2&panelset8=importando-dados2&panelset9=drift4#52) -- Estamos interessados em **previsões ex-ante**! -- --- ## Ex-ante e Ex-post Em geral, quando trabalhamos com modelos da forma `$$y_t = \beta_0 + \beta_1 x_{1,t} + \cdots + \beta_k x_{k,t} + u$$` nunca conhecemos os valores de `\(x_1, x_2, ..., x_k\)` no futuro, **exceto quando `\(x_i\)` é deterministico!.** -- Pense no modelo `$$y_t = \beta_0 + \beta_1 x_{1,t} + \cdots + \beta_k x_{k,t} + u$$` onde `\(x_1 = t\)`, `\(x_2 = t^2\)`, `\(x_3 = D_{Fevereiro}\)`, `\(x_4 = D_{Março}\)`, .... `\(x_k = D_{Dezembro}\)`. -- Nesse caso, no tempo `\(T\)`, sabemos quais serão os valores para `\(x_1, \ldots, x_k\)` no futuro. -- Assim, basta obter os `\(\hat{\beta}s\)` (utilizando a informação disponível até o tempo `\(T\)`), utilizar os valores futuros das variáveis explicativas ( `\(x_{1, T + h}, \ldots, x_{k, T + h}\)` ) e fazer a previsão!. --- ## Previsão com variáveis deterministicas. Utilizando o _dataset_ `aus_production` do pacote `fpp3`, faremos a previsão `\(h = 12\)` passos à frente da produção de cerveja ( `Beer` ) na Australia. -- .panelset[ .panel[.panel-name[Dados] ```r library(fpp3) beer <- aus_production %>% select(Quarter, Beer) %>% filter(year(Quarter) > 1992) glimpse(beer) ``` ``` ## Rows: 70 ## Columns: 2 ## $ Quarter <qtr> 1993 Q1, 1993 Q2, 1993 Q3, 1993 Q4, 1994 Q1, 1994 Q2, 1994 Q3,… ## $ Beer <dbl> 433, 421, 410, 512, 449, 381, 423, 531, 426, 408, 416, 520, 40… ``` ] .panel[.panel-name[Modelo] ```r fit_beer <- beer %>% model(TSLM(Beer ~ trend() + season())) report(fit_beer) ``` ``` ## Series: Beer ## Model: TSLM ## ## Residuals: ## Min 1Q Median 3Q Max ## -42.1193 -7.7552 -0.5074 7.7665 22.3373 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 439.41993 3.87255 113.471 < 2e-16 *** ## trend() -0.31359 0.07303 -4.294 5.98e-05 *** ## season()year2 -34.79753 4.11473 -8.457 4.51e-12 *** ## season()year3 -17.56209 4.17414 -4.207 8.09e-05 *** ## season()year4 71.75149 4.17478 17.187 < 2e-16 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 12.34 on 65 degrees of freedom ## Multiple R-squared: 0.9213, Adjusted R-squared: 0.9164 ## F-statistic: 190.1 on 4 and 65 DF, p-value: < 2.22e-16 ``` ] .panel[.panel-name[Previsão] ```r fore_beer <- fit_beer %>% forecast(h = 12) fore_beer %>% autoplot(beer) ``` ] .panel[.panel-name[Gráfico] <!-- --> ] ] --- ## Previsão com variáveis deterministicas. No exemplo anterior, vimos que fazer previsão quando as variáveis explicativas são determinísticas resume-se a: * Estimar os `\(\hat{\beta}s\)`, * Utilizar os valores das variáveis explicativas ( `\(x_i\)` ) no futuro (como as variáveis são determinísticas sempre temos esses valores!), * Utilizar o modelo e obter `\(\hat{y}_t\)` para `\(t > T\)`. -- Contudo, **muito raramente** nosso modelo terá **apenas** variáveis determinísticas!. Na prática, o modelo terá variaveis explicativas `\(x_{k+1}, \ldots, x_{k+p}\)` cujos valores no tempo `\(T+h\)` não são conhecidos no tempo `\(T\)` 😨. -- Nestes casos, uma abordagem interessante e fazer previsão para diferentes cenários! --- class: inverse, right, middle # Além das variáveis determinísticas --- ## Previsão baseada em cenários Assumimos diferentes cenários para as variáveis explicativas no modelo: * Se o IPCA aumetar, em média 0.8% nos próximos meses, o volume de vendas nas festas de final de ano será de... * Se até final do ano o PIB aumentar em x%, a previsão da taxa de desempregados no Brasil será de ..... * Se o número de vacinados contra a COVID-19 no Brasil aumentar em x%, a receita com turismo interno no Brasil será de .... -- Em todos os casos temos apenas cenários, não há garantia que isso acontecerá mas, se acotecer, temos um valor esperado de como irá se comportar o fenômeno de interesse ao longo do tempo. -- É possível incluir esta informação por cenários no **R** --- ## Previsão baseada em cenários .panelset[ .panel[.panel-name[Código] ```r # Estimando o modelo modelo <- us_change %>% model(lm = TSLM(Consumption ~ Income + Savings + Unemployment)) # Criando os cenários cenarios <- scenarios( caso1 = new_data(us_change, 4) %>% # pega o dataset e cria 4 novas observacoes mutate(Income = c(1, 1.1, 1.2, 1.3), # Criando cenário para Income Savings = c(0.5, 0.52, 0.54, 0.56), # Criando cenário para Savings Unemployment = c(0, 0.05, 0.10, 0.15)), # Criando cenário para Unemployment caso2 = new_data(us_change, 4) %>% # pega o dataset e cria 4 novas observacoes mutate(Income= -c(1, 1.1, 1.2, 1.3), # Criando cenário para Income Savings = -c(0.5, 0.52, 0.54, 0.56), # Criando cenário para Savings Unemployment= -c(0, 0.05, 0.10, 0.15))) # Criando cenário para Unemployment # Fazendo as previsões fc <- forecast(modelo, new_data = cenarios) # Fazendo o gráfico us_change %>% autoplot(Consumption) + autolayer(fc) + labs(title = "US consumption", y = "Variação percetual") ``` ] .panel[.panel-name[Gráfico] <!-- --> ] ] --- ## Previsão baseada em cenários O que foi feito? `$$\widehat{\text{Consumption}}_{T+h} = \hat{\beta}_0 + \hat{\beta}_1 \text{Income}_{T+h}+ \hat{\beta}_2 \text{Savings}_{T+h} + \hat{\beta}_3 \text{Unemployment}_{T+h}$$` -- ```r coef(modelo) ``` ``` ## # A tibble: 4 × 6 ## .model term estimate std.error statistic p.value ## <chr> <chr> <dbl> <dbl> <dbl> <dbl> ## 1 lm (Intercept) 0.266 0.0341 7.81 3.57e-13 ## 2 lm Income 0.757 0.0396 19.1 1.91e-46 ## 3 lm Savings -0.0537 0.00292 -18.4 2.55e-44 ## 4 lm Unemployment -0.313 0.0678 -4.62 7.06e- 6 ``` -- `$$\widehat{\text{Consumption}}_{T+h} = 0.266 + 0.757 \text{Income}_{T+h} -0.0537 \text{Savings}_{T+h} -0.313 \text{Unemployment}_{T+h}$$` -- Quando construimos cenários, estamos definindo valores hipotéticos para os diferentes valores de `\(\text{Income}_{T+h}\)`, `\(\text{Savings}_{T+h}\)` e `\(\text{Unemployment}_{T+h}\)`. Assim, basta substituir esse valores na Equação e pronto!. --- class: inverse, right, middle # Não lineariedades --- ## Não lineariedades Sabemos que existem várias formas de incluir não lineariedades nos modelos de regressão: * `\(\log()\)` * Incluir variáveis ao quadrado (ou cubo) * Efeitos de interação -- > Todas essas técnicas continuam sendo válidas quando trabalhamos com modelos de regressão em um contexto de séries temporais. **Mas existem também outras formas de lidar com a não lineariedade.** -- Em geral, queremos modelos da forma `$$y = f(x) + u$$` -- .pull-left[ Uma alternativa é fazer: * `\(x_1 = x\)` * `\(x_2 = \text{ifelse}(x >= c_1, x-c_1, 0)\)` * `\(\cdots\)` * `\(x_k = \text{ifelse}(x >= c_{k-1}, x-c_{k-1}, 0)\)` ] -- .pull-right[ onde os pontos `\(c_1, c_2, \ldots, c_{k-1}\)` são chamados nós (knots). Um modelo de regressão dessa forma é chamado de regressão por _splines_. Desvantagem: Temos que escolher os nós! ] --- ## Não lineariedades .panelset[ .panel[.panel-name[Dataset] O _dataset_ `boston_marathon` do pacote `fpp3` contém informações sobre o tempo (em segundos) dos ganhadores da maratona ao longo dos anos de 5 categorias diferentes. ```r glimpse(boston_marathon) ``` ``` ## Rows: 265 ## Columns: 5 ## Key: Event [5] ## $ Event <fct> Men's open division, Men's open division, Men's open division… ## $ Year <int> 1897, 1898, 1899, 1900, 1901, 1902, 1903, 1904, 1905, 1906, 1… ## $ Champion <chr> "John J. McDermott", "Ronald J. MacDonald", "Lawrence Brignol… ## $ Country <chr> "United States", "Canada", "United States", "Canada", "Canada… ## $ Time <drtn> 10510 secs, 9720 secs, 10478 secs, 9584 secs, 8963 secs, 979… ``` ```r boston_men <- boston_marathon %>% filter(Event == "Men's open division") %>% mutate(Minutos = as.numeric(Time)/60) %>% select(Year, Minutos) ``` ] .panel[.panel-name[EDA] ```r ggplot(data = boston_men) + geom_line(aes(x = Year, y = Minutos)) + ylab("Minutos") + xlab("Ano") ``` <!-- --> **Obs:** O percurso da maratona foi modificado em 1924 (de 24.5 milhas para 26.2 milhas), consideraremos somente dados de 1924 em diante. ] .panel[.panel-name[EDA2] ```r boston_men <- boston_men %>% filter(Year >= 1924) ggplot(data = boston_men) + geom_line(aes(x = Year, y = Minutos)) + ylab("Minutos") + xlab("Ano") ``` <!-- --> ] .panel[.panel-name[Código] ```r modelos <- boston_men %>% model(linear = TSLM(Minutos ~ trend()), exponencial = TSLM(log(Minutos) ~ trend()), spline = TSLM(Minutos ~ trend(knots = c(1950, 1980)))) previsoes <- forecast(modelos, h = 12) ``` ```r boston_men %>% autoplot(Minutos) + geom_line(data = fitted(modelos), aes(y = .fitted, colour = .model)) + autolayer(previsoes) + labs(y = "Minutos", x = "Ano") ``` ] .panel[.panel-name[Gráfico] 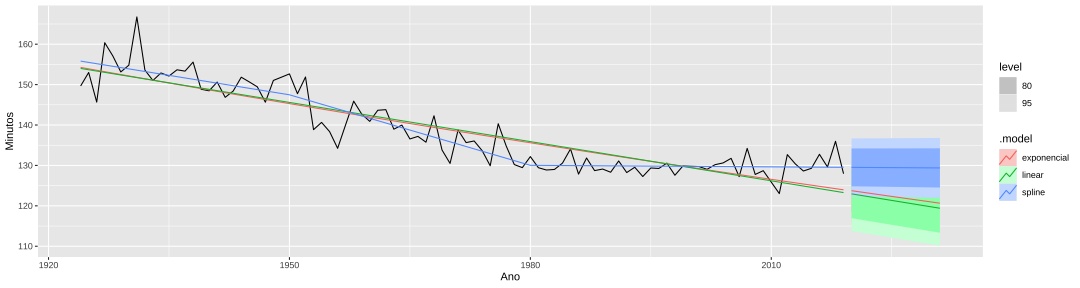<!-- --> ] ] --- ## Observações No modelo `$$y_t = \beta_0 + \beta_1 x_{1,t} + \cdots + \beta_k x_{k,t} + u,$$` as variáveis explicativas `\(x_{1}, x_{2}, \ldots, x_k\)` podem **também ser variáveis desafadas** (tanto da propria variável dependente quanto de outras variaveis explicativas!). -- Quando trabalhamos com um modelo com splines, podemos passar no argumento `knots` tanto as posições exatas dos nós, quanto o número de nós. Nesse último caso, a posição do nó será calculada automaticamente. -- > Procedimentos automáticos ajudam, mas não estão isentos de erro. --- ## Case Utilize o _dataset_ `aus_production` do pacote `fpp3` e construa modelos para a série temporal do `Tobacco` (Tabaco) e faça a previsão para os próximos 4 trimestres. 0. Faça um gráfico da série temporal. 1. Faça um modelo para `Tobacco` que inclua a tendência e a sazonalidade 2. Faça um modelo para `\(\log(Tabaco)\)` que inclua a tendência e a sazonalidade 3. Faça um modelo para `\(\log(Tabaco)\)` que inclua a tendência, tendência ao quadrado e sazonalidade 4. Faça um modelo para `\(\log(Tabaco)\)` que inclua a tendência (através de regressão por splines) e sazonalidade. Idenfifique você mesmo o número de nós. 5. Para cada um dos modelos criados, faça uma análise do diagnóstico e verifique quais modelos capturam a dinâmica dos dados (ou seja, verifique se os modelos passam pelo diagnóstico de forma satisfatória). 6. Faça previsões 4 passos à frente (e faça o gráfico correspondente). --- # Exercío Utilize o _dataset_ `aus_production` do pacote `fpp3` e construa modelos para a série temporal do `Beer` (Cerveja) e faça a previsão para os próximos 12 trimestres. 0. Faça um gráfico da série temporal. 1. Faça um modelo para `Beer` que inclua a tendência e a sazonalidade 2. Faça um modelo para `\(\log(Beer)\)` que inclua a tendência e a sazonalidade 3. Faça um modelo para `\(\log(Beer)\)` que inclua a tendência, tendência ao quadrado e sazonalidade 4. Faça um modelo para `\(\log(Beer)\)` que inclua a tendência (através de regressão por splines) e sazonalidade. Idenfifique você mesmo o número de nós. 5. Para cada um dos modelos criados, faça uma análise do diagnóstico e verifique quais modelos capturam a dinâmica dos dados (ou seja, verifique se os modelos passam pelo diagnóstico de forma satisfatória). 6. Faça previsões 4 passos à frente (e faça o gráfico correspondente). > Entregar pelo Google Class até antes da próxima aula. --- ### Referências - [Hyndman, R.J., & Athanasopoulos, G. (2021). Forecasting: principles and practice, 3rd edition, OTexts: Melbourne, Australia. OTexts.com/fpp3.](https://otexts.com/fpp3/). Chapter 7.6--7.7.